
数据分析师肯定每天都被各种各样的数据数据报表搞得焦头烂额,老板的,运营的、产品的等等。而且大部分报表都是重复性的工作,这篇文章就是帮助大家如何用Python来实现报表的自动发送,解...
 其他
其他
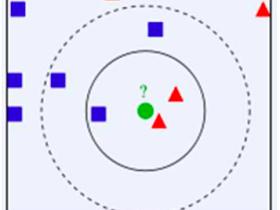
机器学习第二篇:详解KNN算法
本篇介绍机器学习众多算法里面最基础也是最"懒惰"的算法——KNN(k-nearest neighbor)。你知道为什么是最懒的吗?
 其他
其他
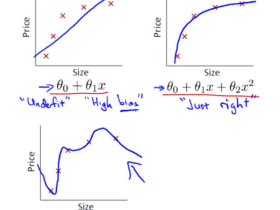
机器学习第一篇:开篇
统计学习的作用是对数据进行预测与分析,特别是对未知数据进行预测与分析,而对数据的预测与分析是通过构建概率统计模型来实现的。所以统计学习的目的是学习什么样的模型和如何学习模型,来让模...
 其他
其他
利用深度学习建立流失模型
失去一个老用户会带来巨大的损失,大概需要公司拉新10个新用户才能予以弥补。如何预测客户即将流失,让公司采取合适的挽回措施,是每个公司都要关注的重点问题。
 其他
其他
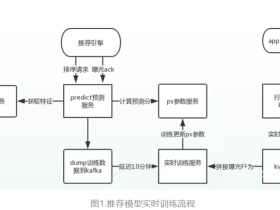
如何构建一个信息流推荐排序系统
推荐排序在一个推荐系统当中的重要性毋庸赘言,本文主要结合本人实际工作,跟大家探讨一下构建一个信息流推荐排序系统值得思考的一些问题。
 其他
其他
爬取了中国的米其林餐厅数据之后..
首版北京米其林指南在 2019 年 11 月 28 日 发布了,但却引起了不小的争议。不少北京网友认为在家门口都不会去的餐厅竟然被评为米其林?这是翻车指南吗?
 其他
其他
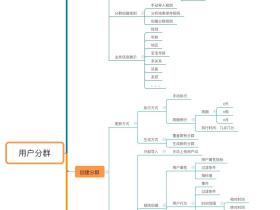
用户行为分析工具之——用户分群
最近正好准备做用户分群的工作,所以准备和大家介绍下数据产品中的数用户分群功能。分群是依据用户的属性特征和行为特征将用户群体进行分类,对其进行观察和分析的方式。
 其他
其他
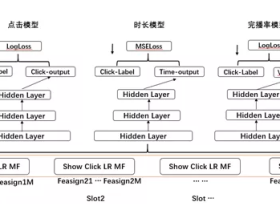
推荐精排模型之多目标模型
做推荐算法肯定绕不开多目标,点击率模型、时长模型和完播率模型是大部分信息流产品推荐算法团队都会尝试去做的模型。单独优化点击率模型容易推出来标题党,单独优化时长模型可能推出来的都是长...
 Python
Python
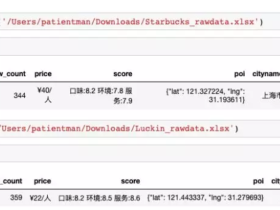
数说咖啡 | Python 分析瑞幸与星巴克
本文通过 Python 分析瑞幸和星巴克之间的数据,通过地理分布、价格、评分、评价等维度,结合两者的产品,分析一下基本现状:瑞幸在大众眼中的口碑是怎么样的?星巴克是否有可能会被颠覆...
 其他
其他
撇开虚荣指标,如何策划一场成功的拉新活动?
拉新活动的终极目标是转化,并非拉新人数的美丽数值。每一家追求数据驱动的企业,一味沉浸在单调的突增指标并非依靠数据驱动决策,而是在数据的泥沙中挣扎。
评论