
客户流失分析
失去一个老用户会带来巨大的损失,大概需要公司拉新10个新用户才能予以弥补。如何预测客户即将流失,让公司采取合适的挽回措施,是每个公司都要关注的重点问题。
目标
利用类神经网络构建用户流失分析模型,以预测用户是否有流失的可能。
工具
Jupyter Notebook :一个对于数据分析师来说特别合适的Python编辑器,强烈推荐大家去使用。
Python:在机器学习时代,Python是最受欢迎的机器学习语言。有很多机器学习的库,可以方便高效的去实现机器学习。
主要用到的Python包
pandas:是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包。能很方便的进行各种数据清洗。是每个数据分析师必学的Python包之一。
sklearn:是机器学习中一个常用的第三方包,里面对一些常用那个的机器学习方法进行了封装,使得大家能够更加简单的使用机器学习的方法。本文主要用这个包进行训练数据集和测试数据集的拆分以及数据尺度的标准化。
Keras:是一个高层神经网络API,Keras由纯Python编写而成并基Tensorflow、Theano以及CNTK后端。本文是基于
Tensorflow后端构建神经网络模型。Tensorflow是谷歌开发的一个开源的人工智能库。
接下来我们真正进入实战部分:
1.读取用户流失测试数据
#载入pandas包来读取csv格式的数据集import pandas as pd#把 csv格式的数据集导入到DataFrame对象中df = pd.read_csv("C:/Users/36540/Desktop/lossertest.csv", header = 0)df.head()

我们首先使用pandas包把csv格式的数据集导入DataFrame对象中,大概介绍下数据集的对象,从左到右分别是,用户ID、国家、注册时间、B类用户标记、最近登录时间、购买次数、购买金额、流失标记。
2.数据清洗
我们需要把所有的数据转化为数值型的数据,且没有缺失值。
#把totalPaiedAmount列也就是用户付款金额的缺失值替换为0df["totalPaiedAmount"] = df["totalPaiedAmount"].fillna(0)df["totalBuyCount"] = df["totalBuyCount"].fillna(0)
根据业务逻辑,首先把用户付款次数和付款金额的缺失值替换为0。
#利用pandas中的to_datetime函数把字符串的日期变为时间序列df["registrationTime"] = pd.to_datetime(df["registrationTime"], format="%Y-%m-%d %H:%M:%S")df["registrationTime"]
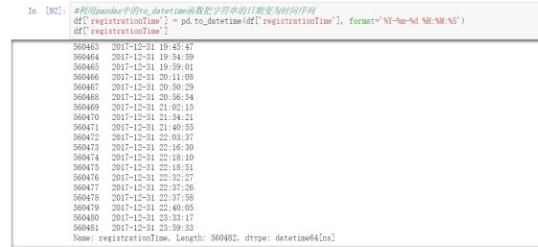
直接导入的pandas的数据是字符串格式的时间,我们需要将数据转化为时间序列格式。这里用到pandas自带的to_datetime函数,可以方便快速的把字符串转化为时间序列。
#同理最近登录时间也转化为实践序列df["lastLoginTime"] = pd.to_datetime(df["lastLoginTime"], format="%Y-%m-%d %H:%M:%S") df["lastLoginTime"]
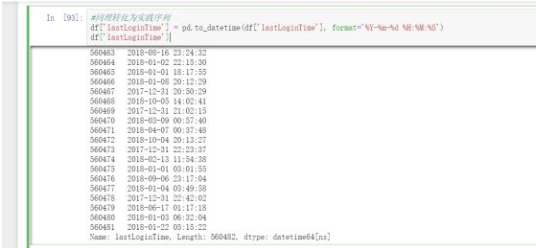
根据业务逻辑需要把时间转化为距今的时间间隔。
import datetime#获取当前时间now_time = datetime.datetime.now()now_time

根据datetime包,获取当前的时间。
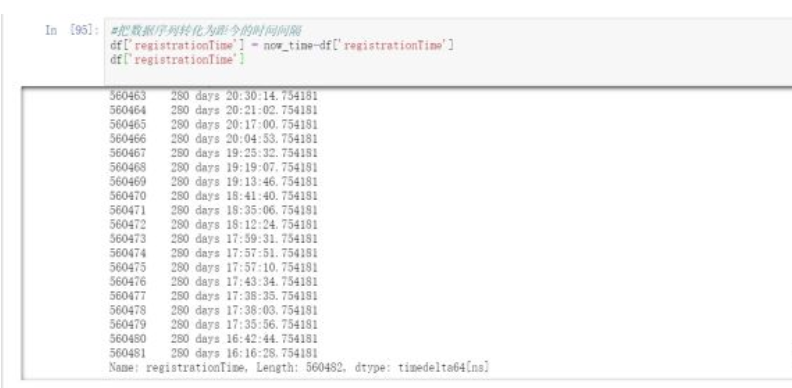
#把数据序列转化为距今的时间间隔df["registrationTime"] = now_time-df["registrationTime"]df["registrationTime"]
df["lastLoginTime"] = now_time-df["lastLoginTime"]df["registrationTime"]
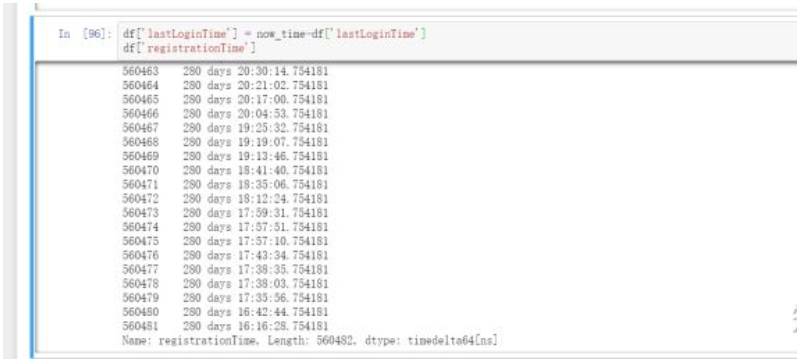
在DataFrame对象中,可以直接对2个时间格式数据进行相减,得到时间间隔。但是这个不是数值型,我们还需要进行处理。
先根据业务逻辑把最近登录时间缺失的部分替换为注册时间。
#把最近登录时间列的空值替换为同索引行注册时间列的值df.loc[df["lastLoginTime"].isnull(),"lastLoginTime"]=df[df["lastLoginTime"].isnull()]["registrationTime"]df["registrationTime"]
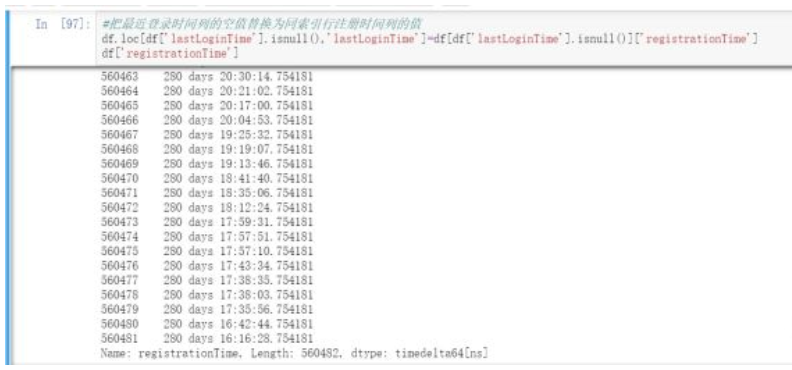
根据pandas中自带的isnull可以很方便的替换缺失值。
#因为数据量有点大,取前1w行数据测试下df = df.iloc[0:1000]#把时间间隔转化为数值型的天数j = 0for i in df["registrationTime"]: df = df.replace(df["registrationTime"][j],i.days) j += 1
建立一个for循环把所有的时间隔间转化为数值型的时间隔间天数,.days函数可以方便获取时间隔间的天数。经过我是实践发现,Python对于这个转化的处理速度很慢。所以我就取了前1000条数据进行测试处理。建议大家还是在mysql中直接用时间函数获取时间差天数,数据库中的处理速度快了很多。我50W+的数据只要10几秒就可以完成。
#不知道为什么这样操作就会报错,欢迎大家研究研究for i in range(0,df["registrationTime"]): df = df.replace(df["registrationTime"][i],df["registrationTime"][i].days)
我本来是这样编写for循环的,不知道为什么运行几条就报错。差了很多资料也没找到原因。也欢迎大家研究研究。找到原因可以评论或者私信我。
到这里数据清洗也就基本完成了,我来最后检查一遍,数据集是否还有缺失值。
#对数据集进检查,看看是否还有缺失值df[df.isnull().values==True]

可以发现,还有缺失值的列已经不存在了。接下来就把第一列对于结果无关的用户ID列删除。
#把第一列无用的用户ID列删除df = df.iloc[:,1:]
数据清洗步骤就全部完成了,我再来看看数据集现在的样子,来最终检查一遍处理结果。
df.head()df.info()


可以发现所有的数据都已经变成float64或者 int64,已经达到了我们处理的目的。
接下来把输入输出项确定下,前6列是输入的指标,最后一列流失标记是输出项。
#把输入输出项确定下y = df.iloc[:,-1]x = df.iloc[:,:-1]x.shapey.shape
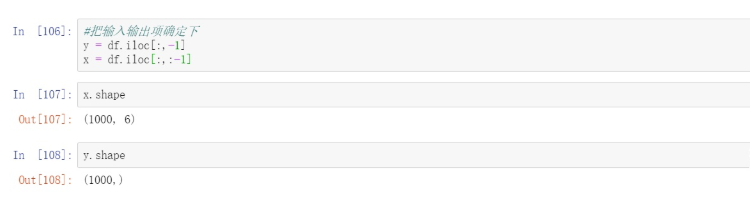
可以发现输入项是1000行数据,6列。输出是1000行数,1列。
区分训练与测试数据集
#sklearn把数据集拆分成训练集和测试集from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.33, random_state = 123)x_train.shapey_train.shapex_test.shapey_test.shape
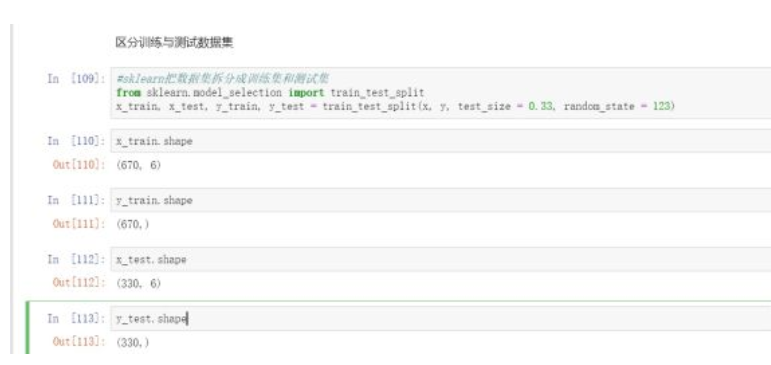
利用sklearn包中的train_test_split函数可以很方便的区分训练集和测试集。test_size代表测试的大小,0.33也就是训练集和测试集的比为3:1,random_state代表区分的随机标准,这个如果不确定的话,每次拆分的结果也就是不一样,这属性是为了数据可以复现。大家不要使用123,可以随意填写。从上图可以看到,数据已经被拆分为670行和330行2个数据集了。
尺度标准化
所有神经网络的输入层必须进行标准处理,因为不同列的大小是不一样,这样的话没法进行对比。所以需要对数据集进行标准化处理。
#使用sklearn把数据集进行尺度标准化from sklearn.preprocessing import StandardScalersc = StandardScaler()x_train = sc.fit_transform(x_train)x_test = sc.fit_transform(x_test)x_test
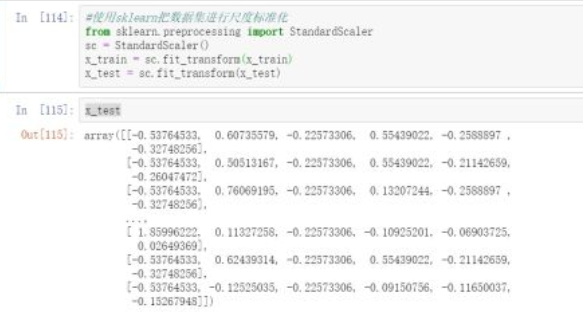
sklearn包中的StandardScaler函数可以方便对数据进行去均值和方差归一化处理。首先定义一个对象,sc = StandardScaler(),然后把数据集放进去就可以直接输出一个标准化完成的数据集。输出的数据集如上图所示。
训练ANN
#使用keras包搭建人工神经网络import keras#序贯(Sequential)模型包from keras.models import Sequential#神经网络层from keras.layers import Dense#优化器from keras.optimizers import SGD#创建一个空的神经网络模型classifier = Sequential()
我们利用keras包来交轻松的完成人工神经网络的搭建。首先载入一个序贯(Sequential)模型。序贯模型是多个网络层的线性堆叠,也就是"一条路走到黑"。可以通过向Sequential模型传递一个layer的list来构造该模型,也可以通过.add()方法一个个的将layer加入模型中。本文采用.add()方法将2层神经网络输入模型中。优化器的选择是SGD,因为本来数据量比较小,而且训练次数也不多,所以选择最贱简答的SGD。平时对于性能的有要求的可以使用Adam优化器。
#创建输入层classifier.add(Dense(units = 3, kernel_initializer = "uniform", activation = "relu", input_dim = 6))#创建输出层classifier.add(Dense(units = 1, kernel_initializer = "uniform", activation = "sig
将神经网络的输入输出层添加到模型中。
Dense就是常用的全连接层,所实现的运算是output = activation(dot(input, kernel)+bias)。
参数
units:大于0的整数,代表该层的输出维度。一般为输入项的一半,但是真正合适的值还是要经过多次训练才能得出。
activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)。本文用的relu和sigmoid。都是最基础的。
bias_initializer:偏置向量初始化方法,为预定义初始化方法名的字符串,或用于初始化偏置向量的初始化器。不同的层可能使用不同的关键字来传递初始化方法,一般来说指定初始化方法的关键字。本文用的Glorot均匀分布初始化方法,又成Xavier均匀初始化,参数从[-limit, limit]的均匀分布产生,其中limit为sqrt(6 / (fan_in + fan_out))。fan_in为权值张量的输入单元数,fan_out是权重张量的输出单元数。
形如(batch_size, ..., input_dim)的nD张量,最常见的情况为(batch_size, input_dim)的2D张量。
classifier.compile(loss="binary_crossentropy", optimizer=SGD(), metrics=["accuracy"])history = classifier.fit(x_train, y_train, batch_size=10, epochs=100, validation_data=(x_test, y_test))
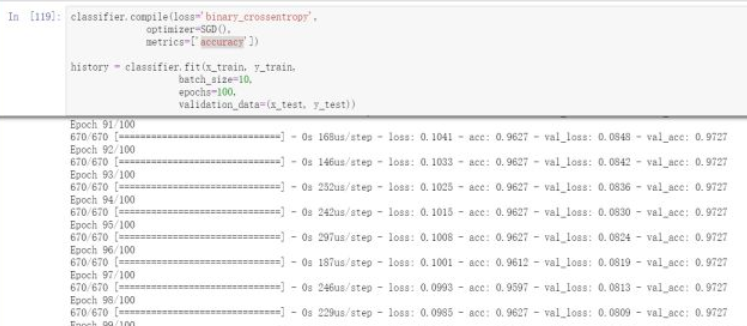
然后设置模型的损失函数loss为binary_crossentropy(亦称作对数损失,logloss)。目标函数,或称损失函数,是编译一个模型必须的两个参数之一。
优化器选择了SGD,也就是最简单基础的一个优化器。
性能评估模块提供了一系列用于模型性能评估的函数,这些函数在模型编译时由metrics关键字设置。性能评估函数类似与目标函数, 只不过该性能的评估结果讲不会用于训练。
Keras以Numpy数组作为输入数据和标签的数据类型。训练模型一般使用fit函数。把训练集输入,然后batch_size选择每次训练数量,epochs是训练的次数。validation_data验证的数据集。
最后看到上面的训练结果loss为0.0973,acc为0.9612。这个结果已经是一个比较好的结果。
评估模型
y_pred = classifier.predict(x_test)y_pred
利用predict把测试集的结果输出来,输出的是0-1的概率值,我可以假设大于0.5为流失,把结果转化为0和1和结果。0.5只是一个大概的值,最合适的话还是要自己去测试得出。
y_pred = (y_pred > 0.5)y_pred.shapey_pred.flatten().astype(int)
最终把结果转化为0和1和,通过flatten吧数据转化为一维的数据,并且利用astype(int)把True和False转化为0和1。
from sklearn.metrics import accuracy_scoreaccuracy_score(y_test, y_pred )

根据accuracy_score直接得到结果,可以发现结果为0.9727,这个数据是好的结果。准确率有97%。但是我们仅仅看着数据是不够的,因为假如1000个人里只有50个流失,那我全部乱猜为不流失,这样准确率也有95%。所以要再看看流失和非流失的准确率。
from sklearn.metrics import confusion_matrixcm = confusion_matrix(y_test, y_pred )cm
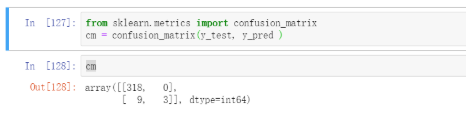
可以发现非流失用户全部猜对,但是流失的只对了3个。说明模型对于非流失用户的准确性还需要提高。结果看看更加详细的结果。
from sklearn.metrics import classification_reportprint(classification_report(y_test, y_pred))
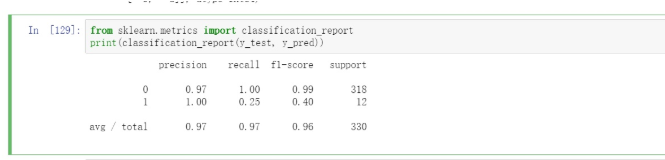
利用classification_report函数直接获取结果。我们观察结果可以发现,流失用户的f1-score只有0.40.这是比较小的值,还有很大的提高空间。虽然全部用户的准确率97%,看上去很美好,实际一拆分的结果并不如人意。当然这里只是一个测试的结果,后续我们可以增加输入层的数据指标,增加训练的次数去提高准确率。
End.爱数据网专栏作者:阿坤老师专栏名称:数据杂谈专栏简介:分享数据分析和数据产品的各种感悟知乎专栏:数据产品随想
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论