
本篇介绍机器学习众多算法里面最基础也是最"懒惰"的算法——KNN(k-nearest neighbor)。你知道为什么是最懒的吗?
01|算法简介:
KNN是英文k-nearest neighbor的缩写,表示K个最接近的点。该算法常用来解决分类问题,具体的算法原理就是先找到与待分类值A距离最近的K个值,然后判断这K个值中大部分都属于哪一类,那么待分类值A就属于哪一类。
这其实和我们生活中对人的评价方式一致,你想知道一个人是什么样的人,你只需要找到跟他关系最近(好)的K个人,然后看这K个人都是什么人,就可以判断出他是什么样的人了。
02|算法三要素:
通过该算法的原理,我们可以把该算法分解为3部分,第一部分就是要决定K值,也就是要找他周围的几个值;第二部分是距离的计算,即找出距离他最近的K个值;第三部分是分类规则的确定,就是以哪种标准去评判他是哪一类。
1、K值的选取
K值的选取将会对KNN算法的结果产生重大的影响,下面通过一个简单的例子说明一下:如下图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
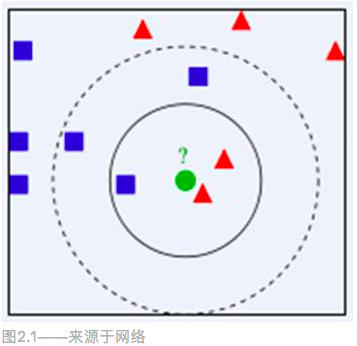
大家可以看到k值的选取会直接影响到评测结果,如果k值选取过大,相当于用较大领域中的训练实例进行预测,这样看起来是觉得数据越多可能越准确,但实际上并不然,如果要想获得较多个k值,这样你就需要把距离进一步扩大,预测准确率自然会下降。
还是拿那个我们判断一个人是什么样子的人为例,如果选择较大的k值比如一个班的人,然后根据这一个班所有人的情况去预测这个班里面的某一个人是什么样子的,这样很明显是不准确的。
如果k值选取过小,则这些很有可能是特例,也会影响预测的结果。
过大也不好,过小也不好,那么我们该怎么办?最笨的也是最有效的方法就是试,我们在上一篇推文说模型选择有一种方法是交叉验证,机器学习开篇。我们在k值选择的时候也可以用交叉验证这种方法。
2、距离的度量
我们在评判人与人之间的关系远近的时候没有一个量化的关系,只会用一些词去形容两个人之间关系的远近,比如闺蜜(发小)>舍友 > 同学。
但在统计学习中我们评判两者的远近关系的时候是有一个可以量化的东西,这里我们用的是欧式距离。
欧式距离又称欧几里得距离,是指在m维空间中,两个点之间的真实距离。
- 二维平面上两点a(x1,y1)与b(x2,y2)间的欧氏距离:
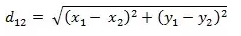
- 三维空间两点a(x1,y1,z1)与b(x2,y2,z2)间的欧氏距离:
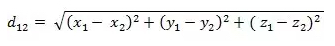
- 两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的欧氏距离:
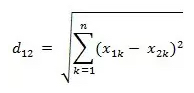
也可以用表示成向量运算的形式:
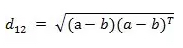
当然我们还可以使用其他距离来度量两者的远近关系,比如曼哈顿距离(是不是觉得名字很高大上),更多详情点击:https://wenku.baidu.com/view/ebde5d0e763231126edb1113.html
3、分类规则的确定:
这里我们目前就使用多数表决的分类规则,即这距离最近的k个值中的大部分值的类别就是待预测值的类别。
03|算法步骤:
- 收集数据:找寻待训练的文本数据。
- 准备数据:利用python解析文本文件。
- 分析数据:对数据进行一些统计分析,有个基本的认识。
- 训练算法:KNN没有这一步,这也是为何被称为最懒算法的原因。
- 测试算法:将提供的数据利用交叉验证的方式进行算法的测试。
- 使用算法:将测试得到的准确率较高的算法直接应用到实际中。
04|利用python对未知电影进行分类:
1、背景:
假设爱情电影和动作电影之间的区别可以用打斗次数和接吻次数这两个特征来决定,下面提供了一些电影的类别以及其对应的接吻和打斗次数(训练数据集)。
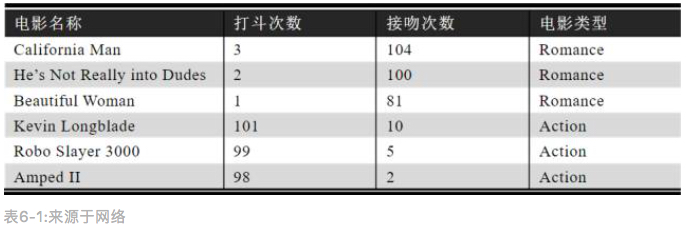
现在有一电影A,已知其打斗次数为18,接吻次数为90,需要利用knn算法去预测该电影属于哪一类别。
2、准备数据

3、分析数据

4、测试算法
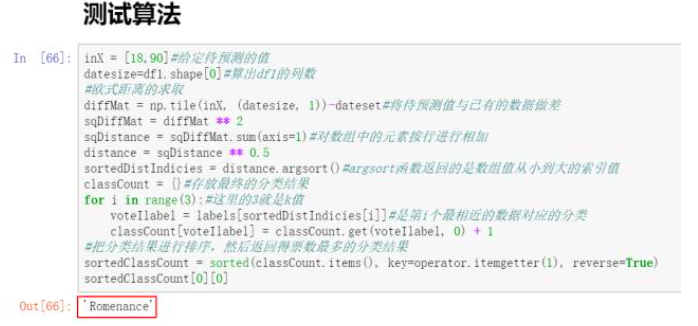
通过测试最后得出,如果一部电影中含有18次打斗次数,90次接吻次数,那么可以判定为该电影是爱情片。
5、应用算法:
通过修改inX的值,就可以直接得出该电影的类型。
05|最后:
上面python实现过程中涉及的一些知识点:
- pandas数据转换成numpy,df.matrix()
- matplotlib中文显示乱码问题
- 列表生成式
- np.tile()函数
- np.sum()函数
- np.argsort()函数
- dict.get()方法
- dict.items()方法
- operator.itemgetter()函数
End.
爱数据网专栏作者:张俊红
作者介绍:一个数据科学路上的学习者、实践者、传播者
个人公众号:俊红的数据分析之路
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论