
背景
做推荐算法肯定绕不开多目标,点击率模型、时长模型和完播率模型是大部分信息流产品推荐算法团队都会尝试去做的模型。单独优化点击率模型容易推出来标题党,单独优化时长模型可能推出来的都是长视频或长文章,单独优化完播率模型可能短视频短图文就容易被推出来,所以多目标就应运而生。
刚开始做多目标的时候,一般针对每一个目标都单独训练一个模型,单独部署一套预估服务,然后将多个目标的预估分融合后排序。这样能够比较好的解决推荐过程当中的一些负面case,在各个指标之间达到一个平衡,提升用户留存。但是同时维护多个模型成本比较高,首先是硬件上,需要多倍的训练、PS、和预估机器,这是一笔不小的开销(一个月保守百万左右吧),然后是各个目标的迭代不好协同,比如新上了一批好用的特征,多个目标都需要重新训练实验和上线,然后就是同时维护多个目标对相关人员的精力也是一个比较大的消耗。
可以通过LTR(Learning To Rank)方法优化Item的重要性来解决多目标打算解决的问题,但是由于工程实现、推荐框架调整等方面的困难,相关方法在实际应用中比较少。现在主流的还是通过多任务学习训练一个模型预估多个目标,然后线上融合多个目标进行排序。多个目标融合的时候很多公司都是加权融合,比如更看重时长可能时长的权重就大些,更看重分享,分享的权重就大些,加权系数一般通过AB实验调整然后固定,这样带来的问题就是,当模型不断迭代的时候,这个系数可能就不合适了,经常会出现的问题是加权系数影响模型的迭代效率。具体多个目标怎么融合,这个里面机制发挥的空间比较大,这里不再赘述。
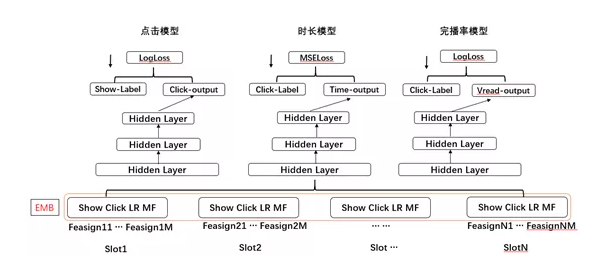
共享Embedding 多塔结构
底层共享embedding,三个目标三个独立的塔,NN层各个目标完全独立的。点击模型使用全量有效曝光样本进行训练,时长模型和完播率模型使用点击样本进行训练。经过多次迭代,这个结构上线后大盘PV和时长都有一定提升,每一个目标单独来看,点击指标基本微降,时长和完播率指标提升较多。
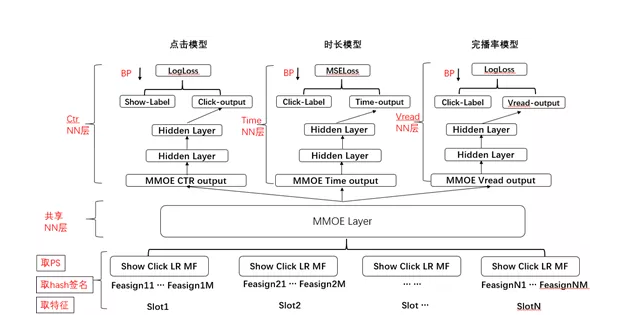
MMOE
借鉴Google提出的MMOE,升级多目标模型,模型结构如下:Embedding层还是共享的,MMOE层对应每个目标分别给一个输出,然后每个目标各自一个塔。MMOE模型相对Share-Bottom三塔结构,离线点击指标有一定提升,时长和完播率基本持平,但是模型复杂度增大较多,训练较慢。
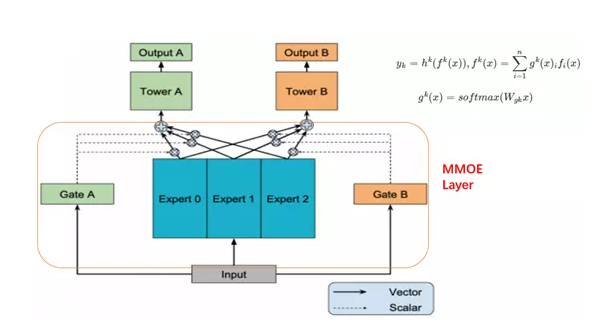
MMOE结构如下:Expert是一个神经网络,Expert个数根据训练和预估性能做权衡,和任务数保持一致也可以。Gate是一个Softmax函数,个数与任务数一致,每个Gate的输出个数与Expert个数一致。
其它尝试
尝试过在embedding与各个目标独立的NN之间加入共享的NN层,比如把上面MMOElayer换成普通的NN层,这样训练发现完播率指标有提升,但是时长和点击率指标下降,我们撤掉共享NN层之后,各个目标都取得了相对于单独训练的base模型的提升,但是完播和时长模型提升较大。
分析原因,撤掉共享NN后各个指标提升,应该是由于每个单独的NN网络模型复杂度不够导致。同时,时长和有效阅读指标提升较多,是由于训练点击模型使用的是全量曝光样本,而时长和完播率模型使用的是点击样本,但是线上serving的时候时长和完播率模型都是面对全量样本做预估的,训练和预估时样本分布不一致可能导致预估偏差较大,但是在多任务学习过当中,点击率学习好的EMB是可以共享给时长和完播率完成迁移学习的,可能是EMB共享扩大了时长和完播率模型的学习空间,缓解了训练和预估样本分布差异。
完播率和点击模型两者相关性较大,所以在使用共享NN层时在其它指标下降的情况下,其指标也能提升。前期点击模型的线上指标下降比较多的,整体也没有收益,考虑到时长和完播率都是对点击样本进行学习,这可能对点击模型的影响有点大了,于是稍微调大了点击模型的学习率,加上撤掉共享NN层,整体指标基本就由负转正了。
之前尝试加入过互动模型(点赞、评论、收藏、分享),但由于样本过于稀疏以及训练和Serving的效率问题,最终没有上线,后面有机会,还是值得尝试一下的。
样本空间不一致处理
三个目标的输入是一样的,都是全量有效曝光样本,但是在时长和完播率这两个塔,针对未点击样本,将其回传梯度置零,这样处理就相当于只使用点击样本在进行训练了。如何理解呢?训练其实就是一个梯度回传的过程,将未点击样本的梯度置零,相当于这部分样本的梯度未对网络参数的调整起到影响,但是由于Mini-Batch 梯度优化算法最终会用整体修正梯度除batch样本数量,所以在时长和完播率这两个塔里面除以的是Batch样本里面的点击样本数。
在点击时长完播率三目标训练当中,点击模型的EMB共享可以弥补时长和完播率模型未能学习未点击样本造成的训练和预估样本分布偏差问题,但是时长和完播率模型的更新却给点击率模型的样本造成了一定的扰动,相当于点击样本被多次训练了,从而造成点击模型点击样本和未点击样本的分布差异变大。通过增大点击率的学习率,相当于给点击模型加权了,这样可以减小由于时长和完播率更新造成的点击样本和未点击样本之间的差距。这样也确实给点击模型的指标带来了一定的提升。
正常来说,各个目标之间的Loss权重调整是不好把握的,当你对某个任务的loss加权的时候,不仅改变了当前任务的学习曲线,由于EMB共享,所以也会影响到其它任务,这种影响到底有利还是有弊呢,不知道,理论上也没有保障,只能说试试看了。有论文使用每个任务的不确定度(uncertainty)来辅助对loss进行加降权,可以尝试一下,还没有做相关的实验。
多目标的难点
也可以说是trick, 不同目标的训练样本不一致,比如点击模型和时长模型,所以上面就有谈到处理方法,那就是对只使用点击样本的任务将其未点击样本的回传梯度置0,同时在更新相关任务的NN参数的时候根据点击样本数做平均。
然后是学习率的调整,这个其实可以根据不同任务的loss下降曲线来相应调整,我是根据离线和在线指标来进行调整,但是调大还是调小呢,那就要对不同的学习任务有比较深刻的理解。点击任务的正负样本分布被时长和完播给带偏了,那么增大其学习率自然可以缓解这种情况,但是时长和完播率则不然,点击任务多出来的样本一般来说会给另外两个任务带来额外的信息增益。
可以优化的点
1)点击模型的输出可以作为时长和完播率模型的输入特征,但是这个处理对于Serving时使用多线程对多个目标进行并行预估不友好。
2)可以研究不同目标loss加权的方法,使得不同目标的梯度更新能够达到步调一致,整体的loss能够稳定的降低。
3)训练和预估支持的话,可以增大Expert的个数
4)MMOE里面的Gate结构,可以与每一个Expert做成一个self-attention的结构
End.爱数据网专栏作者:billlee专栏名称:推荐系统工业实践专栏简介:介绍工业界最前沿的推荐系统架构、模型及相关实战指南个人公众号:比尔的新世界
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论