
建议采用缺失值填补技术来解决。
在SPSS中,有两个菜单可以完成缺失填补。一个是【转换】菜单下的【替换缺失值】,另一个是【分析】菜单下的【缺失值分析】。
前者特点简单易行,后者特点是略专业复杂一些。多数情况下,我觉得使用【替换缺失值】即可满足需求。因此我在《SPSS从入门到实践提高》视频课程和本文中,主要介绍【替换缺失值】的方法。
一.案例数据
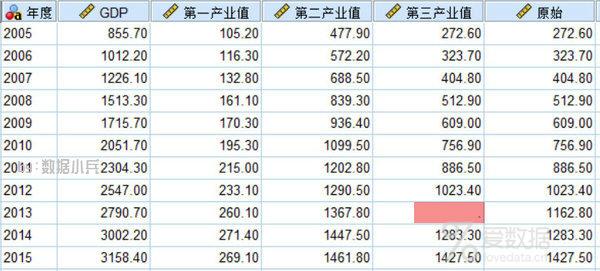
11年间的经济数据,其中2013年"第三产业值"数据缺失,右侧"原始"变量给出真实值,以便对照比较缺失填补的情况,即2013年"第三产业值"实为1162.8。
二.SPSS替换缺失值
菜单:【转换】→【替换缺失值】,对话框如下:
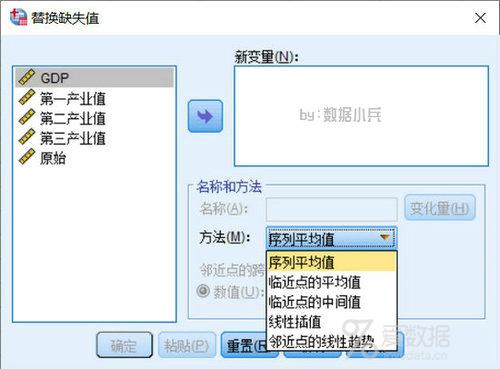
SPSS在此处提供5种缺失填补方法,它们分别是:
1.序列平均值
使用整个序列的平均值填补缺失值。
2.邻近点的平均值
使用有效周围值的平均值填补缺失值。邻近点的跨度为缺失值上下用于计算平均值的有效值个数。
3.邻近点的中位值
使用有效周围值的中位值填补缺失值。邻近点的跨度为缺失值上下用于计算中位值的有效值个数。
4.线性插值
使用线性插值替换缺失值。缺失值之前的最后一个有效值和之后的第一个有效值用来作为插值。如果序列中的第一个或最后一个个案具有缺失值,则不必替换,计算原理类似"临近点的平均值"。
5.该点的线性趋势
使用该点的线性趋势填补缺失值。现有序列在标度为从 1 到 n 的索引变量上回归,用预测值填补缺失值。简单理解为系统将采取线性拟合的方法确定替换值。其他变量作为自变量,缺失序列变量作为因变量,然后进行建模预测。
以上5种方法,大家知道就行,不要过分纠缠计算原理(没有必要费脑,选择相信SPSS)。特别说明,最常用的是前两个基于平均值的方法,简单易懂。
三.举例说明
我跳过第一个方法,文字描述即可说明了。"第三产业值"除2013年缺失外的10个数字,其平均值为750.06,即所谓"序列平均值",所以是用750.06作为2013年缺失数据之填补值。
举例看一下第2个方法:邻近点的平均值
我们这组数据是时间序列数据,大眼观察发现,"第三产业值"数据是逐年递增的,所以用整个序列的平均值来计算缺失值,会拉低真实情况,显然不好。努力一想,用临近1年的数据或临近2年的数据计算平均值就会更有效果,更切近真实值了。
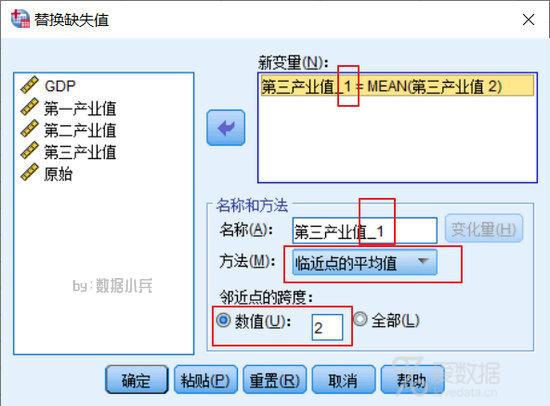
把存在缺失的"第三产业值"移入【新变量】框内,SPSS会自动创建一个新的变量,用于存放填补后的序列值,不是直接在原始变量上进行覆盖替换(以防后悔)。选择第2个方法:邻近点的平均值。
自动给出新变量的名称:第三产业值_1,用下划线带数字编号的形式和原始变量进行区分。此处数字1可理解为第1次填补。然后一定记住要点击一下右侧的【变化量】按钮让刚才的设置生效。
跨度,软件默跨度2,即缺失值前后各取2个数据,前2后2共四个数字取平均值,本例即886.5、1023.4、1283.3、1427.5,它们四个数据的平均值是1155.175。
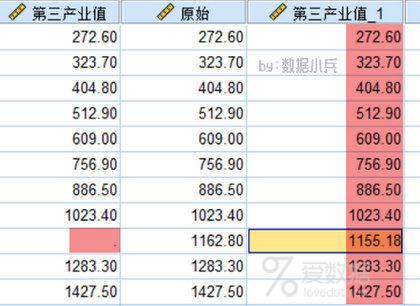
看结果吧。SPSS邻近点的平均值给出的结果是1155.18,一致。是不是很好理解呢。
再做第5个方法:该点的线性趋势,设置如下:
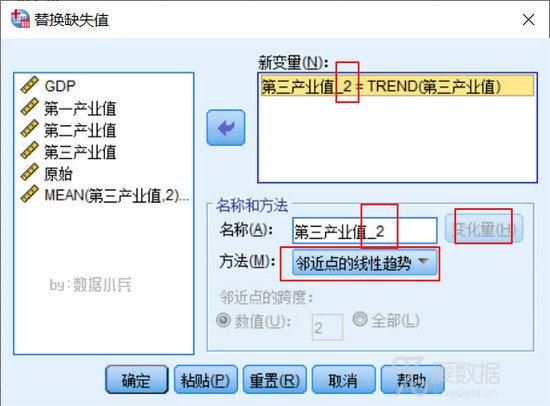
我们自己去做回归的话,有点麻烦,我建议不用纠结背后的原理了,反正就是回归建模然后预测,放心大胆的命令软件给出结果吧。

我们前后使用了第1、第2和第5三种方法,显然第2种方法所得到的1155.18是最逼近真实值1162.8的,这也就是为什么邻近点的平均值这个方法比较流行的缘故。一方面好理解,第二方面结果不会太差。
End.作者:数据小兵来源:博客本文均已和作者授权,如转载请与作者联系。
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论