
回归分析是对具有因果关系的影响因素(自变量)和预测对象(因变量)所进行的数理统计分析处理。只有当变量与因变量确实存在某种关系时,建立的回归方程才有意义。因此,作为自变量的因素与作为因变量的预测对象是否有关,相关程度如何,以及判断这种相关程度的把握性多大,就成为进行回归分析必须要解决的问题。进行相关分析,一般要求出相关关系,以相关系数的大小来判断自变量和因变量的相关的程度。
二、回归分析的目的
回归分析的目的大致可分为两种:
第一,"预测"。预测目标变量,求解目标变量y和说明变量(x1,x2,…)的方程。
y=a0+b1x1+b2x2+…+bkxk+误差(方程A)
把方程A叫做(多元)回归方程或者(多元)回归模型。a0是y截距,b1,b2,…,bk是回归系数。当k=l时,只有1个说明变量,叫做一元回归方程。根据最小平方法求解最小误差平方和,非求出y截距和回归系数。若求解回归方程.分別代入x1,x2,…xk的数值,预测y的值。
第二,"因子分析"。因子分析是根据回归分析结果,得出各个自变量对目标变量产生的影响,因此,需要求出各个自变量的影响程度。
希望初学者在阅读接下来的文章之前,首先学习一元回归分析、相关分析、多元回归分析、数量化理论I等知识。
根据最小平方法,使用Excel求解y=a+bx中的a和b。那么什么是最小平方法?
分别从散点图的各个数据标记点,做一条平行于y轴的平行线,相交于图中直线(如下图)
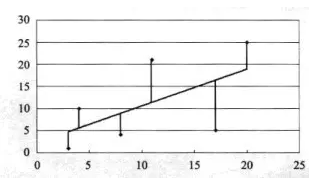
平行线的长度在统计学中叫做"误差"或者‘残差"。误差(残差)是指分析结果的运算值和实际值之间的差。接这,求平行线长度曲平方值。可以把平方值看做边长等于平行线长度的正方形面积(如下图)
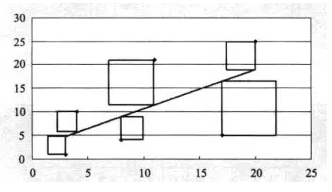
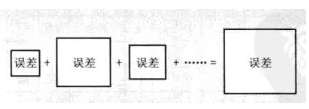
最后,求解所有正方形面积之和。确定使面积之和最小的a(截距)和b(回归系数)的值(如下图)。
使用Excel求解回归方程;"工具"→"数据分析"→"回归",具体操作步骤将在后面的文章中具体会说明。
线性回归的步骤不论是一元还是多元相同,步骤如下:
- 1、散点图判断变量关系(简单线性);
- 2、求相关系数及线性验证;
- 3、求回归系数,建立回归方程;
- 4、回归方程检验;
- 5、参数的区间估计;
- 6、预测;
一元线性回归操作和解释
摘要
一元线性回归可以说是数据分析中非常简单的一个知识点,有一点点统计、分析、建模经验的人都知道这个分析的含义,也会用各种工具来做这个分析。这里面想把这个分析背后的细节讲讲清楚,也就是后面的数学原理。
什么是一元线性回归
回归分析(Regression Analysis)是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。举个例子来说吧:
比方说有一个公司,每月的广告费用和销售额,如下表所示:

案例数据
如果我们把广告费和销售额画在二维坐标内,就能够得到一个散点图,如果想探索广告费和销售额的关系,就可以利用一元线性回归做出一条拟合直线:

拟合直线
这条线是怎么画出来的
对于一元线性回归来说,可以看成Y的值是随着X的值变化,每一个实际的X都会有一个实际的Y值,我们叫Y实际,那么我们就是要求出一条直线,每一个实际的X都会有一个直线预测的Y值,我们叫做Y预测,回归线使得每个Y的实际值与预测值之差的平方和最小,即(Y1实际-Y1预测)^2+(Y2实际-Y2预测)^2+ …… +(Yn实际-Yn预测)^2的和最小(这个和叫SSE,后面会具体讲)。
现在来实际求一下这条线:
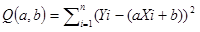
我们都知道直线在坐标系可以表示为Y=aX+b,所以(Y实际-Y预测)就可以写成(Y实际-(aX实际+b)),于是平方和可以写成a和b的函数。只需要求出让Q最小的a和b的值,那么回归线的也就求出来了。
简单插播一下函数最小值怎么求:
首先,一元函数最小值点的导数为零,比如说Y=X^2,X^2的导数是2X,令2X=0,求得X=0的时候,Y取最小值。
那么实质上二元函数也是一样可以类推。不妨把二元函数图象设想成一个曲面,最小值想象成一个凹陷,那么在这个凹陷底部,从任意方向上看,偏导数都是0。
因此,对于函数Q,分别对于a和b求偏导数,然后令偏导数等于0,就可以得到一个关于a和b的二元方程组,就可以求出a和b了。这个方法被称为最小二乘法。下面是具体的数学演算过程,不愿意看可以直接看后面的结论。
先把公式展开一下:
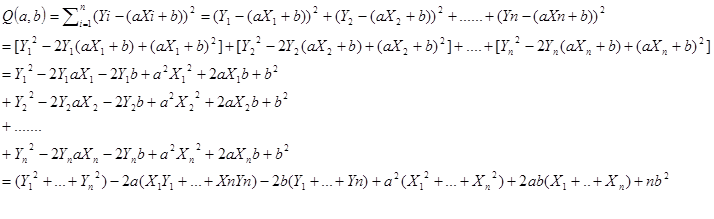
Q函数表达式展开
然后利用平均数,把上面式子中每个括号里的内容进一步化简。例如
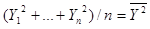
则:
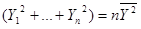
于是
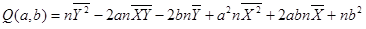
然后分别对Q求a的偏导数和b的偏导数,令偏导数等于0。

进一步化简,可以消掉2n,最后得到关于a,b的二元方程组为

关于a,b的 二元方程组
最后得出a和b的求解公式:
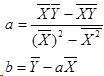
最小二乘法求出直线的斜率a和斜率b
有了这个公式,对于广告费和销售额的那个例子,我们就可以算出那条拟合直线具体是什么,分别求出公式中的各种平均数,然后带入即可,最后算出a=1.98,b=2.25
最终的回归拟合直线为Y=1.98X+2.25,利用回归直线可以做一些预测,比如如果投入广告费2万,那么预计销售额为6.2万
评价回归线拟合程度的好坏
我们画出的拟合直线只是一个近似,因为肯定很多的点都没有落在直线上,那么我们的直线拟合程度到底怎么样呢?在统计学中有一个术语叫做R^2(coefficient ofdetermination,中文叫判定系数、拟合优度,决定系数,系统不能上标,这里是R^2是"R的平方"),用来判断回归方程的拟合程度。
首先要明确一下如下几个概念:
总偏差平方和(又称总平方和,SST,Sum of Squaresfor Total):是每个因变量的实际值(给定点的所有Y)与因变量平均值(给定点的所有Y的平均)的差的平方和,即,反映了因变量取值的总体波动情况。如下:

回归平方和(SSR,Sum of Squares forRegression):因变量的回归值(直线上的Y值)与其均值(给定点的Y值平均)的差的平方和,即,它是由于自变量x的变化引起的y的变化,反映了y的总偏差中由于x与y之间的线性关系引起的y的变化部分,是可以由回归直线来解释的。
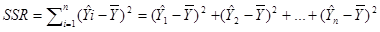
残差平方和(又称误差平方和,SSE,Sum of Squaresfor Error):因变量的各实际观测值(给定点的Y值)与回归值(回归直线上的Y值)的差的平方和,它是除了x对y的线性影响之外的其他因素对y变化的作用,是不能由回归直线来解释的。
这些概念还是有些晦涩,我个人是这么理解的:
就拿广告费和销售额的例子来说,其实广告费只是影响销售额的其中一个比较重要的因素,可能还有经济水平、产品质量、客户服务水平等众多难以说清的因素在影响最终的销售额,那么实际的销售额就是众多因素相互作用最终的结果,由于销售额是波动的,所以用上文提到的每个月的销售额与平均销售额的差的平方和(即总平方和)来表示整体的波动情况。
回归线只表示广告费一个变量的变化对于总销售额的影响,所以必然会造成偏差,所以才会有实际值和回归值是有差异的,因此回归线只能解释一部分影响
那么实际值与回归值的差异,就是除了广告费之外其他无数因素共同作用的结果,是不能用回归线来解释的。
因此SST(总偏差)=SSR(回归线可以解释的偏差)+SSE(回归线不能解释的偏差)
那么所画回归直线的拟合程度的好坏,其实就是看看这条直线(及X和Y的这个线性关系)能够多大程度上反映(或者说解释)Y值的变化,定义
R^2=SSR/SST 或 R^2=1-SSE/SST, R^2的取值在0,1之间,越接近1说明拟合程度越好,假如所有的点都在回归线上,说明SSE为0,则R^2=1,意味着Y的变化100%由X的变化引起,没有其他因素会影响Y,回归线能够完全解释Y的变化。如果R^2很低,说明X和Y之间可能不存在线性关系。
还是回到最开始的广告费和销售额的例子,这个回归线的R^2为0.73,说明拟合程度还凑合。
四、相关系数R和判定系数R^2的区别
判定系数R^2来判断回归方程的拟合程度,表示拟合直线能多大程度上反映Y的波动。
在统计中还有一个类似的概念,叫做相关系数R(这个没有平方,学名是皮尔逊相关系数,因为这不是唯一的一个相关系数,而是最常见最常用的一个),用来表示X和Y作为两个随机变量的线性相关程度,取值范围为【-1,1】。
当R=1,说明X和Y完全正相关,即可以用一条直线,把所有样本点(x,y)都串起来,且斜率为正,
当R=-1,说明完全负相关,及可以用一条斜率为负的直线把所有点串起来。
如果在R=0,则说明X和Y没有线性关系,注意,是没有线性关系,说不定有其他关系。
就如同这两个概念的符号表示一样,在数学上可以证明,相关系数R的平方就是判定系数。
变量的显著性检验
变量的显著性检验的目的:剔除回归系数中不显著的解释变量(也就是X),使得模型更简洁。在一元线性模型中,我们只有有一个自变量X,就是要判断X对Y是否有显著性的影响;多元线性回归中,验证每个Xi自身是否真的对Y有显著的影响,不显著的就应该从模型去掉。
变量的显著性检验的思想:用的是纯数理统计中的假设检验的思想。对Xi参数的实际值做一个假设,然后在这个假设成立的情况下,利用已知的样本信息构造一个符合一定分布的(如正态分布、T分布和F分布)的统计量,然后从理论上计算得到这个统计量的概率,如果概率很低(5%以下),根据"小概率事件在一次实验中不可能发生"的统计学基本原理,现在居然发生了!(因为我们的统计量就是根据已知的样本算出来的,这些已知样本就是一次实验)肯定是最开始的假设有问题,所以就可以拒绝最开始的假设,如果概率不低,那就说明假设没问题。
其实涉及到数理统计的内容,真的比较难一句话说清楚,我举个不恰当的例子吧:比如有一个口袋里面装了黑白两种颜色的球一共20个,然后你想知道黑白球数量是否一致,那么如果用假设检验的思路就是这样做:首先假设黑白数量一样,然后随机抽取10个球,但是发现10个都是白的,如果最开始假设黑白数量一样是正确的,那么一下抽到10个白的的概率是很小的,但是这么小概率的事情居然发生了,所以我们有理由相信假设错误,黑白的数量应该是不一样的……
总之,对于所有的回归模型的软件,最终给出的结果都会有参数的显著性检验,忽略掉难懂的数学,我们只需要理解如下几个结论:
T检验用于对某一个自变量Xi对于Y的线性显著性,如果某一个Xi不显著,意味着可以从模型中剔除这个变量,使得模型更简洁。
F检验用于对所有的自变量X在整体上看对于Y的线性显著性
T检验的结果看P-value,F检验看Significant F值,一般要小于0.05,越小越显著(这个0.05其实是显著性水平,是人为设定的,如果比较严格,可以定成0.01,但是也会带来其他一些问题,不细说了)
下图是用EXCEL对广告费和销售额的例子做的回归分析的结果(EXCEL真心是个很强大的工具,用的出神入化一样可以变成超神),可以看出F检验是显著的(Significance F为0.0017),变量X的T检验是显著的(P-value为0.0017),这俩完全一样也好理解,因为我们是一元回归,只有一个自变量X。

用Excel做线性回归分析
还有一点是intercept(截距,也就是Y=aX+b中的那个b)的T检验没有通过,是不显著的,一般来说,只要F检验和关键变量的T检验通过了,模型的预测能力就是OK的。
End.
来源:博客园
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论