
特征选择是什么
特征选择也称特征子集选择,是从现有的m个特征中选出对机器学习有用的n个特征(n<=m),以此降低特征维度减少计算量,同时也使模型效果达到最优。
为什么要做特征选择
在实际业务中,用于模型中的特征维度往往很高,几万维,有的一些CTR预估中维度高达上亿维,维度过高会增大模型计算复杂度,但是在这么多维数据中,并不是每个特征对模型的预测都是有效果的,所以需要利用一些方法去除一些不必要特征,从而降低模型的计算复杂度。
特征选择的基本原则
我们在进行特征选择时,主要遵循如下两个原则:
-
波动性
-
相关性
波动性是指该特征取值发生变化的情况,用方差来衡量,如果方差很小,说明该特征的取值很稳定,可以近似理解成该特征的每个值都接近,这样的特征对模型是没有任何效果,是不具备区分度的,比如年龄这个特征,都是20岁左右大小的。反之,方差越大,则特征对模型的区分度越好。
相关性是就是该特征和目标结果的相关性大小,常用皮尔逊相关系数来度量。
特征选择的方法及实现
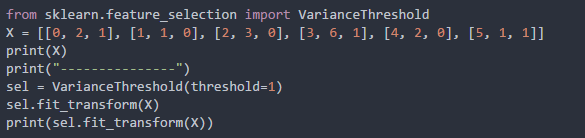
1.移除低方差特征
移除低方差特征是指移除那些方差低于某个阈值,即特征值变动幅度小于某个范围的特征,这一部分特征的区分度较差,我们进行移除。
这里的这个阈值需要根据具体的业务场景进行设定。
2.单变量特征选择
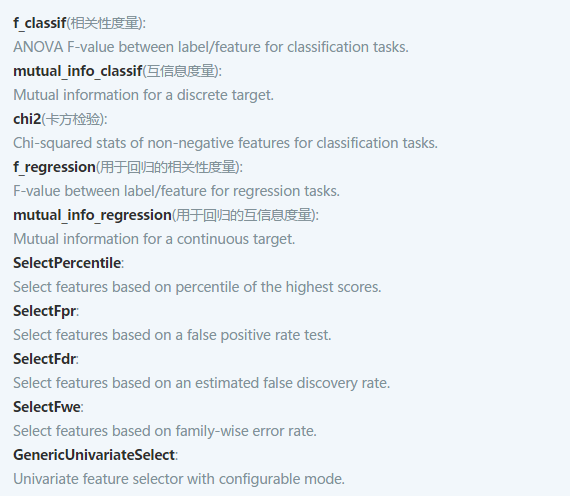
单变量特征是基于单一变量和目标y之间的关系,通过计算某个能够度量特征重要性的指标,然后选出重要性Top的K个特征。但是这种方式有一个缺点就是忽略了特征组合的情况,有的时候单一特征可能表现不是很好,但是与其他特征组合以后,效果就很不错,这样就会造成特征被误删,所以这种特征选择方式不常用。该特征选择方式可以通过SelectKBest(score_func=<function f_classif at 0x6404aa0>, k=10)实现,其中score_func是用来指定特征重要性的计算公式,k是特征保留维度。下面是一些score_func函数及其解释:
递归式消除特征
递归式消除特征(RFE)是指,将全部特征都丢到给定的模型里面,模型会输出每个特征的重要性,然后删除那些不太重要的特征;把剩下的特征再次丢到模型里面,又会输出各个特征的重要性,再次删除;如此循环,直至最后剩下目标维度的特征值。
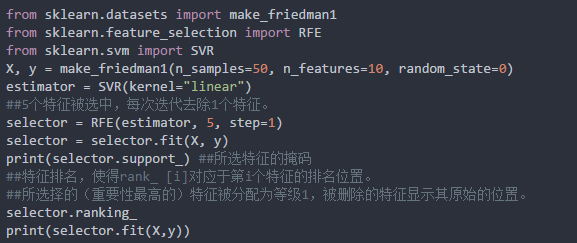
因为该方法每次都需要把特征从新丢到模型里面进行计算,计算量较为复杂;因该方法需要模型输出特征重要性,所以需要选用可以输出特征重要性的模型,比如LR的coef_。
使用SelectFromModel选取特征
SelectFromModel可以用来处理任何带有coef_或者feature_importances_ 属性的训练之后的模型。 如果相关的coef_ 或者 feature_importances 属性值低于预先设置的阈值,这些特征将会被认为不重要并且移除掉。除了指定数值上的阈值之外,还可以通过给定字符串参数来使用内置的启发式方法找到一个合适的阈值。可以使用的启发式方法有 mean 、 median 以及使用浮点数乘以这些(例如,0.1*mean )
SelectFromModel和递归式消除特征不同的是,该方法不需要重复训练模型,只需要训练一次即可;二是该方法是指定权重的阈值,不是指定特征的维度。
1.基于L1正则化的特征提取
使用L1正则化的线性模型会得到一个稀疏权值矩阵,即生成一个稀疏模型:该模型的大多数系数为0,即特征重要性为0,这个时候可以利用 SelectFromModel方法选择非零系数所对应的特征,正则化的过程就可以看作是特征选择的一部分。可以用于此目的的稀疏评估器有用于回归的linear_model.Lasso,以及用于分类以及用于分类的linear_model.LogisticRegression 和 svm.LinearSVC。实现方式如下:

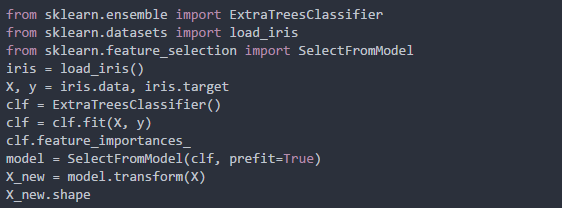
2.基于Tree(树)模型的特征选取
我们知道树模型的建立过程就是一个特征选择的过程,他会根据信息增益的准则来选择信息增益最大的特征来进行建模,输出各个特征的feature_importances_,然后传入SelectFromModel进行特征选择。具体实现方式如下:
End.
作者:张俊红
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论