
前两天在看《推荐系统实战》。书中提到基于用户行为推荐算法的时候,提到一个场景,其实用 SQL 来解,也非常容易。
已知场景是这样的,某视频网站收集了用户观影数据:
{ "电影":"你好,李焕英", "上市日期":"2021-02", "观影者":{ {"姓名":"小林", "年龄":22,"购买日期":"2021-02-18","票价":98,"地址":"陆家嘴星美影院"}, {"姓名":"小李", "年龄":21,"购买日期":"2021-02-16","票价":92,"地址":"万达星美影院"}, {"姓名":"小北", "年龄":24,"购买日期":"2021-02-19","票价":96,"地址":"五角场星美影院"}, {"姓名":"小民", "年龄":22,"购买日期":"2021-02-18","票价":98,"地址":"陆家嘴星美影院"} }, "电影":"速度与激情9", "上市日期":"2021-05", "观影者":{ {"姓名":"小林", "年龄":22,"购买日期":"2021-05-20","票价":98,"地址":"陆家嘴星美影院"}, {"姓名":"小李", "年龄":21,"购买日期":"2021-05-21","票价":92,"地址":"万达星美影院"}, {"姓名":"小北", "年龄":24,"购买日期":"2021-05-22","票价":96,"地址":"五角场星美影院"} } ...}网站需要根据品味和观影历史,向用户推荐其他影片。
两个人的品味是否相近,依据年龄是否相仿,并不能最好地做出判断。但如果两人观影记录重叠,品味相近的概率就大很多。基于此,就可以互相推荐对方还未看过的电影了。
这个时候,用什么样的编程方式,来计算观影重叠,就值得商榷了。
有人说用Python, 轻便简易;有人说用 Java,库多不愁;还有人说c++, 性能贼快。
作为 SQL 博主,当然推荐 SQL, 这种集合类计算,SQL 是把快刃。对于举棋不定的朋友,你一定是缺少数据建模思维,正所谓:心中有模型,则SQL自然成!
为什么我一直推荐金融,财会,产品的朋友,都要学一学SQL, 学一学集合理论,原因就在这。SQL 理念有助于你理解现实中的思维逻辑,成为5分钟看透世界本质的人。
所有工作中遇到的逻辑分析难题,都可以借助SQL来完成。下面这段话,建议你读三遍:
SQL 在手,人无我有。数据再大,我用SQL!
注意:SQL 在这里,一定要读 "色扣"。
那么怎么培养自己的数据建模思维呢?如下详细来说。
依据上面的观影日志记录,经过 ETL 裁剪,可得到观影记录如下:
ETL(Extract Transform Load) , 负责把数据转换成SQL可操作的格式。
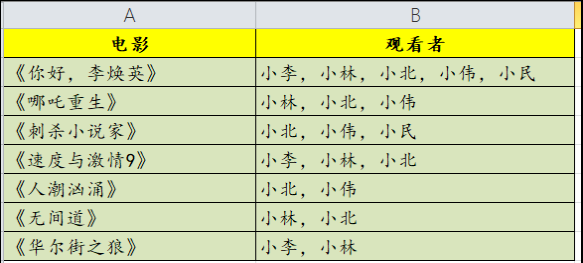
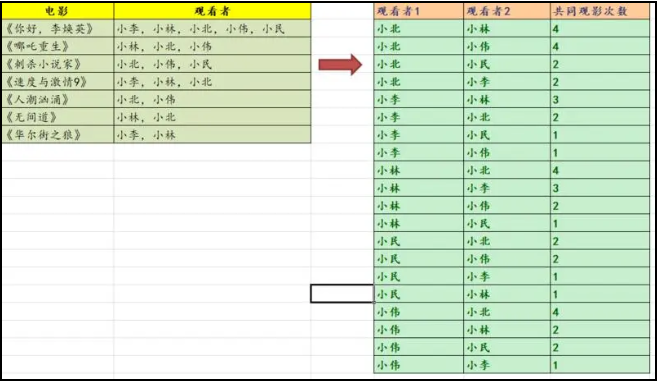
此时,推荐问题就转换成了:哪两个人的观影重叠次数最多。
最终,问题就化解为简单的SQL题, Group by .... Order By... 模式:
SELECT 观看者1, 观看者2,COUNT(DISTINCT 电影) AS 电影数量FROM tblUserFilmsGROUP BY 观看者1, 观看者2ORDER BY 观看者1,COUNT(DISTINCT 电影) DESC 由此可推导,与他/她同好的人,可能还喜欢对方的其他爱好。
那么,怎么才能生成如下两两组合,求观影重叠次数的数据模型呢?
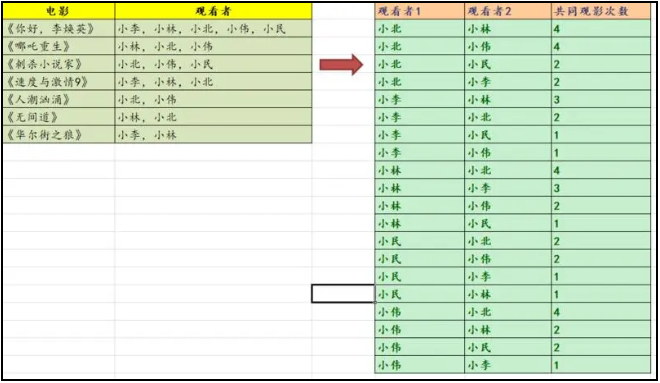
很显然,要把原始数据打散,打平,破除原先不符合三范式的结构:
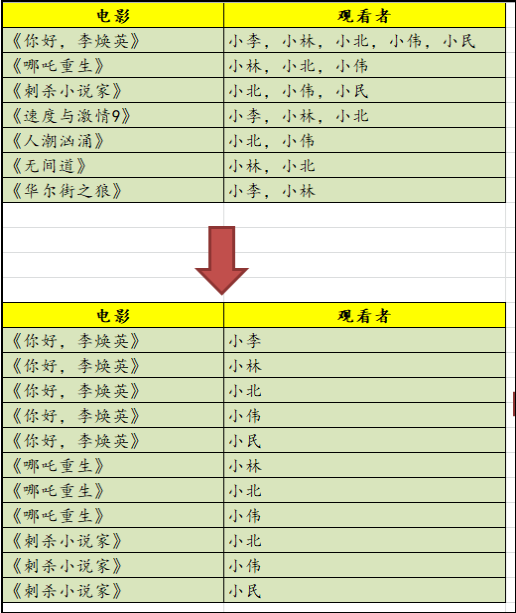
这个时候,最小粒度的数据模型就出来了,影片 + 观看者,没有有重复记录,也没有粘连的记录。
实现这一步,最常规的思维就是拆字符串, 可以自定义函数实现,也可以利用系统自带的函数。比如SQL Server中就有 string_split函数:
select act.Film, usr.*from dbo.UserFilms act OUTER APPLY ( SELECT * FROM String_Split(act.Watcher, ",") tmp ) usr 最后一步,是真正揭开本次算法的关键,也是我平常运用最多的一个思维,无中生有。
单列观影者,怎么才能组合成双列观影者呢?
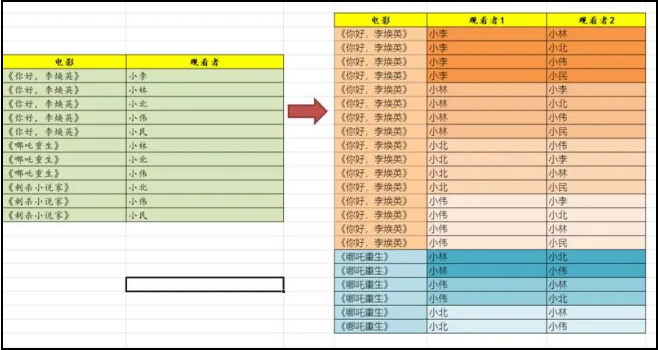
很多教材,都有涉及 Join 这个主题。大多数一直在强调相等性 join, 对于不等性和半等性 Join, 重视不多。所以很多初学者自然不知道,Join 其实可以用 <> 来连接:
;with base_query as ( select act.Film, usr.* from dbo.UserFilms act OUTER APPLY ( SELECT * FROM String_Split(act.Watcher, ",") tmp ) usr),base_query_com as ( select act.Film, act.value as Watcher, act1.value as Watcher2 from base_query act inner join base_query act1 on act1.Film = act.Film and act1.value <> act.value)select Watcher, Watcher2, COUNT(DISTINCT Film) as Filmsfrom base_query_comgroup by Watcher, Watcher2order by Watcher, Films DESC 这里着重注意不等性 Join 的表达:
inner join base_query act1 on act1.Film = act.Film and act1.value <> act.value最终,顺利完成两两聚合求最多的运算:
这个例子在平时工作中,非常具有典型性。用图再展示下一步步的思考流程:
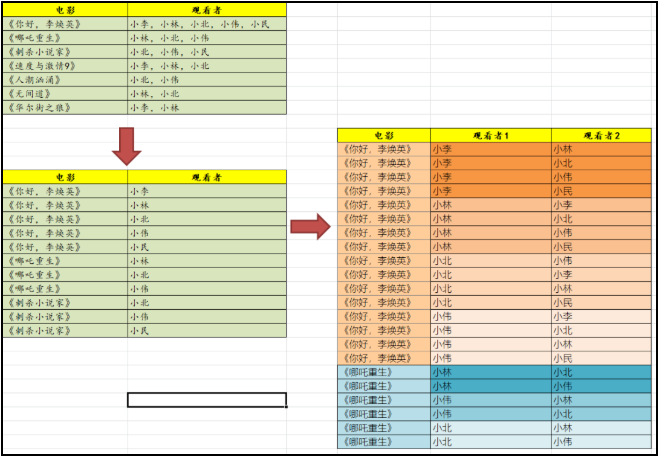
在这里,有两步模型的转换值得记录:打破范式约束(打散粘连的字符串)和 不等性 Join.
每一步模型的转换,都可以沉淀出来一个套路,累积这些套路,你将会有一个强大的兵器库,来拆解各类逻辑问题。
End.
作者:Lenis
本文为转载分享,如果涉及作品、版权和其他问题,请联系我们第一时间删除(微信号:lovedata0520)
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论