
《Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks》翻译过来叫做《注意力FM:通过Attention网络学习特征交互的权重》,它是由浙大和新加坡国立大学的学生在2017年联合发表的,它是基于FM模型的一种优化,如果对FM模型不了解的同学,可以通过下方传送门回顾一下FM模型的相关内容。
一、摘要
FM是我们比较熟悉的模型,它引入所有特征的二阶交叉,通过向量内积的方式来计算所有二阶项的系数,来达到提升效果的目的。但是FM也有缺点,虽然我们通过一些数学的方式对它的效率进行了提升,但仍然有些问题没有解决。比如,对于一个固定的特征而言,它和其他特征交叉的向量都是一样的。再比如并不是所有特征的二阶交叉组合都是有用的,有些反而是干扰项。
在这篇paper当中我们通过消除不同特征组合之间的重要性来优化FM模型,我们把这种新的FM模型叫做AFM(Attentional Factorization Machine)。
它最大的特性就是特征交叉的重要性是通过attention神经网络获得的。我们在两个实际的数据集上进行了完整的测试,测试结果显示AFM相比FM带来了8.6%的提升。和Wide & Deep以及Deep Cross相比,AFM的参数空间也更小,结构更加简单。并且paper作者提供了TensorFlow实现的github地址,大家对源码感兴趣可以点击阅读原文查看。
二、简介
众所周知,在机器学习以及数据挖掘当中,监督学习占据了很大的比重。监督学习某种程度上可以看成是学习一个函数,让它的output越来越接近我们实际想要的值。如果我们想要的值是浮点数,那么这个就是回归模型,如果是一个类别,那么则是分类模型。在推荐系统、在线广告以及图片识别等方面,监督模型起到了举足轻重的作用。
当我们的特征以类别特征为主的时候,让模型学习特征之间的交叉信息会变得非常关键。我们举一个简单的例子,比如我们有职业和层级这两个不同的特征。职业有银行职员以及工程师,层级有初级和高级。其中初级的银行职员的收入要低于初级工程师,而高级的职员收入则要高于高级工程师。如果模型无法学习到交叉信息,是很难预测准确的。
以LR模型举例,LR模型本质上是各个变量的加权求和的结果。无论是初级还是高级,工程师和银行职员这两个职业对应的权重都是一样的。显然,这个时候,模型很难预测准确。
为了考虑特征之间的交叉信息,一种常用的方法是引入新的参数向量,通过向量的内积来计算出交叉的权重。比如polynomial regression(PR)模型,它所有交叉特征的权重都是通过学习得到的。然而这样的设计有一个比较大的问题,就是对于那些稀疏的数据集会有一些交叉特征的权重没有办法学习到。比如说如果是商品的类目和用户的职业交叉,对于某一个冷门的类目以及冷门的职业,我们很难保证训练集当中包含了足够的样本来训练这个权重。
FM模型的提出正是为了解决这个问题,这个大家应该也都很熟悉了,我就不多说了。简而言之就是通过给每一个特征赋予一个向量的方式,当两个特征交叉的时候,通过计算它们向量的内积来代表它们交叉特征的权重。因为这种创新设计,FM取得了巨大的成功,在推荐系统以及NLP领域都有应用。但是FM模型仍然也有缺陷,比如在现实世界当中,不同的特征往往起到的效力不同,并不是所有特征都适合用来进行特征的交叉。所以一个改进思路是对于那些效力不高的交叉项进行降权,对不同的交叉特征进行自动升权或降权。
在这篇paper当中我们通过对特征交叉的组合进行区别对待的方式来提升FM的效果,区别对待的方式就是引入Attention神经网络的机制。
三、FM部分
FM模型的细节我们已经写过很多次了,这里不再重复了,需要回顾的小伙伴可以点击下方的传送门重温一下FM的细节。
四、AFM
下面我们直接进入本文的重点AFM的原理。
Model
下图展示的就是AFM模型的结构,为了方便观看,我们去除了线性回归的部分。
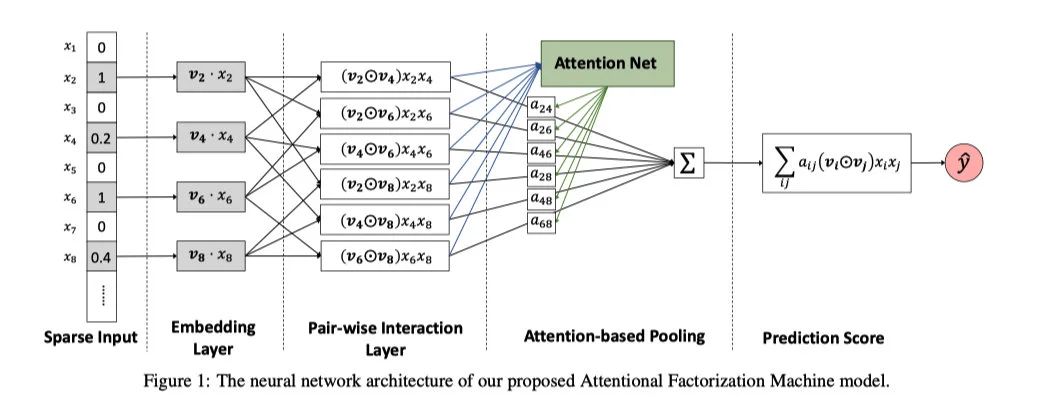
input层以及Embedding层都和FM模型一致,它的输入是一个sparse表示的特征,它会把非零项转化成float向量。接下来,我们会详细解释一下pair-wise interaction层也就是二维特征的交叉层以及Attention-based Pooling层,这些也是这篇paper的主要内容。
Pair-wise interaction Layer

Attention-based Pooling Layer

Learning
AFM相比FM直接在数据表达能力上进行了提升,因此它除了可以使用在一系列预测问题当中也可以使用在其他场景下。比如回归、分类和排序。问题的目标不同,使用的损失函数也不一样。比如对于回归问题,我们一般使用均方差,二分类问题我们则使用交叉熵。在这篇paper当中我们聚焦在回归问题上,并且使用均方差作为模型优化目标。
为了使得优化目标最优,我们使用随机梯度下降算法(SGD)来进行参数的训练。SGD是机器学习当中广泛使用的优化方法之一,也被像是TensorFlow、Pytorch等深度学习框架所支持,因此就不过多赘述了。
预防过拟合

五、实验
实验的部分着重回答了以下三个问题:
- 关键的超参数是如何影响AFM性能的(drop比例以及Attention网络的正则项)?
- Attention网络能高效地学到特征交叉的重要性吗?
- AFM和其他先进的模型相比,性能如何?
实验设置
使用了两份公开的数据集用来进行实验,分别是Frappe和Movielens。
- Frappe,被用来做上下文相关的推荐,包含了96203条用户在不同上下文下使用的日志。一共有8种上下文变量,这些变量都是categorical特征,包括了天气、城市、时间等。我们通过one-hot对特征进行处理,得到5382个特征。
- MovieLens,用来做用户标签推荐,包含了668953个电影的tag。我们把每个tag的应用(userID, movieID和tag)转化成特征向量,得到90445个特征。
评估标准
对于所有的数据集而言,label值为1表示了用户在上下文中使用了app,或者是申请了一个电影的tag。我们把负样本标记为-1,这样在两个数据集上分别得到了288609和2006859条样本。我们将70%的样本作为训练集,20%的验证集和10%的测试集。
验证集的样本仅仅用来调试参数,性能的评估通过测试集完成。我们使用RMSE(root mean square error)来作为性能指标。
我们将AFM与LibFM、HOFM、Wide&Deep以及DeepCross进行对比,为了公平这些模型都经过调试到达最优。除了LibFM之外,所有的模型都通过min-batch Adagrad方法进行的训练。Frappe和Movielens的batch size分别是128和4096,embedding size均为256。
我们对于Wide&Deep和DeepCross的dropout rate进行了调试,并且采用了early stop的方法。对于Wide&Deep,DeepCross以及AFM模型来说,我们发现使用预训练得到的embedding向量的效果要比随机初始化的更好。dropout的调试情况如下:
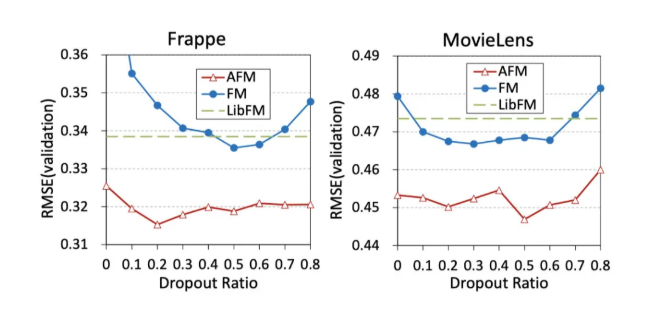
参数调整的研究(问题一)
在实验当中我们着重对两个参数对模型性能的影响进行了着重的实验,分别是的正则系数以及Attention factor,即Attention网络隐层的大小。
首先,我们先来看的调试结果,仅仅用在正则当中,对它进行调试不会对模型的其他部分有任何影响,整个结果相对更加准确。
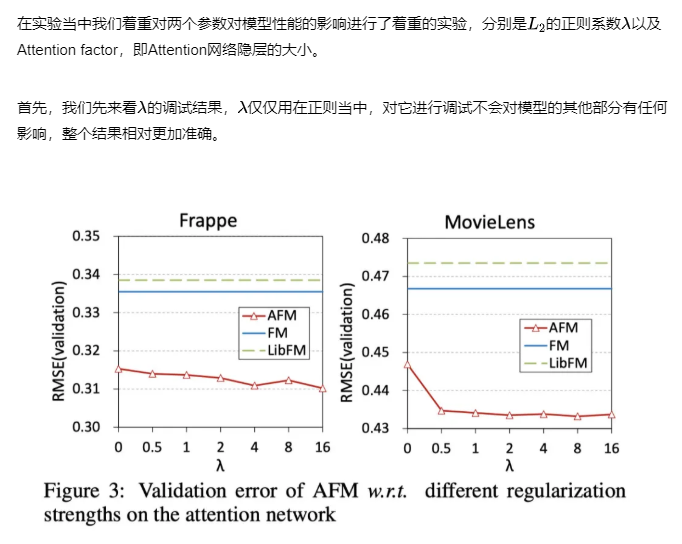
我们可以看到对这两份数据集来说,我们适当增加的值可以带来一定量的提升。相比于之前dropout参数的调试,显然正则项带来的影响更大。
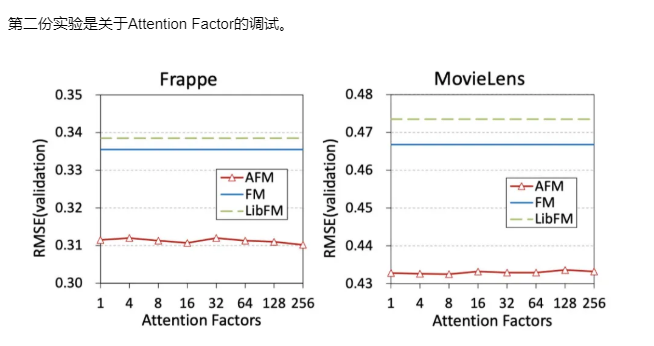
我们可以看到Attention Factor对结果的影响非常小,和dropout参数一样,可有可无。这还不是重点,重点是这个所谓的Attention Factor影响的并不是Attention层而已,由于它是要与embedding向量进行点积运算的。所以它必须要和embedding size保持一致。也就是说在这个实验当中,影响的并不仅仅是Attention网络而已,embedding size本身也是一个很大的变量。但这点paper当中没有提到,不知道是不是故意的。
Attention 网络的影响(问题二)
这篇paper的重点就是在FM当中引入Attention机制,那么Attention网络究竟有没有影响呢?
答案是有的,我们从上面这张图也可以看得出来。当Attention Factor为1的时候,模型依然得到了提升。这个时候模型退化成了二阶线性回归模型,但由于有了Attention网络的参数,效果依然胜过FM,已经可以充分说明了Attention网络的效果。
除此之外,paper当中还展示了整个训练过程的指标收敛情况。
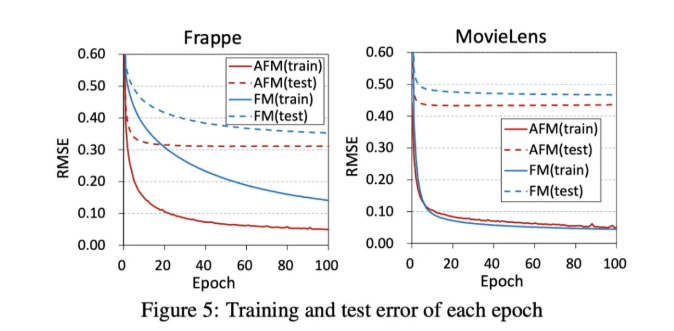
从这张图我们可以看到AFM的效果要明显好于FM,也证明了Attention网络的效果。
另外,paper当中还做了额外的研究工作。首先,固定了Attention输出的结果为,然后训练FM部分。接着我们固定FM的部分,仅仅训练Attention网络的参数。当收敛的时候,模型的效果提升了3%。之后我们选择了测试集中的3条正例样本,展示了一下Attention分数和interaction分数相乘的结果如下:
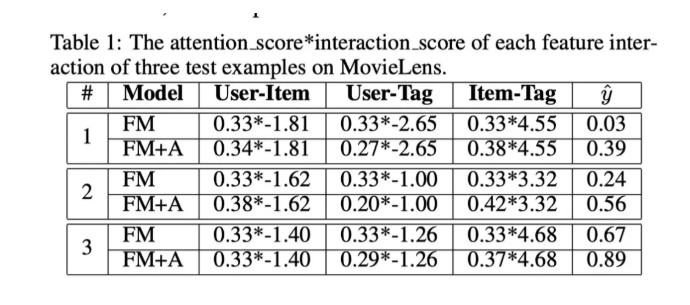
我们可以看到,对于FM来说它没有Attention网络,所以所有的interaction它的权重都相同,都是0.33。而加上了Attention网络的AFM在Item-Tag这一栏的权重明显更高,并且最终得到的分数也更接近1。
这里的interaction score论文当中没有详细的说明,根据FM的公式推测应该是。
性能对比(问题三)
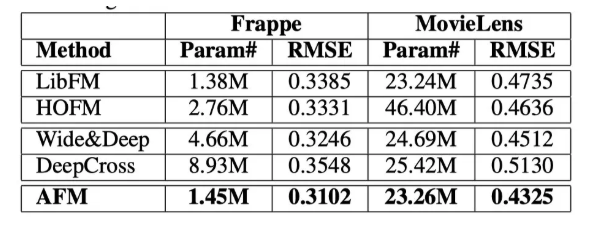
最后, 我们展示一下在测试集当中各个模型的表现。
其中的Param一栏展示的是模型的参数量,我们可以看到AFM的样本参数数量仅仅多余LibFM,但它的RMSE是最小的。证明了AFM的一个有效性。
六、尾声
到这里,这篇AFM的paper我们就算是解析完了。基本上paper当中的要点本文都提及了,可能略过了部分我觉得没有什么用处的描述或者是说明。如果觉得有所困惑的同学,有能力还是建议阅读一下原文。点击查看https://github.com/hexiangnan/attentional_factorization_machine
你会发现即使是阅读原文,也一样会遇到很多困惑或者是不清楚的地方,这个时候就需要我们根据自己对模型以及问题的理解来进行合理地猜测。猜测得多了,你会发现你读paper会越来越顺,可能这也是能力之一吧。
希望大家尤其是这行的从业者,都能花点时间读读论文,学点东西。
End.
爱数据网专栏作者:承志
作者介绍:前阿里人,推荐算法专家,一年更新400篇博文的勤奋作者
个人微信公众号:TechFlow(ID:techflow2019)
本文为挖数网专栏作者原创文章,未经允许禁止转载,需要转载请微信联系授权(微信号:lovedata0520)
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论