
多线程同步异常
报错如下所示:
java.sql.SQLException: Error while processing statement: FAILED: Hive Internal Error: 》>java.util.ConcurrentModificationException(null)
at org.apache.hive.jdbc.HiveStatement.waitForOperationToComplete(HiveStatement.java:401) ~[hive-jdbc->3.1.0.3.0.2.1-4.jar:3.1.0.3.0.2.1-4]
at org.apache.hive.jdbc.HiveStatement.execute(HiveStatement.java:266) ~[hive-jdbc-3.1.0.3.0.2.1->4.jar:3.1.0.3.0.2.1-4]
解决的办法:
hive.warehouse.subdir.inherit.perms=false
内存溢出
1.2 GB of 1 GB physical memory used; 2.2 GB of 2.1 GB virtual memory used. Killing contain
从字面意思来看,是数据量超过 map 或者 reduce task 的内存大小。所以 yarn 不得不讲整个任务杀死。最直接的解决办法是设置:
set mapreduce.map.memory.mb=4096;set mapreduce.map.java.opts=-Xmx4096m;set mapreduce.reduce.memory.mb=4096;set mapreduce.reduce.java.opts=-Xmx4096m;
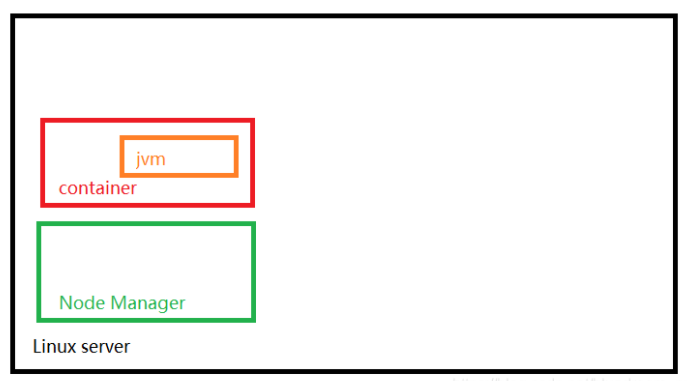
上面是我对 Node Manage 的理解,RM 会将 Linux 系统之上的 NodeManager 的资源分配给对应的 appMaster , 上面的资源也就是由"Node Manager" 管理的 container ,container 是一个进程,container启动 map task 或者 reduce task,是启动了一个子线程的 jvm 。mapreduce.reduce.java.opts 是指定 reduce task 的 jvm 启动时候的 heap 的内存大小。mapreduce.reduce.memory.mb 是 container 进程的内存大小,reduce task 作为 container 的子线程,内存只能 <= 父进程的内存大小。所以 mapreduce.reduce.java.opts <= mapreduce.reduce.memory.mb 。
另外,yarn.nodemanager.resource.memory-mb 是 linux 服务器能够分配给 yarn 的内存。
yarn.nodemanager.vmem-pmem-ratio 是虚拟内存所占的比例。
yarn.scheduler.minimum-allocation-mb 和 yarn.scheduler.maximum-allocation-mb单个Container可以申请的最小和最大内存的限制就是这两个参数。
内存分配的规则:
如果是 fairy 的 scheduler,那么 yarn.scheduler.increment-allocation-mb 是规整化因子。
如果是 capacity 或者 fifo 的 scheduler , yarn.scheduler.minimum-allocation-mb 是规整化因子。
规整因子是什么?是分配给 container 内存的最小单位。具体例子如下:
上面是我对 Node Manage 的理解,RM 会将 Linux 系统之上的 NodeManager 的资源分配给对应的 appMaster , 上面的资源也就是由"Node Manager" 管理的 container ,container 是一个进程,container启动 map task 或者 reduce task,是启动了一个子线程的 jvm 。mapreduce.reduce.java.opts 是指定 reduce task 的 jvm 启动时候的 heap 的内存大小。mapreduce.reduce.memory.mb 是 container 进程的内存大小,reduce task 作为 container 的子线程,内存只能 <= 父进程的内存大小。所以 mapreduce.reduce.java.opts <= mapreduce.reduce.memory.mb 。
另外,yarn.nodemanager.resource.memory-mb 是 linux 服务器能够分配给 yarn 的内存。
yarn.nodemanager.vmem-pmem-ratio 是虚拟内存所占的比例。
yarn.scheduler.minimum-allocation-mb 和 yarn.scheduler.maximum-allocation-mb单个Container可以申请的最小和最大内存的限制就是这两个参数。
内存分配的规则:
如果是 fairy 的 scheduler,那么 yarn.scheduler.increment-allocation-mb 是规整化因子。
如果是 capacity 或者 fifo 的 scheduler , yarn.scheduler.minimum-allocation-mb 是规整化因子。
规整因子是什么?是分配给 container 内存的最小单位。具体例子如下:
假如规整化因子b=512M,上述讲的参数yarn.scheduler.minimum-allocation-mb为1024,yarn.scheduler.maximum-allocation-mb为8096,然后我打算给单个map任务申请内存资源(mapreduce.map.memory.mb):
申请的资源为a=1000M时,实际得到的Container内存大小为1024M(小于yarn.scheduler.minimum-allocation-mb的话自动设置为yarn.scheduler.minimum-allocation-mb);
申请的资源为a=1500M时,实际得到的Container内存大小为1536M,计算公式为:ceiling(a/b)b,即ceiling(a/b)=ceiling(1500/512)=3,3512=1536。此处假如b=1024,则Container实际内存大小为2048M
也就是说Container实际内存大小最小为yarn.scheduler.minimum-allocation-mb值,然后增加时的最小增加量为规整化因子b,最大不超过yarn.scheduler.maximum-allocation-mb
————————————————
版权声明:本文为CSDN博主「蜗牛蜗牛慢慢爬」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u014665013/article/details/80923044
hadoop 租约问题
hadoop 为了防止多个进程写同一个文件的,从而造成了数据一致问题。hadoop 使用租约这个概念。如果的出现下面的错误提示,就是出现了写入文件后,没有正常关闭问题,租约没有删除。
Cannot obtain block length for LocatedBlock
出现租约问题,首先使用 hdfs fsck / –openforwrite 查看文件的状态。
然后使用 hdfs debug recoverLease -path <path-of-the-file> -retries <retry times> 来清除无效租约。
设置 map reduce 的内存
设置内存大小是最最常用的参数,大多数情况下,我们会遇到的跑批问题,是内存不足的问题,所以我们首先要做的是变大 map 或者 reduce 的内存大小。然后再详细的看如何优化。参数设置如下所示:
set mapreduce.map.memory.mb=1524;注意单位是 MB(兆); container 的内存值; 默认值为 1 Gset mapreduce.map.java.opts=-Xmx1024m; container 中 JVM 的值set mapreduce.reduce.memory.mb=2500; container 的内存;默认3072Mset mapreduce.reduce.java.opts=-Xmx2048m; container 中 jvm 的值
动态分区
动态分区是非常常用的,在生产环境下,我们更愿意,hive 帮我们生成新的分区,而不是我们的人为的去根据数据量的大小,去手工的新建分区,这样做是没有效率的。还有一个重要的原因,更多的时候,我们并不知道,在我们 query 的结果集里面会有多少个分区,所以只能使用动态分区的方式。动态分区的设置如下,建议在系统级别设置:
set hive.exec.dynamic.partition.mode=nonstrict;set hive.exec.dynamic.partition=true;
文件输出的大小
为什么要控制文件输出的大小呢?这就是小文件的问题,我们知道,现在的 hdfs 的块大小是 254 M ,如果的我们输出的文件太小,势必导致块容量的浪费,举个例子,如果我们数据文件总的大小是 10 M, 一共输出了 10 个文件,每个文件的大小是 1 M,则我们需要申请 10 个块,一共申请了 10*254M 大小的磁盘容量,磁盘利用率=10/(25400)= 0.039370% 。太低了。另外一个问题是这样会是的 NN存储的元数据量大大增大,会增加对 NN 访问压力。如何 NN 的响应不及时,就会造成一种情况,明明系统的内存和 core 资源有,但是就是申请不下来,因为元数据的访问响应不及时,无法给太多的任务提供元数据服务。文件输出大小的设置如下所示:
set hive.merge.size.per.task=256000000; 合并文件的大小;256 MBset hive.merge.smallfiles.avgsize=16000000; 文件的平均大小小于该值时,会启动一个MR任务执行merge;256 MBset hive.merge.mapfiles=true:合并map输出set hive.merge.mapredfiles=false:合并reduce输出
控制 Map 的数量
Map 的数量主要是由文件块的数量决定的,理论上讲,一个块就会生成对应一个 Map task。mapreduce 框架还提供给我们一种选择,我们可以使用 Inputformat 先合并文件块,然后将合并后的数据分配给 Map task 。下面就是配置:
set mapreduce.input.fileinputformat.split.minsize=1000 //启动map最小的split size大小set mapreduce.input.fileinputformat.split.maxsize=10000; //启动map最大的split size大小,这个值不能动态的设置,只能在计算框架启动之前设置。公式:splitSize = Math.max(minSize, Math.min(maxSize, blockSize));
我们看到 mapreduce.input.fileinputformat.split.maxsize 的值是固定的,在 hive 运行时不能改动,能改的只有 mapreduce.input.fileinputformat.split.minsize 。我们还看到 splitSize 的大小是受到 minSize、maxSize、blockSize 控制的,其中 blockSize 和 maxSize 的大小是固定的,maxSize 的大小是 256000000(256M),也就是说 minSize 的大小超过 256M 才可以。
另外,控制 map task 数量的最后办法是控制分区的大小,所以在写 sql 的时候,一定要指定分区的大小,哪怕取得全量得数据,也要加上分区得限制条件;
下面得图片中可以明显的看出分区的大小对 map task 数量的影响。


接下了,我们需要考虑的是数据的合并器了,合并器会根据上面 splitSize 的大小来合并文件的块。具体的设置如下所示:
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;set hive.merge.mapFiles=true;set hive.merge.mapredFiles=true;set hive.merge.size.per.task=256000000; //每个Mapper要处理的数据,就把上面的5M10M……合并成为一个
需要注意的是在 hive 运行时,会报出如下错:<font>
Error: Error while processing statement: Cannot modify hive.input.format at runtime. It is not in list of params that are allowed to be modified at runtime (state=42000,code=1)
在 hive 启动时,设置 hive.input.format 也是不管用的。
控制 map 数量的最后、最直接的办法是控制分区的范围。
数据倾斜
处理数据倾斜的问题,第一个要想到的办法应该是从数据的角度取分析热点数据在哪里,踏踏实实的去查热点数据,如何处理热点数据,我们可以将热点数据单独处理,另外一个办法是在分组中加入更多的字段,最终达到数据平衡的原则。
另外一个是尽量取缩小原始数据的量来获得我们想要的数据。我称之外最小数据集的原则。
还有就是参数的办法,这种办法的作用是有限,但是面试经常用的到。
set hive.map.aggr=true;set hive.groupby.mapaggr.checkinterval=100000 ; 这个是group的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置set hive.groupby.skewindata=true; --如果是group by过程出现倾斜 应该设置为trueset hive.skewjoin.key=100000; --这个是join的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置set hive.optimize.skewjoin=true;--如果是join 过程出现倾斜 应该设置为true
从上面的配置我们可以看到,主要有两种平衡的办法,一个是 groupby 过程,一个是 join 过程。 原理如下图:
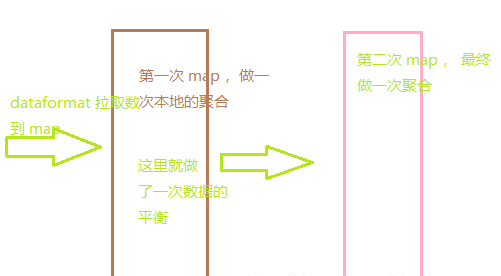
这里还需要强调的是 hive.groupby.skewindata 和 grouping set连用的使用,有的时候会报出下面的错误:
SemanticException [Error 10225]: An additional MR job is introduced since the number of rows created per input row due to grouping sets is more than hive.new.job.grouping.set.cardinality. There is no need to handle skew separately. set hive.groupby.skewindata to false. The number of rows per input row due to grouping sets is 60 (state=42000,code=10225)
这是因为 grouping set 会先将数据复制成 N 份,发送给对应的 reduce 做聚合操作。关键就在 N 是什么,N 是 grouping set 中分组的个数。The number of rows per input row due to grouping sets is 60 这段告诉我们,hive 默认只能能将每条记录复制 60 份发个 reduce ,如果我们的 group set 中的数据份数超过了 60 就会报出这种错误。
有的同学会说,我们可以使用 set hive.new.job.grouping.set.cardinality = 30 这哥们配置复制数据的上限。但是当执行它的时候会报出下面的错误:
Error: Error while processing statement: Cannot modify hive.new.job.grouping.set.cardinality at runtime. It is not in list of params that are allowed to be modified at runtime (state=42000,code=1)
所以说set hive.new.job.grouping.set.cardinality = 30 也是交互情况下不是改动的。
王道
总结几个简单并且有效的原则:
- 了解并掌握热点数据现状。从业务逻辑上去优化,先降维,单独处理热点数据
- 从模型设计或者说解决方案设计之初。考虑复用、降维、最小集合的原则。
- 在表有分区的情况下, where 中一定加入分区条件限制
End.爱数据网专栏作者:wang-possible作者介绍:6年零售大数据工作经验,技能持续精进CSDN个人主页:bluedraam_pp
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论