
一.模型评估
1.ROC曲线
ROC曲线(Receiver Operating Characteristic -- 受试者工作特征曲线),使用图形来描述二分类系统的性能表现。图形的纵轴为真正例率(TPR),横轴为假正例率(FPR)。
其中,真正例率与假正例率定义为:

ROC曲线通过TPR和FPR两项指标,可以用来评估分类模型的性能。TPR和FPR可以通过移动分类模型的阈值而进行计算。随着阈值的改变,TPR和FPR也会随之改变,进而可以在ROC曲线坐标上,形成多个点。
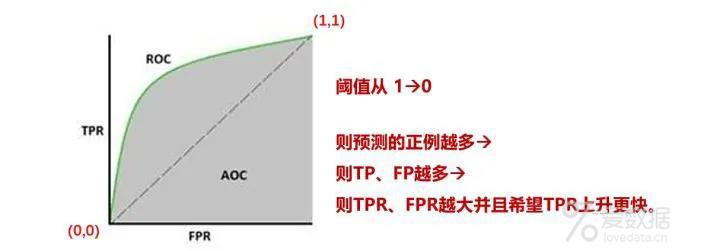
ROC曲线如果为对角线,则可以理解为随机猜测。如果在对角线以下,则其性能比随机猜测还要差。如果ROC曲线真正例率为1,假正例率为0,即曲线为x=0与y=1构成的折线,则此时的分类器是最完美的。
2.AUC
AUC是指ROC曲线下的面积,使用AUC值作为评价标准是因为有时候ROC曲线并不能清晰说明哪个分类器效果更好。AUC值可以直观评价分类器的好坏,值越大效果越好。
3.模型评估验证方法
交叉验证是机器学习建模中非常非常重要的一步,也是大多数人所说的"调参"的过程。
简单交叉验证

k折交叉验证
常用的交叉验证技术叫做K折交叉验证(K-fold Cross Validation)。 我们先把训练数据再分成训练集和验证集,之后使用训练集来训练模型,然后再验证集上评估模型的准确率。

留一交叉验证
最极端的情况下,我们可以采用leave_one_out交叉验证,也就是每次只把一个样本当做验证数据,剩下的其他数据都当做是训练样本。
4.超参数调优
网格搜索
网格搜索的最大优点在于可以做并行化处理。所以只要有足够多的计算资源,都不成问题。

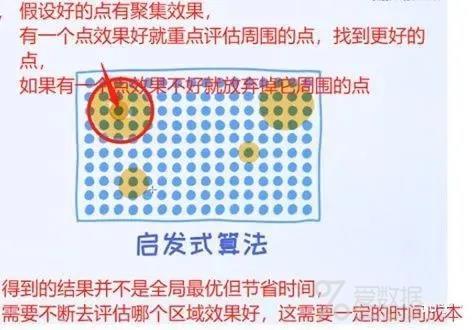
启发式算法
贝叶斯优化
5.欠拟合和过拟合
《吴恩达机器学习》中有相关"偏差、方差"与"欠拟合、过拟合"的内容点,可查阅。
欠拟合
原因
模型复杂度过低,特征量过少。
如何解决欠拟合
- 增加新特征,可以考虑加入进特征组合、高次特征,来增大假设空间;
- 添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强;
- 减少正则化参数,正则化的目的是用来防止过拟合的,但是模型出现了欠拟合,则需要减少正则化参数;
- 使用非线性模型,比如核SVM 、决策树、深度学习等模型;
- 调整模型的容量(capacity),通俗地,模型的容量是指其拟合各种函数的能力;
- 容量低的模型可能很难拟合训练集;使用集成学习方法,如Bagging ,将多个弱学习器Bagging。
过拟合

原因
- 建模样本选取有误,如样本数量太少,选样方法错误,样本标签错误等,导致选取的样本数据不足以代表预定的分类规则;
- 样本噪音干扰过大,使得机器将部分噪音认为是特征从而扰乱了预设的分类规则;
- 假设的模型无法合理存在,或者说是假设成立的条件实际并不成立;
- 参数太多,模型复杂度过高;
- 对于决策树模型,如果我们对于其生长没有合理的限制,其自由生长有可能使节点只包含单纯的事件数据(event)或非事件数据(no event),使其虽然可以完美匹配(拟合)训练数据,但是无法适应其他数据集。
如何避免过拟合
- 数据量的增加
- 使用更简单的模型
- 加入正则项
End.
作者:stecua
来源:知乎专栏
本文为转载分享,如侵权请联系后台删除
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论