
区组化就是事先将全部受试对象,按照某种或某些对观测结果有影响的重要混杂因素的不同水平形成若干个区组,使每一个区组内的受试对象在所设定的重要混杂因素上几乎相同。
在这里,区组的作用是在处理组间消除重要混杂因素(即区组因素)对观测结果的干扰和影响,从而更科学地评价试验因素各水平对观测结果的影响。这些混杂因素可能是单一的,也有可能是多种因素的混合,如身高、体重、窝别等。
这里可以总结一下区组因素或区组变量的概念:它是实验设计中可能影响实验结果的非处理因素,让组间样本的属性均衡一致,有利于发现处理因素的效应。
通常情况下,区组因素和处理因素之间没有交互作用,无须考虑交互作用。
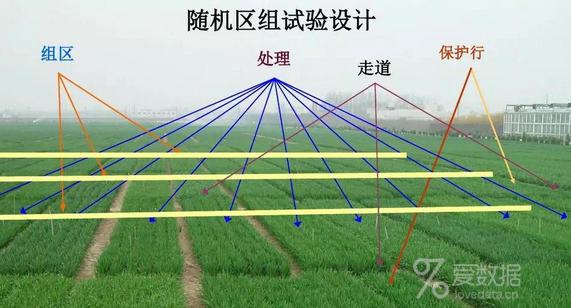
举例说明一下:
假设我们要研究某一个化肥的效果,在其他人为控制条件保持一致的情况下,庄稼的长势一方面是化肥的作用,还有另外一个方面,就是土壤本身的肥力。当试验处理比较多时,每一块土壤的肥力就会产生差异,但是土壤自身肥力这一个因素很难控制,研究者很难让每一块试验田的土壤肥力一致,这样一来就使土壤肥力的差异与试验误差混杂,为了解决这一问题,尽可能降低试验误差提高试验精确度,我们可以把土壤肥力这一非处理因素作为区组变量,划分出多个区组,每个组内土壤肥力尽可能一致,随机化只在区组内进行。
这里,肥料是处理因素,而土壤是区组因素。
End.作者:数据小兵来源:博客本文均已和作者授权,如转载请与作者联系。
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论