
一.引言
如下图所示:
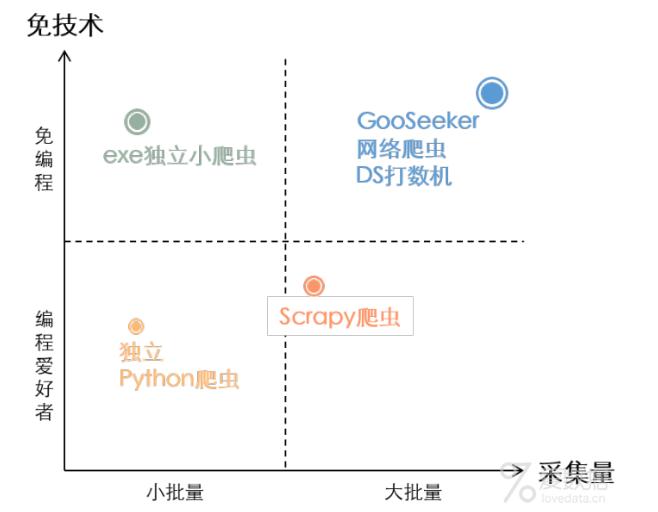
本实战是上图中的"独立python爬虫"的一个实例,以采集安居客房产经纪人(http://shenzhen.anjuke.com/tycoon/nanshan/p1/ )信息为例,记录整个采集流程,包括python和依赖库的安装,即便是python初学者,也可以跟着文章内容成功地完成运行。
二.Python和相关依赖库的安装
- 运行环境:Windows10
1.安装Python3.5.2
- 官网下载链接: https://www.python.org/ftp/python/3.5.2/python-3.5.2.exe
- 下载完成后,双击安装。
- 这个版本会自动安装pip和setuptools,方便安装其它的库
2.Lxml 3.6.0
- Lxml官网地址: http://lxml.de/
- Windows版安装包下载: http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml
- 对应windows下python3.5的安装文件为 lxml-3.6.0-cp35-cp35m-win32.whl
- 下载完成后,在windows下打开一个命令窗口,,切换到刚下载的whl文件的存放目录,运行pip install lxml-3.6.0-cp35-cp35m-win32.whl
3.下载网页内容提取器程序
网页内容提取器程序是GooSeeker为开源Python即时网络爬虫项目发布的一个类,使用这个类,可以大大减少信息采集规则的调试时间,具体参看《Python即时网络爬虫项目: 内容提取器的定义》
- 下载地址: https://github.com/FullerHua/gooseeker/core/gooseeker.py
- 把gooseeker.py保存在项目目录下
三.网络爬虫的源代码

运行过程如下:
- 将上面的代码保存到anjuke.py中,和前面2.3步下载的提取器类gooseeker.py放在同一个文件夹中
- 打开Windows CMD窗口,切换当前目录到存放anjuke.py的路径(cd xxxxxxx)
- 运行 python anjuke.py
请注意:为了让源代码更整洁,也为了让爬虫程序更有通用性,抓取规则是通过api注入到内容提取器bbsExtra中的,这样还有另外一个好处:如果目标网页结构变化了,只需通过MS谋数台重新编辑抓取规则,而本例的网络爬虫代码不用修改。为内容提取器下载采集规则的方法参看《Python即时网络爬虫:API说明》。
四.爬虫结果
在项目目录下可以看到多个result**.xml文件,文件内容如下图所示:

五.总结
因为信息采集规则是通过api下载下来的,所以,本案例的源代码显得十分简洁。同时,整个程序框架变得很通用,因为最影响通用性的采集规则是从外部注入的。
End
作者:华天清
来源:知乎
本文均已和作者授权,如转载请与作者联系。
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论