
一.何为异常
在仙侠剧中,有正魔之分,然何为正道,何为魔道,实属难辨。自称正道的人也许某一天会堕入魔道,被众人称为魔头的人,或许内心自始至终都充溢着正义感!所以说,没有绝对的黑,也没有绝对的白。话说回来,对于"异常"这个词,每个人的心里大概都有一个衡量标准,扩展起来的确很广(如异常点、异常交易、异常行为、异常用户、异常事故等等),那么究竟何为异常呢?异常是相对于其他观测数据而言有明显偏离的,以至于怀疑它与正常点不属于同一个数据分布。异常检测是一种用于识别不符合预期行为的异常模式的技术,又称之为异常值检测。在商业中也有许多应用,如网络入侵检测(识别可能发出黑客攻击的网络流量中的特殊模式)、系统健康性监测、信用卡交易欺诈检测、设备故障检测、风险识别等。这里,将异常分为三种:
- 数据点异常:如果样本点与其他数据相距太远,则单个数据实例是异常的。业务用例:根据"支出金额"检测信用卡欺诈。
- 上下文异常:在时间序列数据中的异常行为。业务用例:旅游购物期间信用卡的花费比平时高出好多倍属于正常情况,但如果是被盗刷卡,则属于异常。
- 集合异常:单个数据难以区分,只能根据一组数据来确定行为是否异常。业务用例:蚂蚁搬家式的拷贝文件,这种异常通常属于潜在的网络攻击行为。
异常检测类似于噪声消除和新颖性检测。噪声消除(NR)是从不需要的观察发生中免疫分析的过程; 换句话说,从其他有意义的信号中去除噪声。新颖性检测涉及在未包含在训练数据中的新观察中识别未观察到的模式。
二.异常检测的难点
在面对真实的业务场景时,我们往往都是满腹激情、豪情壮志,心里默念着终于可以进入实操,干一番大事业了。然而事情往往都不是那么美好,业务通常比较特殊、背景复杂,对于业务的熟悉过程也会耗掉你大部分的时间。然后在你绞尽脑汁将其转化为异常检测场景后,通常又面临着以下几大挑战:
- 不能明确定义何为正常,何为异常,在某些领域正常和异常并没有明确的界限;
- 数据本身存在噪声,致使噪声和异常难以区分;
- 正常行为并不是一成不变,也会随着时间演化,如正常用户被盗号之后,进行一系列的非法操作;
- 标记数据获取难:没有数据,再好的算法也是无用。
针对上述挑战,下面我们来看看具体的场景和用于异常检测的算法。
三.基于统计的异常值检测
这里将基于统计的作为一类异常检测技术,方法比如多,下面主要介绍MA和3-Sigma。
1.MA滑动平均法
识别数据不规则性的最简单的方法是标记偏离分布的数据点,包括平均值、中值、分位数和模式。假定异常数据点是偏离平均值的某个标准偏差,那么我们可以计算时间序列数据滑动窗口下的局部平均值,通过平均值来确定偏离程度。这被技术称为滑动平均法(moving average,MA),旨在平滑短期波动并突出长期波动。滑动平均还包括累加移动平均、加权移动平均、指数加权移动平均、双指数平滑、三指数平滑等,在数学上,nn周期简单移动平均也可以定义为"低通滤波器"。
缺点:
- 数据中可能存在与异常行为类似的噪声数据,所以正常行为和异常行为之间的界限通常不明显;
- 异常或正常的定义可能经常发生变化,因为恶意攻击者不断适应自己。因此,基于移动平均值的阈值可能并不总是适用。
2.3-Sigma
3-Sigma原则又称为拉依达准则,该准则定义如下。
假设一组检测数据只含有随机误差,对原始数据进行计算处理得到标准差,然后按一定的概率确定一个区间,认为误差超过这个区间的就属于异常值。
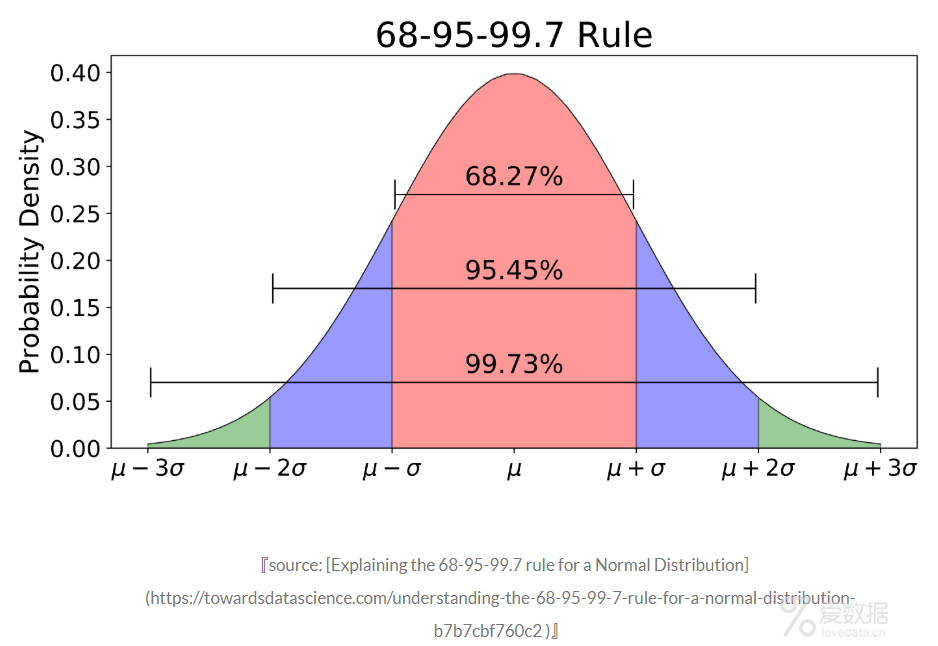

- #3-sigma识别异常值
- def three_sigma(df_col):
- """
- df_col:DataFrame数据的某一列
- """
- rule = (df_col.mean() - 3 * df_col.std() > df_col) | (df_col.mean() + 3 * df_col.std() < df_col)
- index = np.arange(df_col.shape[0])[rule]
- outrange = df_col.iloc[index]
- returnoutrange
对于异常值检测出来的结果,有多种处理方式,如果是时间序列中的值,那么我们可以认为这个时刻的操作属于异常的;如果是将异常值检测用于数据预处理阶段,处理方法有以下四种:
- 删除带有异常值的数据;
- 将异常值视为缺失值,交给缺失值处理方法来处理;
- 用平均值进行修正;
- 当然我们也可以选择不处理。
四.基于密度的异常检测
基于密度的异常检测有一个先决条件,即正常的数据点呈现"物以类聚"的聚合形态,正常数据出现在密集的邻域周围,而异常点偏离较远。对于这种场景,我们可以计算得分来评估最近的数据点集,这种得分可以使用Eucledian距离或其它的距离计算方法,具体情况需要根据数据类型来定:类别型或是数字型。
局部异常因子算法
1.Local Outlier Factor原理
局部异常因子算法,全称Local Outlier Factor(简写LOF)。LOF算法是一种无监督的异常检测方法,它计算给定数据点相对于其邻居的局部密度偏差。每个样本的异常分数称为局部异常因子。异常分数是局部的,取决于样本相对于周围邻域的隔离程度。确切地说,局部性由k近邻给出,并使用距离估计局部密度。通过将样本的局部密度与其邻居的局部密度进行比较,可以识别密度明显低于其邻居的样本,,这些样本就被当做是异常样本点。
算法原理如下:

2.实例Demo
(1)导入数据集。为了方便起见,这里采用了Kaggle里面的Credit Card Fraud Detection作为实验数据集,其中包含492个正样本(异常样本),284315个正常样本(负样本)。首先,我们先导入数据集(注意:creditcard.csv文件在这里下载)。
- import pandas as pd
- import numpy as np
- creditcard_data = pd.read_csv("creditcard.csv")
(2)数据集转换。加载数据集,我们需要将数据集中的特征数据X提取出来,Y作为类别标签,在无监督算法的训练过程中不需要用到,在模型评估阶段再使用。这里不得不吹捧一下pandas,操作起来真的特别方便,代码如下:
- from sklearn.metrics import classification_report, accuracy_score
- from sklearn.neighbors import LocalOutlierFactor
- state = np.random.RandomState(42)
- columns = creditcard_data.columns.tolist()
- columns = [cforc in columnsifc not in ["Class"]]
- target ="Class"
- state = np.random.RandomState(42)
- X = creditcard_data[columns]
- Y = creditcard_data[target]
- X_outliers = state.uniform(low=0, high=1, size=(X.shape[0], X.shape[1]))
(3)模型训练与预测。得到了训练数据之后,下面我们通过条用sklearn的算法库来实现模型的训练和预测。
- classifiers = {
- "Local Outlier Factor":LocalOutlierFactor(n_neighbors=20, algorithm="auto",
- leaf_size=30, metric="minkowski",
- p=2, metric_params=None, contamination=0.01)
- }
- def train_model(clf, train_X):
- #Fit the train data and find outliers
- y_pred = clf.fit_predict(X)
- scores_prediction = clf.negative_outlier_factor_
- returny_pred, clf
- y_pred, clf = train_model(clf=classifiers["Local Outlier Factor"], train_X=X)
(4)模型评估。为了验证LOF算法的准确度,我们可以采用预测的异常数据和真实的异常数据进行比对。注意,通过上述模型预测的结果为1(正常样本)和-1(异常样本),所以在模型评估的时候,需要对预测的label进行转换,具体实现如下:
- def evaluation_model(y_pred, y_label, clf_name):
- """
- y_pred: prediction label
- y_label:truelable
- clf_name: string
- """
- #transform anomaly label
- y_rebuild = [0ify == 1else1fory in y_pred ]
- n_errors = (y_rebuild != Y).sum()
- #Classification Metrics
- print("{}: {}".format(clf_name, n_errors))
- print("Accuracy Score :", accuracy_score(Y, y_rebuild))
- print("Classification Report :")
- print(classification_report(Y, y_rebuild))
- s = y_pred
- evaluation_model(y_pred, Y, clf_name="LOF")
当然,基于密度的还有KNN算法(有监督),kNN是一种简单的非参数化机器学习算法,使用距离来度量相似性进而对数据进行分类,例如Eucledian,Manhattan,Minkowski或Hamming distance等。关于KNN算法,可以参考笔者的另一篇文章:机器学习算法-K最近邻从原理到实现。那么,怎么将KNN应用到异常检测中呢?比较简单的做法是计算预测数据与最近的K个样本点的距离和,然后根据阈值进行异常样本的判别。这类方法有一种明显的缺点,如果异常样本数据较多,并且单独成簇的话,最后得到的结果则不太乐观。
五.基于聚类的异常检测
通常,类似的数据点往往属于相似的组或簇,由它们与局部簇心的距离决定。正常数据距离簇中心的距离要进,而异常数据要原理簇的中心点。聚类属于无监督学习领域中最受欢迎的算法之一,关于聚类异常检测可分为两步:
- 利用聚类算法聚类;
- 计算各个样本点的异常程度:每个点的异常程度等于到最近类中心点的距离。
缺点:
- 如果异常数据自己成簇,将难以区分异常;
基于K-Means聚类的异常检测
K-Means是一种广泛使用的聚类算法,它创建了k个类似的数据点群体,不属于这些簇(远离簇心)的数据样例则有可能被标记为异常数据。关于聚类的原理,可参考笔者以前的文章机器学习算法-K-means聚类。
聚类算法较多,如DBSCAN、层次聚类等,这里就不一一介绍了。
六.OneClassSVM的异常检测
1.原理
SVM(支持向量机)是一种用于检测异常的另一种有效的技术。SVM通常与监督学习相关联,但是存在可以用于将异常识别为无监督问题(其中训练数据未被标记)的扩展(OneClassCVM)。算法学习软边界以便使用训练集对正常数据实例进行聚类,然后,使用测试实例,它调整自身以识别落在学习区域之外的异常。根据使用情况,异常检测器的输出可以是数字标量值,用于过滤特定于域的阈值或文本标签(如二进制/多标签)。
2.实例
本实例使用的数据与Local Outlier Factor一样,这里暂且不重复写入了。下面,简单介绍下OneClassSVM算法模型训练部分,其余的与上述类似。代码如下:
- classifiers = {
- "Support Vector Machine":OneClassSVM(kernel="rbf", degree=3, gamma=0.1,nu=0.05,
- max_iter=-1, random_state=state)
- }
- def train_model(clf, train_X):
- #Fit the train data and find outliers
- clf.fit(X)
- y_pred = clf.predict(X)
- returny_pred,clf
- y_pred,clf = train_model(clf=classifiers["Support Vector Machine"], train_X=X)
SVM训练时间较长,具体效果需要看算法与数据集的拟合程度。
七.iForest异常检测
1.原理
iForest(isolation forest,孤立森林)算法是一种基于Ensemble的快速异常检测方法,具有线性时间复杂度和高精准度,该算法是刘飞博士在莫纳什大学就读期间由陈开明(Kai-Ming Ting)教授和周志华(Zhi-Hua Zhou)教授指导发表的,与LOF、OneClassSVM相比,其占用的内存更小、速度更快。算法原理如下:

异常score计算公式如下:

2.实例
这里简单介绍下iForest模型训练部分,数据加载和模型评估的方法与上述类似。算法部分的代码如下:
- classifiers = {
- "Isolation Forest":IsolationForest(n_estimators=100, max_samples=len(X),
- contamination=0.005,random_state=state, verbose=0)
- }
- def train_model(clf, train_X):
- #Fit the train data and find outliers
- clf.fit(X)
- #scores_prediction = clf.decision_function(X)
- y_pred = clf.predict(X)
- returny_pred, clf
- y_pred,clf = train_model(clf=classifiers["Isolation Forest"], train_X=X)
使用上面的参数在笔者的笔记本上训练时间只花了1min 12s,相比于SVM的确要快很多。
八.PCA+MD异常检测

九.AutoEncoder异常检测
AutoEncoder(自编码器,简称AE)是一种无监督的深度学习模型,原理比较简单:对于输入样本x,首先通过encoder编码器ff将其压缩为维度较低的y,然后通过decoder解码器g对每个样本点进行重建,还原到原来的维度,得到z。整个训练模型的目的就是减少重构error,得到的hidden层的y,相当于降维后的数据。整个framework如下:
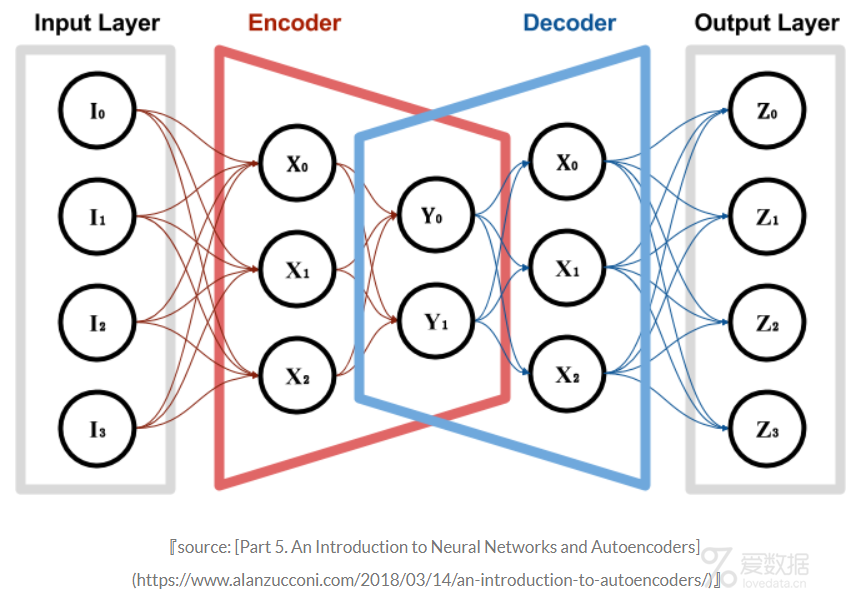
AutoEncoder本质上与PCA类似,AutoEncoder可以用作降维,区别在于PCA属于线性变换,而AutoEncoder属于非线性变换。在异常检测应用上,AE通过计算重建数据与输入数据的重建误差作为异常的衡量,如果样本都是数值型,可以用MSE或MAE作为衡量指标,样本的重建误差越大,则表明异常的可能性越大。关于如何使用autoEncoder,这里暂且不介绍了,后续可能会单独写一篇。
十Conclusion
本文介绍了八种常用的无监督异常检测方法,主要偏向于理论的说明,对于有label标记的数据,我们还可以采用分类算法进行训练和预测,这里就不横向扩宽了。实际项目中,前期标注数据比较少,我们可以采用无监督方式,随着标注数据的增多,后面可以使用监督学习方法,并将无监督与有监督进行结合。OK,这篇文章暂且到此为止,后续相关的实践,笔者也会逐步分享出来,感谢光顾。
十一.References
- Explaining the 68-95-99.7 rule for a Normal Distribution
- how-to-use-machine-learning-for-anomaly-detection-and-condition-monitoring
- WIKI:Mahalanobis_distance
- credit-card-fraud-detection-using-autoencoders-in-keras-tensorflow-for-hackers-part-vii
- creditcardfraud/kernels
- Isolation Forest
- Isolation-based Anomaly Detection
- Outlier Detection with Isolation Forest
- Outlier Analysis-pdf
- Introduction to autoencoders
End.
作者:拾毅者
来源:『刘帝伟』维护的个人技术博客
本文均已和作者授权,如转载请与作者联系。
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论