
简介
C++98/03的设计目标:
1.比C语言更适合系统编程(且与C语言兼容)。
2.支持数据抽象。
3.支持面向对象编程。4.支持泛型编程。(C++模板使得C++近乎成为了一种函数式编程语言,而且使得C++程序员拥有了模板元编程的能力。)
相比之下,C++11的整体设计目标如下:1.使得C++成为更好的适用于系统开发及库开发的语言。2.使得C++成为更易于教学的语言(语法更加一致化和简单化)。3.保证语言的稳定性,以及和C++03及C语言的兼容性。
(如果说C++11只是对C++语言做了大幅度的改进,那么就很有可能错过了C++11精彩的地方。就是要做到,读完这本书之后,只需要看一眼,就可以说出代码是C++98/03的,还是C++11的)。
我想要的,就是C++11为程序员创造了很多更有效、更便捷的代码编写方式,程序员可以用简短的代码来完成C++98/03中同样的功能,简单到你会说"竟然这么简单"。比起C++98/03,C++11大大缩短了代码编写量,最多可以将代码缩短30%~80%。
C++11相对C++98/03有哪些显著的增强呢?包括以下几点:一、通过内存模型、线程、原子操作等来支持本地并行编程(Native Concurrency)。二、通过统一初始化表达式、auto、declytype、移动语义等来统一对泛型编程的支持。三、通过constexpr、POD(概念)等更好地支持系统编程。四、通过内联命名空间、继承构造函数和右值引用等,以更好地支持库的构建。
(C++11像是个恐怖的"编程语言范型联盟"。利用它不仅仅可以写出面向对象的代码,也可以写出过程式编程语言代码、泛型编程语言代码、函数式编程语言代码、元编程编程语言代码,或者其他。多范型的支持使得C++11语言的"硬实力"几乎在编程语言中"无出其右")
程序员需要抽象出的不仅仅是对象,还有一些其他的概念,比如类型、类型的类型、算法、甚至是资源的生命周期,这些实际上都是C++语言可以描述的。在C++11中,这些抽象概念常常被实现在库中,其使用将比在C++98/03中更加方便,更加好用。
(C++11是一种所谓的"轻量级抽象编程语言")总的来说,灵活的静态类型、小的抽象概念、绝佳的时间与空间运行性能,以及 与硬件紧密结合工作的能力 都是C++11突出的亮点。
WG21更专注的特性(我比较关注的)1、更倾向于使用库而不是扩展语言来实现特性。2、更倾向于通用的而不是特殊的手段来实现特性。3、增强代码执行性能和操作硬件的能力。4、开发能够改变人们思维方式的特性5、融入编程现实
Mayers根据C++11的使用者是类的使用者,还是库的使用者,或者特性是广泛使用的,还是库的增强的来区分各个特性。具体地,可以把特性分为以下几种:A 类作者需要的(class writer, 简称为 "类作者")B 库作者需要的(library writer, 简称为 "库作者")C 所有人需要的(everyone, 简称为 "所有人")D 部分人需要的(everyone else, 简称为 "部分人")
保证稳定性和兼容性
保持与C99兼容
(这里有些库不是特别懂,我们慢慢来)
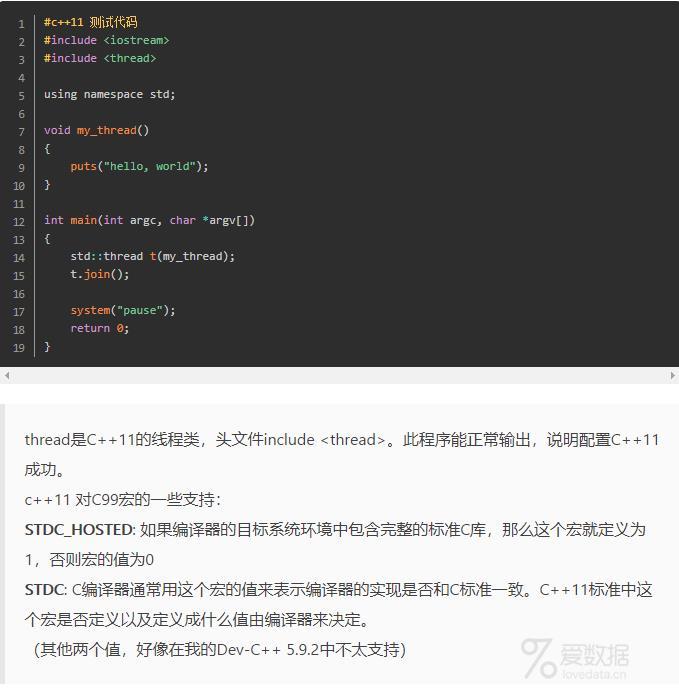
预定义宏对于多目标平台代码的编写通常具有重大意义。通过以上的宏,程序员通过使用#ifdef/#endif等预处理命令,就可使得平台相关代码只适合于当前平台的代码上编译,从而在同一套代码中完成对多平台的支持。(通过这个预处理命名,就可以让一些头文件中的代码在只适合当前平台的情况下进行编译。)
相关博客:[C++中#if #ifdef的作用][1]例如:

值得注意的是,与所有的预定义宏相同的,如果用户重定义(#define)或#undef了预定义的宏,那么后果是"未定义"的。因此在代码编写中,程序员应该注意避免自定义宏与预定义宏同名的情况。
(那么问题是:什么是预定义宏,这个预定义宏有什么用)
答案:预定义宏,就是事先已经定义好的宏。一般分为两类:标准预定义宏,编译器预定义宏。有两个特性:
- 无需提供他们的定义,就可以直接使用。
- 预定义宏没有参数,且不可被重定义。
1.标准预定义宏(Standard Predefined Macros)标准预定义宏由相关语言标准指定。因此所有该标准的编译器都可以使用这些宏。ANSI C指定了以下预定义宏:
- _FILE_ 在源文件中插入当前源文件名;
- _LINE_ 在源代码中插入当前源代码行号;
- _DATE_ 在源文件中插入当前的编译日期;
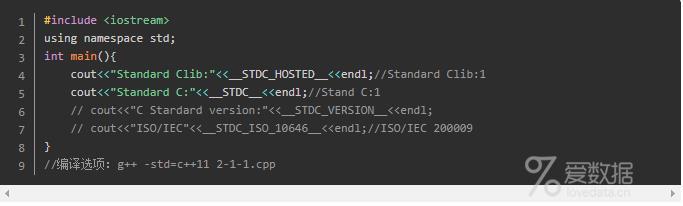
- _STDC_ 当要求程序严格遵循ANSI C标准时该标识被赋值为1,表明是标准的C程序;
- _TIME_ 在源文件中插入当前编译时间;
- _TIMESTAMP_ The date and time of the last modification of the current source file, expressed as a string literal in the form Ddd Mmm Date hh:mm:ss yyyy, where Ddd is the abbreviated day of the week and Date is an integer from 1 to 31.

![QQ截图20151107172832.jpg-72.1kB][2]
(C99在_FILE、_LINE的之外,引入了_func_与之配合。注意func并不是宏)
2.编译器预定义宏(GNU-, Microsoft-Specific Predefined Macros)这部分的宏是由编译器指定的,是对标准预定义宏的拓展。如GCC和VC++都有自己预定于的宏。
ps: 编译器预定义宏,也有部分实际上不是真正的宏。拿VC++来说,可以验证的,_MSC_VER是宏,FUNCDNAME不是宏。(预定义宏是很有用的,比如你要输出日期,时间,文件名,函数名等等,都要用到它。预定义宏的使用比较简单,网上可以找到很多介绍文章,特别是标准预定义宏。)
个人理解,就像我写PHP一样,会有些可以直接调用的方法,这些方法基本上是PHP已经定义过的。
很多现实的编译器都支持C99标准中的_func_预定义标识符功能,其基本功能就是返回所在函数的名字。
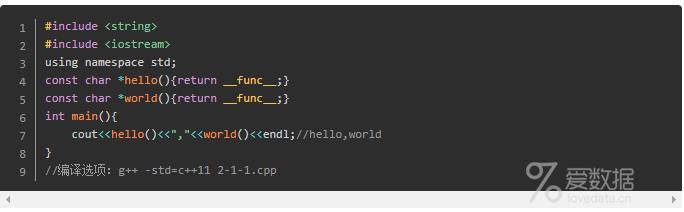
事实上,按照标准定义,编译器会隐式地在函数的定义之后定义_func_标识符。比如上述例子中的hello函数,其实际的定义等同于如下代码:

_func_ 预定义标识符对于轻量级的调试代码具有十分重要的作用。而在C++11中,标准甚至允许其使用在类或者结构体中。(问题是:_func_怎样去调试代码)
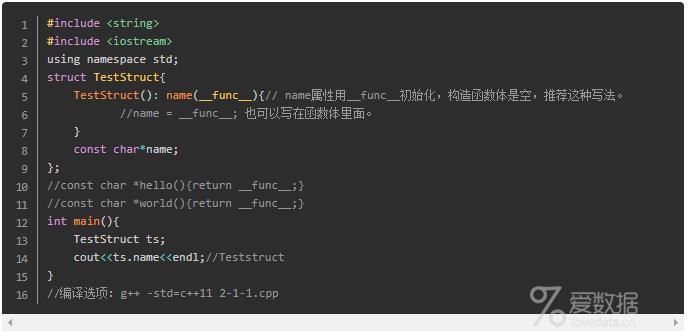
在结构体的构造函数中,初始化成员列表使用func预定义标识符是可行的,其效果跟在函数中使用一样。不过将fun标识符作为函数参数的默认值是不允许的,如下例所示:

(这是由于在参数声明时,func还未被定义)
问题:在结构体中是否可以声明函数?答案:C++中结构体可以定义一个函数 C中的结构体和C++中结构体的不同之处:在C中的结构体只能自定义数据类型,结构体中不允许有函数,而C++中的结构体可以加入成员函数。
C++中的结构体和类的异同:1.相同之处:结构体中可以包含函数;也可以定义public、private、protected数据成员;定义了结构体之后,可以用结构体名来创建对象。但C中的结构体不允许有函数;也就是说在C++当中,结构体中可以有成员变量,可以有成员函数,可以从别的类继承,也可以被别的类继承,可以有虚函数。
2.不同之处:结构体定义中默认情况下的成员是public,而类定义中的默认情况下的成员是private的。类中的非static成员函数有this指针,类的关键字class能作为template模板的关键字 即template<class T> class A{}; 而struct不可以。
实际上,C中的结构体只涉及到数据结构,而不涉及到算法,也就是说在C中数据结构和算法是分离的,而到C++中一类或者一个结构体可以包含函数(这个函数在C++我们通常中称为成员函数),C++中的结构体和类体现了数据结构和算法的结合。
扩展:C++结构体相关知识C++结构体提供了比C结构体更多的功能,如默认构造函数,复制构造函数,运算符重载,这些功能使得结构体对象能够方便的传值。
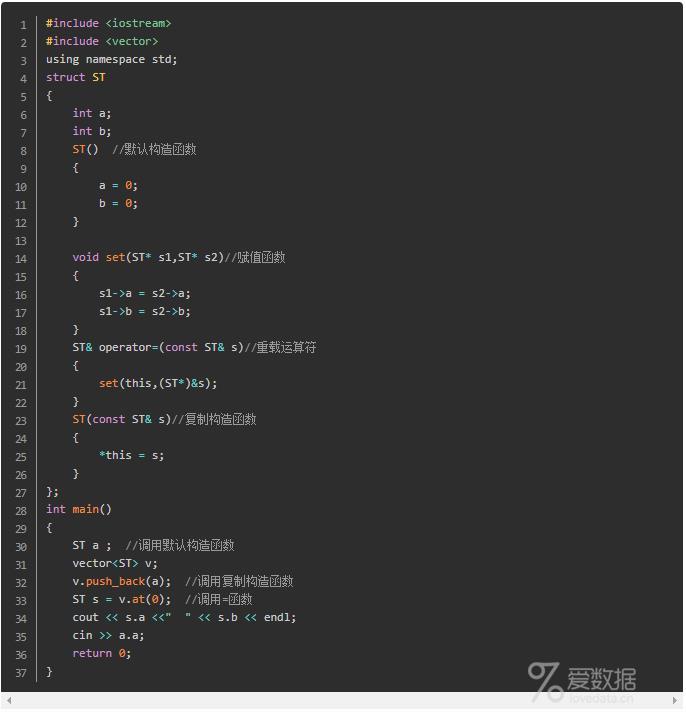
_Pragma 操作符在C/C++标准中,#pragma是一条预处理的指令。简单地说,#pragma是用来向编译器传达语言标准以外的一些信息。

在C++11中,标准定义了与预处理指令#pragma 功能相同的操作符_Pragma, 因为是操作符,所以,可以用于宏中. _Pragma操作符的格式如下所示:

变长参数的宏定义以及VA_ARGS变长参数的宏定义是指在宏定义中参数列表的最后一个参数为省略号,而预定义宏VA_ARGS则可以在宏定义的实现部分替换省略号所代表的字符串:
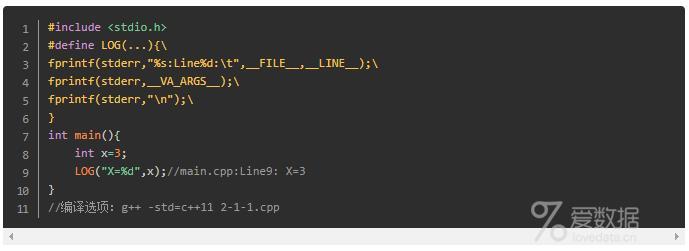
关于 stdout、stderrstderr -- 标准错误输出设备stdout -- 标准输出设备 (printf("..")) 同 stdout。
如果输入到文件中,stderr 是不显示的。只有stdout和print才会显示。上面代码将stderr 改为 stdout 也是可以的,一样能输出。
程序员可以根据stderr产生的日志追溯到代码中产生这些记录的位置。引入这样的特性,对于轻量级调试,简单的错误输出都是具有积极意义的。
在之前的C++标准中,将窄字符串(char)转换成宽字符串(wchar_t)是未定义的行为。而在C++11标准中,在将窄字符串和宽字符串进行连接时,支持C++11标准的编译器会将窄字符串转换为宽字符串,然后再与宽字符串进行连接
long long整型
C++11整型的最大改变就是多了 long long。分为两种:long long 和unsigned long long。在C++11中,标准要求long long 整型可以在不同平台上有不同的长度,但至少有64位。我们在写常数字面量时,可以使用LL后缀(或是ll)标识一个long long 类型的字面量,而ULL (或ull、Ull、uLL) 表示一个unsigned long long 类型的字面量。比如:

对于有符号的,下面的类型是等价的:long long、signed long long、long long int、signed long long int; 而unsigned long long 和 unsigned long long int 也是等价的。要了解平台上long long大小的方法就是查看<climits>(或<limits.h>中的宏)。与 long long 整型相关的一共有3个:LLONG_MIN、LLONG_MAX 和ULLONG_MAX, 它们分别代表了平台上最小的long long 值、最大的long long 值,以及最大的unsigned long long 值。
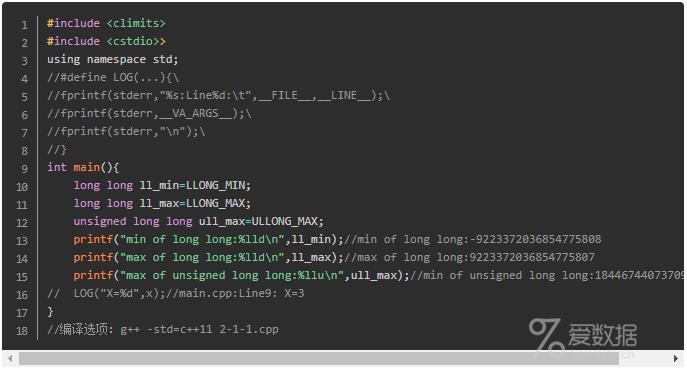
18446744073709551615 用16进制表示是0xFFFFFFFFFFFFFFFF(16个F),所以,在我们的实验机上,long long 是一个64位的类型。
扩展的整型
有些整型的名字如:UINT、__int16、u64、int64_t, 等等。这些类型有的源自编译器的自行扩展,有的则来自某些编程环境(比如工作在Linux内核代码中)。事实上,在C++11中一共只定义了以下5种标准的有符号整型:
- signed char
- short int
- int
- long int
- long long int
标准同时规定,每一种有符号整型都有一种对应的无符号整数版本,且有符号整型与其对应的无符号整型具有相同的存储空间大小。
在实际的编程中,由于这5种基本的整型适用性有限,所以有时编译器出于需要,也会自行扩展一些整型。在C++11中,标准对这样的扩展做出了一些规定。具体地讲,除了标准整型之外,C++11标准允许编译器扩展自有的所谓扩展整型。这些扩展整型的长度(占用内存的位数)可以比最长的标准整型(long long int, 通常是一个64位长度的数据)还长,也可以介于两个标准整数的位数之间。
C++11规定,扩展的整型必须和标准类型一样,有符号类型和无符号类型占用同样大小的内存空间。而由于C/C++是一种弱类型语言,当运算、传参等类型不匹配的时候,整型间会发生隐式的转换,这种过程通常被称为整型的提升,比如:

通常就会导致变量(int)a被提升为long long类型后才与(long long)b 进行运算。而无论是扩展的整型还是标准的整型,其转化的规则会由它们的"等级"决定。通常情况下:有如下原则:
- 长度越大的整型等级越高,比如long long int的等级会高于int。
- 长度相同的情况下,标准整型的等级高于扩展类型,比如long long int和_int64如果都是64位长度,则longlong int类型的等级更高。
- 相同大小的有符号类型和无符号类型的等级相同,long long int 和unsigned long long int的等级就相同。
而在进行隐式的整型转换的时候,一般是按照低等级整型转换为高等级整型,有符号的转换为无符号。这种规则跟C++98的整型转换规则是一致的。
如果编译器定义一些自有的整型,即使这样自定义的整型由于名称并没有被标准收入,因而可移植性并不能得到保证,但至少编译器开发者和程序员不用担心自定义的扩展整型与标准整型间在使用规则上(尤其是整型提升)存在不同的认识了。
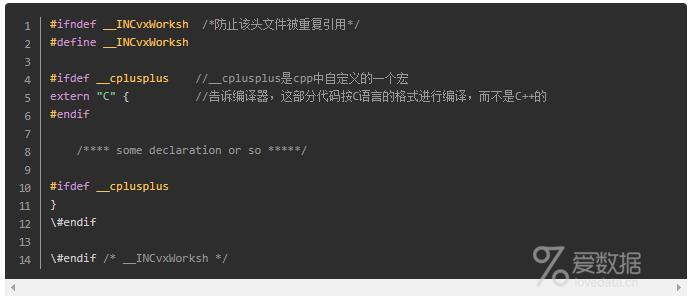
宏__cplusplus
在C和C++混合编写的代码中可以看到:

这种类型的头文件可以被#include到C文件中进行编译,也可以被#include到C++文件中进行编译。由于extern "C"可以抑制C++对函数名、变量名等符号(symbol)进行名称重整(name mangling), 因此编译出的C目标文件和C++目标文件中的变量、函数名称等符号都是相同的(否则不相同),链接器可以可靠地对两种类型的目标文件进行连接。这样该做法成为了C与C++混用头文件的典型做法。
事实上,__cplusplus这个宏通常被定义为一个整型值。而随着标准变化,__cplusplus宏一般会是一个比以往标准中更大的值。在C++11标准中,宏__cplusplus被预定义为201103L。比如程序员在想确定代码是使用支持C++11编译器进行编译时,那么可以按下面的方法进行检测:
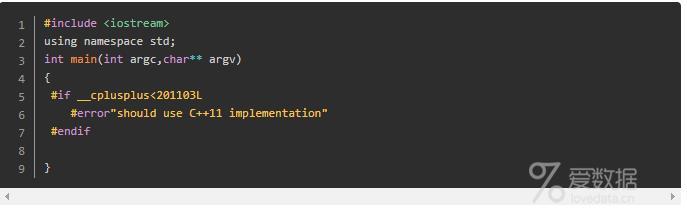
预处理指令#error,使得不支持C++11的代码编译立即报错并终止编译。
extern "C"用法解析extern "C"的主要作用就是为了能够正确实现C++代码调用其他C语言代码。加上 extern "C"后,会指示编译器这部分代码按C语言的进行编译,而不是C++的。由于C++支持函数重载,因此编译器编译函数的过程中会将函数的参数类型也加到编译后的代码中,而不仅仅是函数名;而C语言并不支持函数重载,因此编译C语言代码的函数时不会带上函数的参数类型,一般之包括函数名。
标准头文件
1、extern关键字extern是C/C++语言中表明函数和全局变量作用范围(可见性)的关键字,该关键字告诉编译器,其声明的函数和变量可以在本模块或其它模块中使用。
通常,在模块的头文件中对本模块提供给其它模块引用的函数和全局变量以关键字extern声明。例如,如果模块B欲引用该模块A中定义的全局变量和函数时只需包含模块A的头文件即可。这样,模块B中调用模块A中的函数时,在编译阶段,模块B虽然找不到该函数,但是并不会报错;它会在链接阶段中从模块A编译生成的目标代码中找到此函数。
与extern对应的关键字是static,被它修饰的全局变量和函数只能在本模块中使用。因此,一个函数或变量只可能被本模块使用时,其不可能被extern "C"修饰。
2、被extern "C"修饰的变量和函数是按照C语言方式编译和链接的首先看看C++中对类似C的函数是怎样编译的。
作为一种面向对象的语言,C++支持函数重载,而过程式语言C则不支持。函数被C++编译后在符号库中的名字与C语言的不同。例如,假设某个函数的原型为:
void foo( int x, int y );
该函数被C编译器编译后在符号库中的名字为_foo,而C++编译器则会产生像_foo_int_int之类的名字(不同的编译器可能生成的名字不同,但是都采用了相同的机制,生成的新名字称为"mangled name")。
_foo_int_int这样的名字包含了函数名、函数参数数量及类型信息,C++就是靠这种机制来实现函数重载的。 例如,在C++中,函数void foo( int x, int y )与void foo( int x, float y )编译生成的符号是不相同的,后者为_foo_int_float。
同样地,C++中的变量除支持局部变量外,还支持类成员变量和全局变量。用户所编写程序的类成员变量可能与全局变量同名,我们以"."来区分。而本质上,编译器在进行编译时,与函数的处理相似,也为类中的变量取了一个独一无二的名字,这个名字与用户程序中同名的全局变量名字不同。
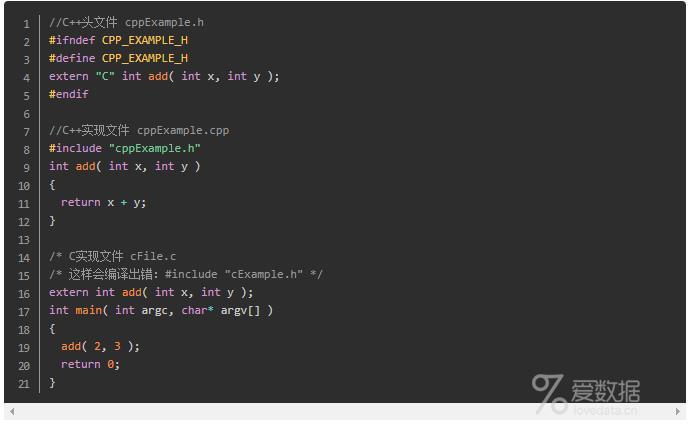
extern "C"这个声明的真实目的是为了 实现C++与C及其它语言的混合编程。应用场合:
- C++代码调用C语言代码,在C++的头文件中使用 (而在C语言的头文件中,对其外部函数只能指定为extern类型,C语言中不支持extern "C"声明,在.c文件中包含了extern "C"时会出现编译语法错误。)
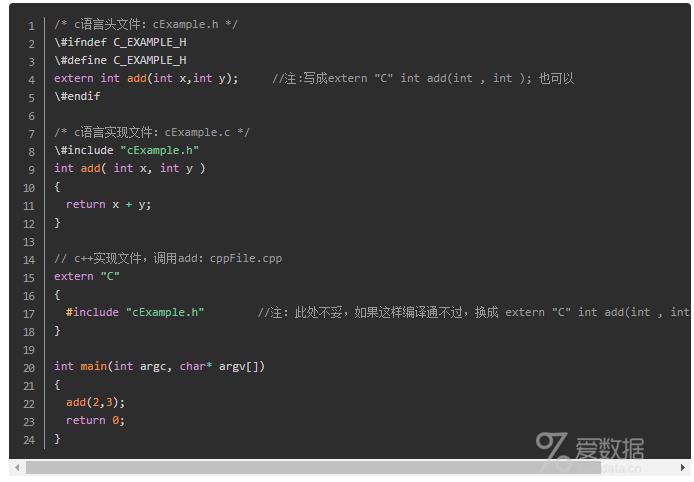
如果C++调用一个C语言编写的.DLL时,当包括.DLL的头文件或声明接口函数时,应加extern "C"{}。
- 在C中引用C++语言中的函数和变量时,C++的头文件需添加extern "C",但是在C语言中不能直接引用声明了extern "C"的该头文件,应该仅将C文件中将C++中定义的extern "C"函数声明为extern类型
静态断言
断言:运行时与预处理时
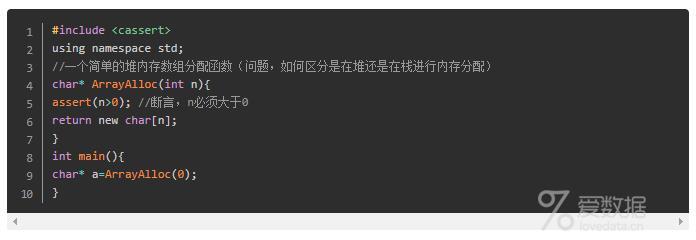
断言就是将一个返回值总是需要为真的判别式放在语句中,用于排除在设计的逻辑上不应该产生的情况。比如一个函数总需要输入在一定的范围内的参数,那么就可以对该参数使用断言,以迫使在该参数发生异常的时候程序退出,从而避免程序陷入逻辑的混乱。
在C++中,标准在<cassert>或<assert.h>头文件中为程序员提供了assert宏,用于在运行时进行断言。
(宏:C++ 宏定义将一个标识符定义为一个字符串,源程序中的该标识符均以指定的字符串来代替。前面已经说过,预处理命令不同于一般C++语句。因此预处理命令后通常不加分号。这并不是说所有的预处理命令后都不能有分号出现。由于宏定义只是用宏名对一个字符串进行简单的替换,因此如果在宏定义命令后加了分号,将会连同分号一起进行置换。)
接着,可以定义宏NDEBUG来禁用assert宏。这对发布程序来说还是必要的。assert宏在<cassert>中的实现方式类似于下列形式:

一旦定义了NDEBUG宏,assert宏将被展开为一条无意义的C语句(通常会被编译器优化掉)。
通过预处理指令#if和#error的配合,也可以让程序员在预处理阶段进行断言。比如GNU的cmathcalls.h头文件中,我们会看到如下代码:

如果程序员直接包含头文件<bits/cmathcalls.h>并进行编译,就会引发错误。#error指令会将后面的语句输出,从而提醒用户不要直接使用这个头文件,而应该包含头文件<complex.h>.这样一来,通过预处理时的断言,库发布者就可以避免一些头文件的引用问题。
(断言assert宏只有在程序运行时才能起作用。而#error只在编译器预处理时才能起作用。)有的时候,我们希望在编译时能做一些断言。
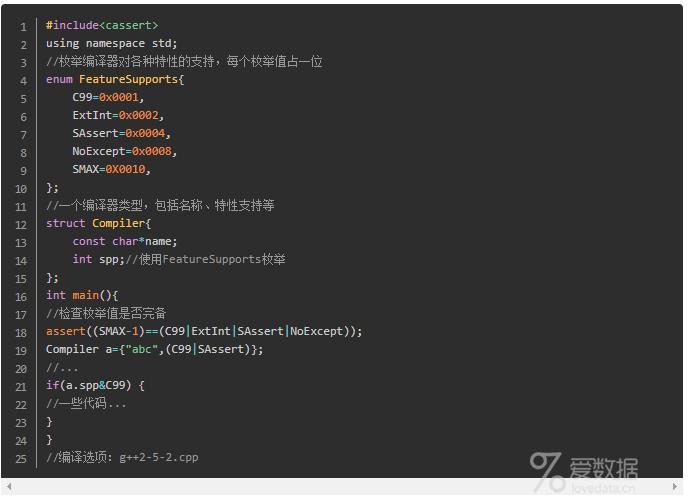
我们编写了一个枚举类型FeatureSupports,用于列举编译器对各种特性的支持。而结构体Compiler则包含了一个int类型spp。由于各种特性都具有"支持"和"不支持"两种状态,所以,为了节省空间,我们让每个FeatureSupport的枚举值占据一个特定的比特位置,并在使用时通过"或"运算压缩地存储在Compiler的spp成员中(即bitset的概念)。在使用时则可以通过检查spp的某位来判断编译器对特性是否支持。
这样的枚举值非常多,而且还会在代码维护中不断增加。那么代码编写者必须想出办法来对这些枚举进行校验,比如查验是否有重位等。(在本例中程序员的做法是使用一个"最大枚举" SMAX,并通过比较SMAX-1与其他枚举的或运算值来验证是否有枚举值重位)。
assert是一个运行时的断言,意味着不运行程序我们将无法得知是否有枚举重位。在一些情况下,这是不可接受的,因为可能单次运行代码并不会调用到assert相关的代码路径。因此这样的校验最好是在编译时期就能完成。
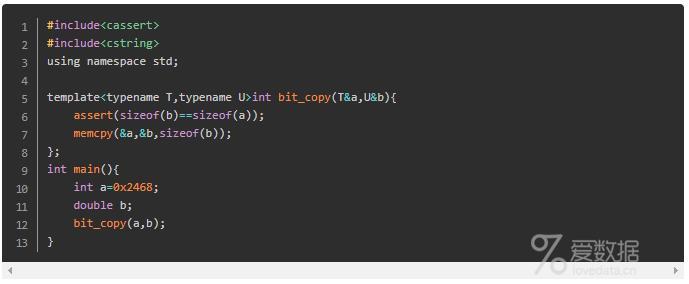
assert是要保证a和b两种类型的长度一致,这样bit_copy才能够保证复制操作不会遇到越界等问题。我们还是使用assert的这样的运行时断言,但如果bit_copy不被调用,我们将无法触发该断言。实际上,正确产生断言的时机应该是模板实例化时,即编译时期。
他们的解决方法就是进行编译时期的断言,即所谓的"静态断言"。事实上,利用语言规则实现静态断言的讨论非常多,比如典型的实现是开源库Boost内置的BOOST_STATIC_ASSERT断言机制(利用sizeof操作符)。我们可以利用"除0"会导致编译器报错这个特性来实现静态断言。
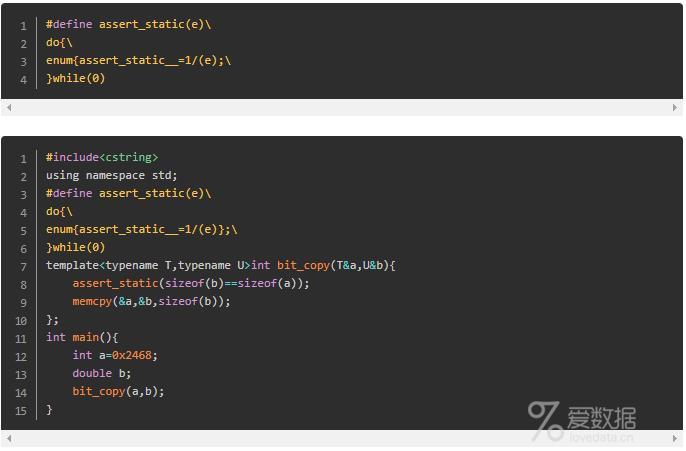
无论哪种方式的静态断言,其缺陷都是很明显的:诊断信息不够充分,不熟悉该静态断言实现的时候,可能一时无法将错误对应到断言错误上,从而难以准确定位错误的根源。
在C++11标准中,引入了static_assert断言来解决这个问题。static_assert使用起来非常简单,接收两个参数,一个是断言表达式,这个表达式通常需要返回一个bool值;一个则是警告信息,通过也就是一段字符串。我们可以用static_assert进行替换。

总代码:
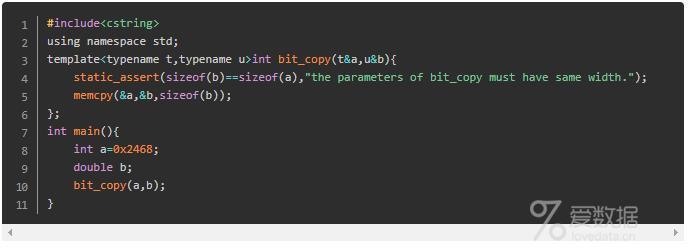
[Error] static assertion failed: the parameters of bit_copy must have same width.
这种错误非常清楚,也有利于程序员排错。而由于static_assert是编译时候时期的断言,其使用范围不像assert一样受到限制。在通常情况下,static_assert可以用于任何名字空间。
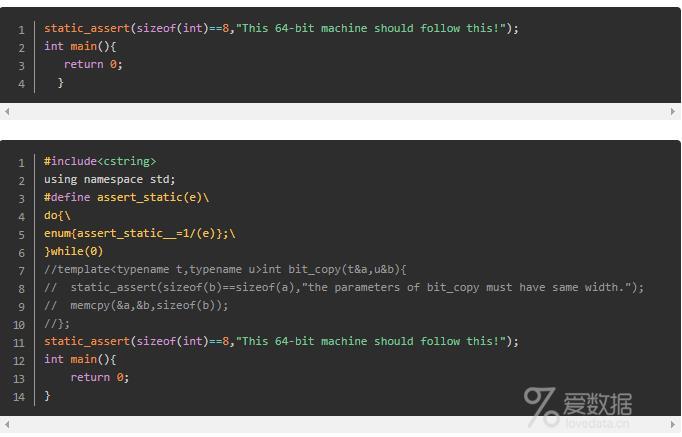
将static_assert写在函数体外通常是较好的选择,让代码阅读者比较容易发现static_assert为断言而非用户定义的函数。反过来讲,必须注意的是,static_assert的断言表达式的结果必须是在编译时期可以计算的表达式,即必须是常量表达式。
而如果有变量存在,且只需要运行时的检查,那么还是应该使用assert宏。
noexcept修饰符与noexcept操作符
相比于断言适应于排除逻辑上不可能存在的状态,异常通常是用于逻辑上可能发生的错误。在C++98中,我们看到了一整套完整的不同于C的异常处理系统。

在excpt_func函数声明之后,我们定义了一个动态异常声明throw(int,douuble),该声明指出了excpt_func可能抛出的异常的类型。但是该函数被弃用了。而表示函数不会抛出异常的动态异常声明throw() 也被新的noexcept异常声明所取代。
noexcept表示其修饰的函数不会抛出异常。不过与throw()动态异常不同的是,在C++11中如果noexcept修饰的函数抛出了异常,编译器可以选择直接调用std:: terminate() 函数来终止程序的运行,比基于异常机制的throw()在效率上高一些。

常量表达式的结果会被转换成一个Bool类型的值。该值为true,表示函数不会抛出异常,反之,则有可能抛出异常。这里不带常量表达式的noexcept相当于声明了noexcept(true)
在通常情况下,在C++11中使用noexcept可以有效地阻止异常的传播与扩散。
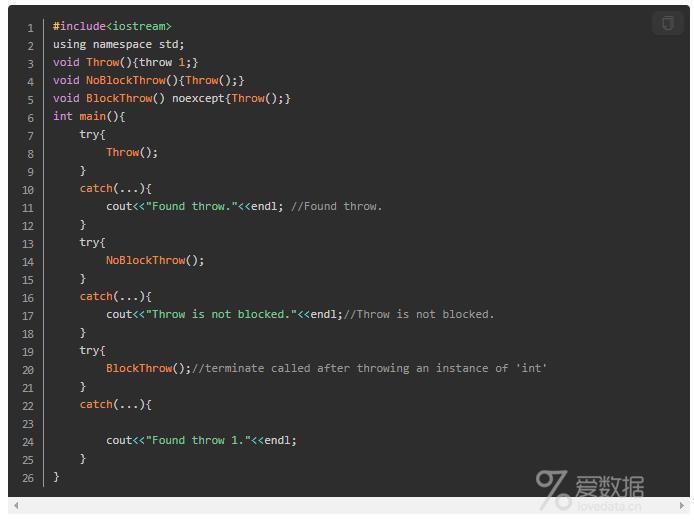
结果:
![jietu2.jpg-69.7kB][7]
我们定义了Throw函数,该函数的唯一作用是抛出一个异常。而NoBlockThrow是一个调用Throw的普通函数,BlockThrow则是一个noexcept修饰的函数。从main的运行中我们可以看到,NoBlockThrow会让Throw函数抛出的异常继续抛出,直到mian中的catch语句将其捕捉。而BlockThrow则会直接调用std::terminate中断程序的执行,从而阻止了异常的继续传播。
而noexcept作为一个操作符时,通常可以用于模板。比如:

这里,fun函数是否是一个noexcept的函数,将由T() 表达式是否会抛出异常所决定。这里的第二个noexcept就是一个noexcept操作符。当其参数是一个有可能抛出异常的表达式的时候,其返回值为false,反之为true。这样一来,我们就可以使模板函数根据条件实现noexcept修饰的版本或无noexcept修饰的版本。从泛型编程的角度看来,这样的设计保证了关于"函数是否抛出异常" 这样的问题可以通过表达式进行推导。
作者:我是小居居
来源:简书
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论