
# 导入 pandas 模块import pandas as pd
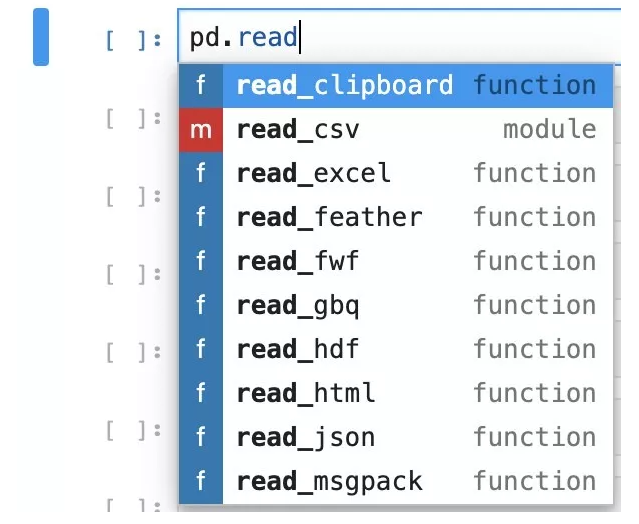
pd.*read*?
# 导入 Excel 文件df = pd.read_excel("文件名.xlsx")# 查询帮助文档pd.read_excel?
# 查询帮助文档和源代码pd.read_excel??
# 安装或更新 pymysql!pip3 install --upgrade pymysql# 从 sqlalchemy 导入创建引擎的功能from sqlalchemy import create_engine# 建立数据库连接,替换其中的用户名、密码、主机地址、端口、数据库名con = create_engine("mysql+pymysql://root:xxxxxx@192.168.0.1:3306/testdb")# 写 SQL 语句sql = "SELECT * FROM table"# 读取数据df = pd.read_sql(sql, con)df.head()
# 从 sqlalchemy 导入创建引擎的功能from sqlalchemy import create_engine# 建立数据库连接,替换其中的用户名、密码、主机地址、端口、数据库名db_info = open("password/root@mysql.txt")con = create_engine(db_info.read())# 写 SQL 语句sql = "SELECT * FROM table"# 读取数据df = pd.read_sql(sql, con)df.head()
# 安装或更新 py-postgresql!pip3 install --upgrade py-postgresql# 从 sqlalchemy 导入创建引擎的功能from sqlalchemy import create_engine# 建立数据库连接,替换其中的用户名、密码、主机地址、端口、数据库名con = create_engine("postgres://linjiwx:xxxxxx@192.168.0.2:5432/testdb")# 写 SQL 语句sql = "SELECT * FROM table"# 读取数据df = pd.read_sql(sql, con)df.head()类似地,你也可以参考前面介绍过的方法,把密码等敏感信息保存在单独的文件中,我们在这里就不重复演示了。
# 安装或更新 cx_Oracle!pip3 install --upgrade cx_Oracle# 防止中文乱码import osos.environ["NLS_LANG"] = "SIMPLIFIED CHINESE_CHINA.UTF8"# 从 sqlalchemy 导入创建引擎的功能from sqlalchemy import create_engine# 建立数据库连接,替换其中的用户名、密码、主机地址、端口、数据库名con = create_engine("oracle+cx_oracle://system:xxxxxx@192.168.0.3:1521/orcl")# 写 SQL 语句sql = "SELECT * FROM table"# 读取数据df = pd.read_sql(sql, con)
# 为了防止报错:SSLV3_ALERT...import sslssl._create_default_https_context = ssl._create_unverified_context# 网址url = "http://s.askci.com/stock/a/?reportTime=2019-03-31&pageNum=1"# 读取网页中的表格数据dfs = pd.read_html(url)其中 read_html() 函数会读取当前网页的所有表,我们可以用 dfs[0] 获取网页中的第一个表。
End.
爱数据网专栏作者:林骥
作者介绍:数据赋能者,专注数据分析 10 多年。
个人公众号:林骥(linjiwx)
本文为挖数网专栏作者原创文章,未经允许禁止转载,需要转载请微信联系授权(微信号:lovedata0520)
更多文章前往爱数据社区网站首页浏览http://www.itongji.cn/
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论