
import numpy as npimport pandas as pd# 设置最多显示 10 行pd.set_option("max_rows", 10)# 从 Excel 文件中读取原始数据df = pd.read_excel( "待清洗的扑克牌数据集.xlsx")df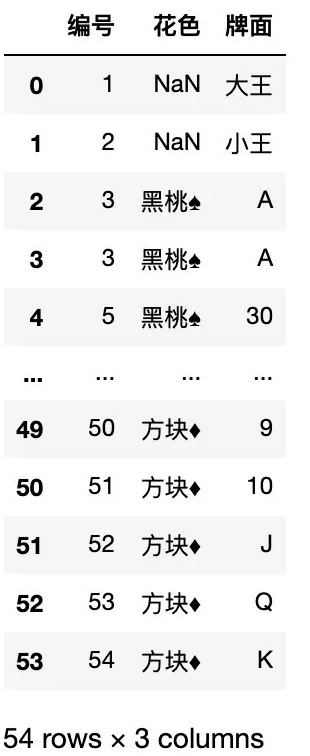
# 查找「花色」缺失的行df[df.花色.isnull()]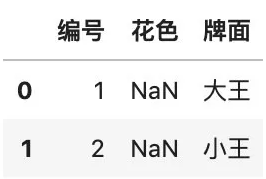
# 查找完全重复的行df[df.duplicated()]
# 查找某一列重复的行df[df.编号.duplicated()]
# 查找牌面的所有唯一值df.牌面.unique()# 查找「牌面」包含 30 的异常值df[df.牌面.isin(["30"])]
# 查找王牌,模糊匹配df[df.牌面.str.contains( "王", na=False)]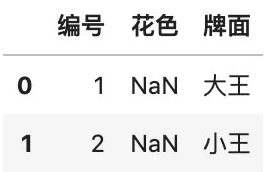
# 查找编号在 1 到 5 之间的行df[df.编号.between(1, 5)]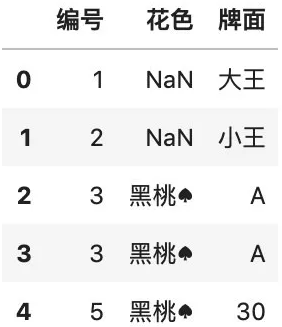
查找某个区间,也可以用逻辑运算的方法来实现:
# 查找编号在 1 到 5 之间的行df[(df.编号 >= 1) & (df.编号 <= 5)]# 查找编号在 1 到 5 之间的行df[~((df.编号 < 1) | (df.编号 > 5))]# 排除完全重复的行,默认保留第一行df.drop_duplicates()

# 排除重复后直接替换原来的数据框df.drop_duplicates( inplace=True)# 排除重复后,重新赋值给原来的数据框df = df.drop_duplicates()
# 按某一列排除重复,默认保留第一行df.drop_duplicates(["花色"])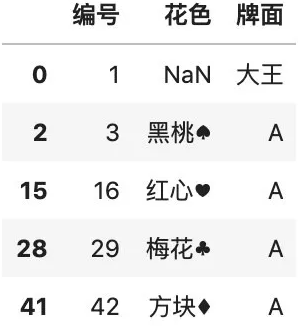
# 按某一列排除重复,并保留最后一行df.drop_duplicates( ["花色"], keep="last")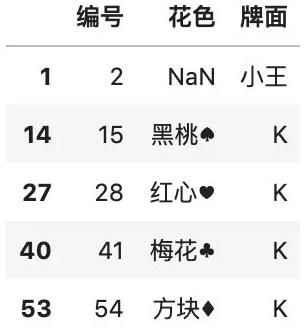
# 不重复的花色color = df.drop_duplicates( ["花色"])color
# 删除包含缺失值的行color.dropna()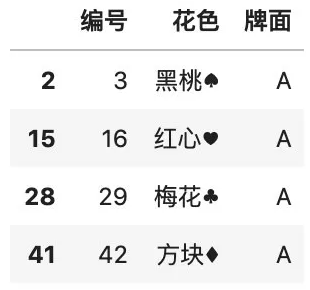
# 删除全部为空的行color.dropna(how="all")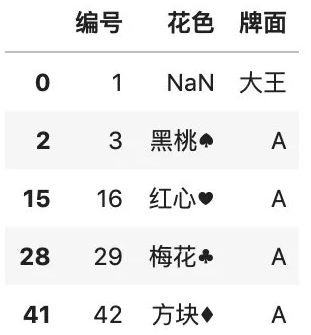
# 删除包含缺失值的列color.dropna(axis=1)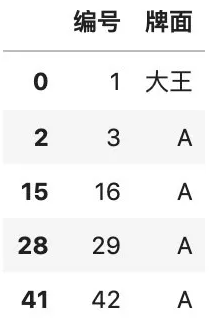
# 补全缺失值color.fillna("Joker")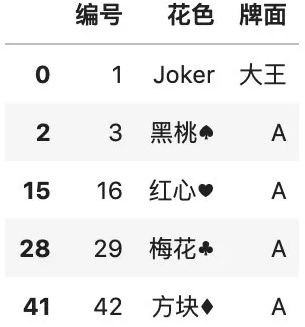
# 用后面的值填充color.fillna(method="bfill")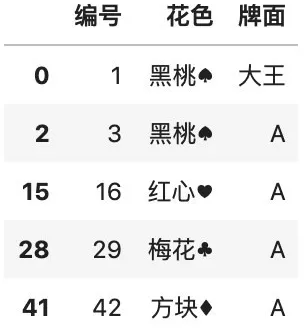
# 为了演示,先指定一个缺失值color.loc[2, "牌面"] = np.nancolor
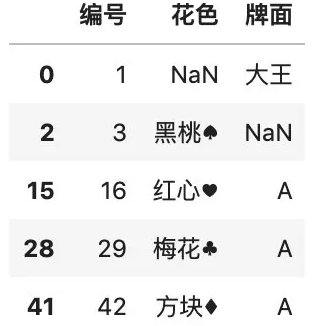
# 按列自定义补全缺失值color.fillna( {"花色": 0, "牌面": 1})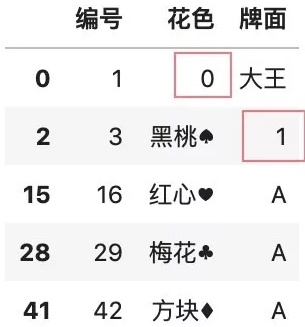
import numpy as npimport pandas as pd# 设置最多显示 10 行pd.set_option("max_rows", 10)# 从 Excel 文件中读取原始数据df = pd.read_excel( "待清洗的扑克牌数据集.xlsx")# 补全缺失值df = df.fillna("Joker")# 排除重复值df = df.drop_duplicates()# 修改异常值df.loc[4, "牌面"] = 3# 增加一张缺少的牌df = df.append( {"编号": 4, "花色": "黑桃♠", "牌面": 2}, ignore_index=True)# 按编号排序df = df.sort_values("编号")# 重置索引df = df.reset_index()# 删除多余的列df = df.drop( ["index"], axis=1)# 把清洗好的数据保存到 Excel 文件df.to_excel( "完成清洗的扑克牌数据.xlsx", index=False)df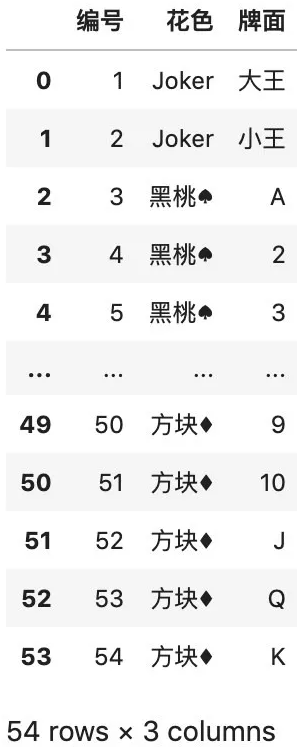
End.
爱数据网专栏作者:林骥
作者介绍:数据赋能者,专注数据分析 10 多年。
个人公众号:林骥(linjiwx)
本文为挖数网专栏作者原创文章,未经允许禁止转载,需要转载请微信联系授权(微信号:lovedata0520)
更多文章前往爱数据社区网站首页浏览http://www.itongji.cn/
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论