
机器学习算法是这样设计的,它们从经验中学习,当它们获取越来越多的数据时,性能就会提高。每种算法都有自己学习和预测数据的方法。在本文中,我们将介绍一些机器学习算法的功能,以及在这些算法中实现的有助于学习过程的一些数学方程。
机器学习算法的类型
机器学习算法大致可以分为以下四类:
监督学习:预测的目标或输出变量是已知的。这些算法生成一个函数,该函数将输入映射到输出变量。回归和分类算法属于这一类。在回归中,输出变量是连续的,而在分类中,输出变量包含两个或更多的离散值。一些监督学习算法包括线性回归,逻辑回归,随机森林,支持向量机,决策树,朴素贝叶斯,神经网络。
无监督学习:目标或输出变量是未知的。这些算法通常对数据进行分析并生成数据簇。关联、聚类和维数约简算法属于这一类。K-means聚类、PCA(主成分分析)、Apriori算法等是非监督学习算法。
半监督学习:它是监督和非监督学习方法的结合。它使用已知数据来训练自己,然后标记未知数据。
强化学习:机器或代理被训练从"试错"过程中学习。机器从过去的决策经验中学习,并利用它的学习来预测未来决策的结果。强化学习算法的例子有Q-Learning, Temporal Difference等。
线性回归
线性回归是通过拟合数据点上的最佳直线来预测连续变量的结果。最佳拟合线定义了因变量和自变量之间的关系。该算法试图找到最适合预测目标变量值的直线。通过使数据点与回归线之间的差的平方和最小达到最佳拟合线。
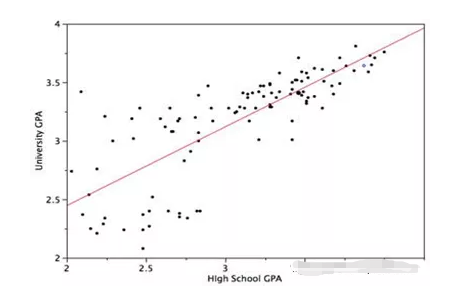
公式:Y = c + m₁X₁ + m₂X₂ + ….. +mₙXₙ
逻辑回归
逻辑回归是一种基于自变量估计分类变量结果的分类算法。它通过将数据拟合到logistic函数来预测某一事件发生的概率。通过最大化似然函数,对logistic函数中自变量的系数进行优化。优化决策边界,使成本函数最小。利用梯度下降法可以使代价函数最小化。
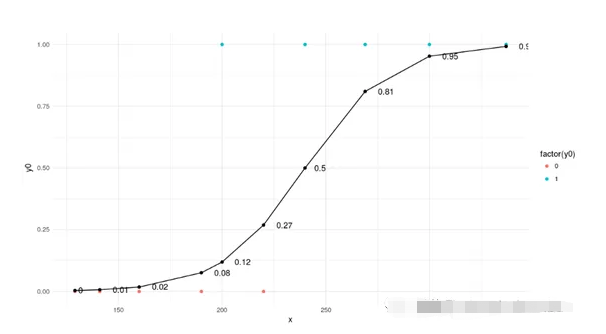
逻辑回归的s型曲线
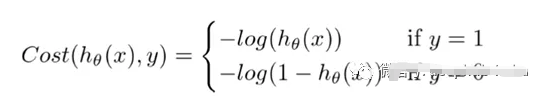
Logistic回归的代价函数
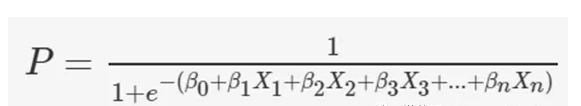
逻辑回归方程
朴素贝叶斯
朴素贝叶斯是一种基于贝叶斯定理的分类算法。该算法假设自变量之间不存在相关性。在一个类中出现的某个特性与在同一类中出现的另一个特性没有关系。我们针对类为所有预测器创建一个频率表(目标变量的不同值),并计算所有预测器的可能性。利用朴素贝叶斯方程,计算所有类别的后验概率。朴素贝叶斯分类器的结果将是所有类概率中概率最高的类。
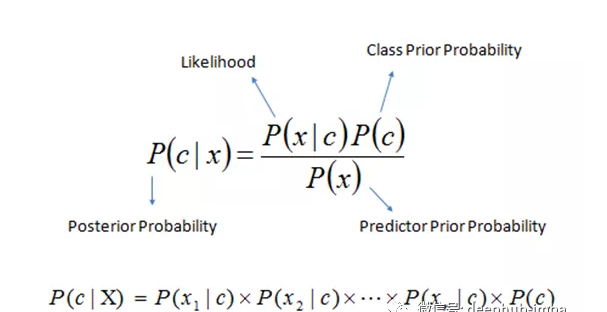
c→类,X→预测
决策树
决策树主要用于分类问题,但它们也可以用于回归。在该算法中,我们根据最有效地划分数据集的属性,将数据集划分为两个或多个同构集。选择将分割数据集的属性的方法之一是计算熵和信息增益。熵反映了变量中杂质的数量。信息增益是父节点的熵减去子节点的熵之和。选择提供最大信息增益的属性进行分割。我们也可以使用基尼指数作为杂质标准来分割数据集。为了防止过度分裂,我们优化了max_features、min_samples_split、max_depth等决策树的超参数。
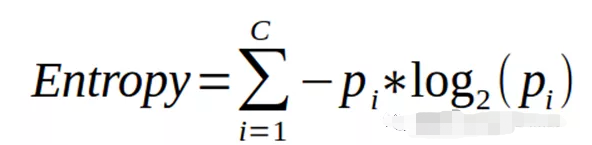
熵:c→类的数量
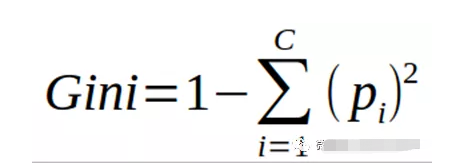
基尼指数
随机森林
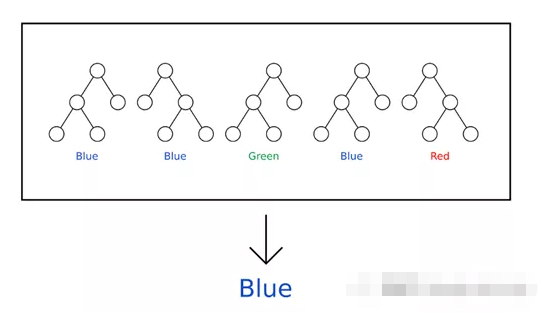
随机森林由多个决策树组成,决策树作为一个集合来运行。一个整体由一组用来预测结果的模型组成,而不是一个单独的模型。在随机森林中,每棵决策树预测一个类结果,投票最多的类结果成为随机森林的预测。为了做出准确的预测,决策树之间的相关性应该最小。有两种方法可以确保这一点,即使用Bagging和特性选择。Bagging是一种从数据集中选择随机观察样本的技术。特征选择允许决策树仅在特征的随机子集上建模。这就防止单个树使用相同的特性进行预测。
k -近邻
该算法也可用于回归和分类。该算法通过计算数据点与所有数据点的距离来找到k个数据点的最近邻。数据点被分配给k个邻居中点数最多的类(投票过程)。在回归的情况下,它计算k个最近邻居的平均值。不同的距离度量可以使用欧几里得距离,曼哈顿距离,闵可夫斯基距离等。为了消除平局的概率,k的值必须是一个奇数。由于每个数据点与其他数据点的距离都需要计算,因此该算法的计算开销较大。
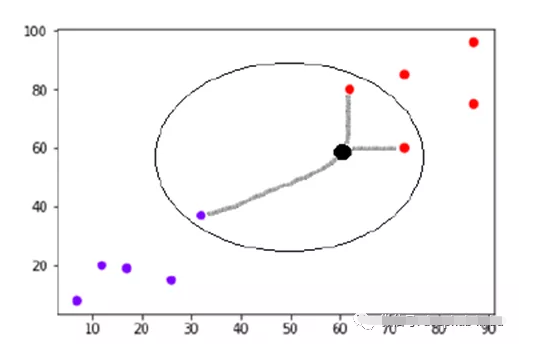
k - means
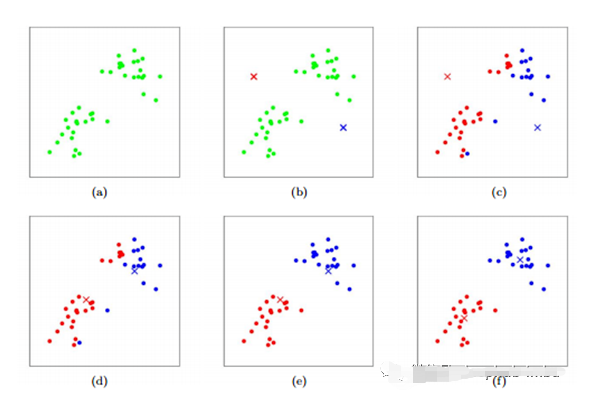
K-Means是一种无监督学习算法,用于形成数据簇。形成的集群应该使集群内的数据点尽可能相似,集群之间的差异尽可能明显。它随机选择K个位置,每个位置作为一个簇的质心。数据点被分配到最近的簇。在分配数据点之后,计算每个聚类的质心,再次将数据点分配到最近的聚类中。此过程将重复进行,直到在每次连续迭代中数据点保持在同一簇中,或簇的中心不改变为止。我们还可以指示算法在进行一定次数的迭代后停止计算。
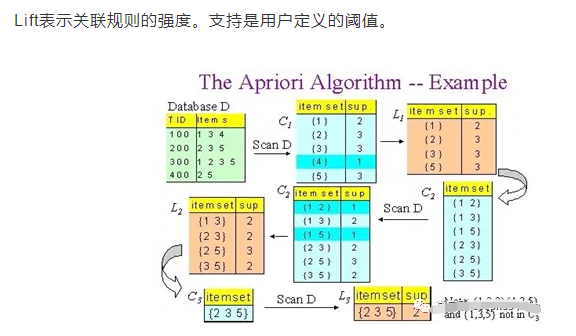
Apriori算法
Apriori算法是一种基于关联规则的数据库频繁项集识别算法。频繁项集是支持度大于阈值(支持度)的项集。关联规则可以被认为是一种IF-THEN关系。它通常用于市场篮子(market basket)分析中,发现不同商品之间的关联。支持、信心和提升是帮助确定关联的三个措施。

XGBoost
XGBoost是一种基于决策树的梯度增强算法(集成的另一种类型)。XGBoost涉及一组较弱的学习者,它们结合在一起可以做出值得注意的准确预测。Boosting是一个序列集成,每个模型都是在修正之前模型错误分类的基础上构建的。换句话说,它接收到前一个模型的错误,并试图通过学习这些错误来改进模型。

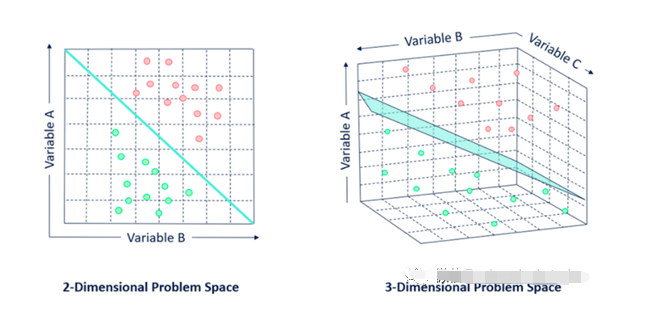
支持向量机(SVM)
SVM也是一种监督学习算法,可用于分类和回归问题。支持向量机试图在N维空间(N指特征的数量)中找到一个最优超平面来帮助分类不同的类。它利用Hinge损失函数,通过最大化类观测值之间的裕度距离来寻找最优超平面。超平面的维数取决于输入特征的数量。如果特征个数为N,则超平面的维数为N-1。
Hinge损失函数:t→目标变量,w→模型参数,x→输入变量
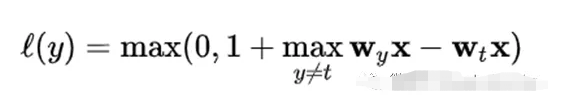
End.
文章来源于:DeepHub IMBA
本文为转载分享,如果涉及作品、版权和其他问题,请联系我们第一时间删除(微信号:lovedata0520)
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论