
有监督学习是利用训练数据集进行预测的机器学习任务。有监督学习可以分为分类和回归。回归用于预测"价格""温度"或"距离"等连续值,而分类用于预测"是"或"否"、"垃圾邮件"或"非垃圾邮件"、"恶性"或"良性"等类别。
分类包含三种类型的分类任务:二元分类、多类别分类和多标签分类。回归中包含线性回归和生存回归。

无监督学习是一种机器学习任务,它在不需要标记响应的情况下发现数据集中隐藏的模式和结构。当你只能访问输入数据,而训练数据不可用或难以获取时,无监督学习是理想的选择。常用的方法包括聚类、主题建模、异常检测、推荐和主成分分析。

在某些情况下,获取标记数据是昂贵且耗时的。在响应标记很少的情况下,半监督学习结合有监督和无监督学习技术进行预测。在半监督学习中,利用未标记数据对标记数据进行扩充以提高模型准确率。

强化学习试图通过不断从尝试的过程和错误的结果来进行学习,确定哪种行为能带来最大的回报。强化学习有三个组成部分:智能体(决策者或学习者)、环境(智能体与之交互的内容)和行为(智能体可以执行的内容)。这类学习通常用于游戏、导航和机器人技术。

深度学习是机器学习和人工智能的一个分支,它使用深度的、多层的人工神经网络。最近人工智能领域的许多突破都归功于深度学习。

神经网络是一类类似于人脑中相互连接的神经元的算法。一个神经网络包含多层结构,每一层由相互连接的节点组成。通常有一个输入层、一个或多个隐藏层和一个输出层。

卷积神经网络(convnet或CNN)是一种特别擅长分析图的神经网络(尽管它们也可以应用于音频和文本数据)。卷积神经网络各层中的神经元按高度、宽度和深度三个维度排列。我将在第7章更详细地介绍深度学习和深度卷积神经网络。

在分类中,每个数据点都有一个已知的标签和一个模型生成的预测类别。通过比较已知的标签和预测类别为每个数据点进行划分,结果可以分为四个类别:
这四个值构成了大多数分类任务评估指标的基础。它们通常在一个叫作混淆矩阵的表格中呈现(如表1-1)。

准确率是分类模型的一个评估指标。它定义为正确预测数除以预测总数。
在数据集不平衡的情况下,准确率不是理想的指标。举例说明,假设一个分类任务有90个阴性和10个阳性样本;将所有样本分类为阴性会得到0.90的准确率分数。精度和召回率是评估用例不平衡数据的训练模型的较好指标。

精度定义为真阳性数除以真阳性数加上假阳性数的和。精度表明当模型的预测为阳性时,模型正确的概率。例如,如果你的模型预测了100个癌症的发生,但是其中10个是错误的预测,那么你的模型的精度是90%。在假阳性较高的情况下,精度是一个很好的指标。

召回率是一个很好的指标,可用于假阴性较高的情况。召回率的定义是真阳性数除以真阳性数加上假阴性数的和。

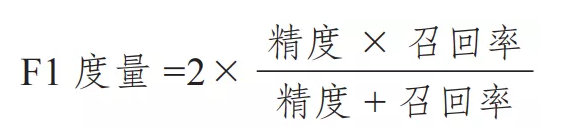
F1度量或F1分数是精度和召回率的调和平均值或加权平均值。它是评估多类别分类器的常用性能指标。在类别分布不均的情况下,这也是一个很好的度量。最好的F1分数是1,而最差的分数是0。一个好的F1度量意味着你有较低的假阴性和较低的假阳性。F1度量定义如下:

接收者操作特征曲线下面积(AUROC)是评估二元分类器性能的常用指标。接收者操作特征曲线(ROC)是依据真阳性率与假阳性率绘制的图。曲线下面积(AUC)是ROC曲线下的面积。
在对随机阳性样本和随机阴性样本进行预测时,将阳性样本预测为阳性的概率假设为P0,将阴性样本预测为阳性的概率假设为P1,AUC就是P0大于P1的概率。曲线下的面积越大(AUROC越接近1.0),模型的性能越好。AUROC为0.5的模型是无用的,因为它的预测准确率和随机猜测的准确率一样。

过拟合是指一个模型太适合训练数据。过拟合的模型在训练数据上表现良好,但在新的、看不见的数据上表现较差。
过拟合的反面是欠拟合。由于拟合不足,模型过于简单,没有学习训练数据集中的相关模式,这可能是因为模型被过度规范化或需要更长时间的训练。
模型能够很好地适应新的、看不见的数据,这种能力被称为泛化。这是每个模型优化练习的目标。
防止过拟合的几种方法包括使用更多的数据或特征子集、交叉验证、删除、修剪、提前停止和正则化。对于深度学习,数据增强是一种常见的正则化形式。
为了减少欠拟合,建议选择添加更多相关的特征。对于深度学习,考虑在一个层中添加更多的节点或在神经网络中添加更多的层,以增加模型的容量。

模型选择包括评估拟合的机器学习模型,并尝试用用户指定的超参数组合来拟合底层估计器,再输出最佳模型。通过使用Spark MLlib,模型选择由CrossValidator和TrainValidationSplit估计器执行。
CrossValidator对超参数调整和模型选择执行k-fold交叉验证和网格搜索。它将数据集分割成一组随机的、不重叠的分区,作为训练和测试数据集。例如,如果k=3,k-fold交叉验证将生成3对训练和测试数据集(每一对仅用作一次测试数据集),其中每一对使用2/3作为训练数据,1/3用于测试。
TrainValidationSplit是用于超参数组合的另一种估计器。与k-fold交叉验证(这是一个昂贵的操作)相反,TrainValidationSplit只对每个参数组合求值一次,而不是k次。
关于作者:布奇·昆托(Butch Quinto),在银行与金融、电信、政府部门、公共事业、交通运输、电子商务、零售业、制造业和生物信息学等多个行业拥有20多年的技术和领导经验。他是Next-Generation Big Data(Apress,2018)的作者,也是人工智能促进协会(AAAI)和美国科学促进会(AAAS)的成员。










评论