

" 说好的带你们手撕代码。 阅读本文预计需要…我哪知道要多久,反正有点长,看你的理解能力了。"
接上一篇《数据与广告系列十:开启机器学习之路》,我们打开数据与广告系列的机器学习相关的篇章,我们了解到了在整个广告的系统流程里,几乎每个环节,如果你愿意,都可以完美的嵌入机器学习的东西。
然而在上一篇,我们并未触及到任何关于算法实践,代码落地的东西,始终停留在场景和少量理论的维度上,甚至可以说任何非技术人员都可以理解。
我的微信签名是"Talk is cheap,show me the data",标准翻译是"别扯这么多蛋,以数据说话"。今天我们不show data,我们来手撕代码,说不定撕着撕着,那些看似比较难的东西我们就懂了。
01、广告定向中的性别标签
在上篇文章中,我们曾经提到过一个机器学习的应用场景,那就是定向标签的挖掘,而性别标签则又是所有广告平台中最基础也是最常用的一个定向标签。
如下图,这是腾讯广点通平台上创建广告的时候,做定向条件设置的时候,可以看到的界面。
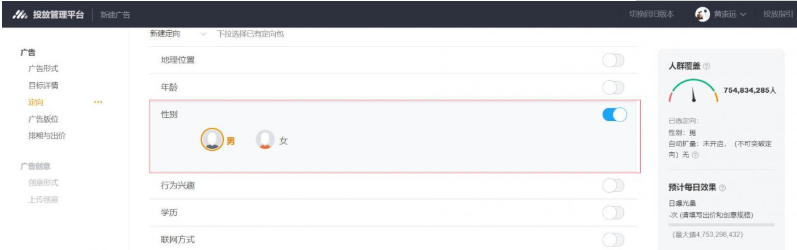
针对于性别标签,这是一个所有广告平台的标配,既然是标配,那意味着是一个常用的能力,那么就要保证覆盖要全,标签要准。
但是,并不是所有平台都拥有准确性别原始数据的,唯一当前我能想到的平台就是银行体系了,毕竟没有身份证你啥也办不了,既然有了身份证,那么就有了性别标签。
诚如腾讯如此大的体量,但并不是所有业务场景都需要用户授权身份证号的,毕竟是一个非常隐私的信息,非常规场景不能用也。所以,同样也面临着如何将性别标签覆盖全体用户的问题,其他平台就更不用说了。
对于所有广告平台来说,显性的增加可靠性别覆盖的方式,一方面是尽量的创建一些合理的业务场景来确保拿到最准确的身份证信息,比如防个沉迷啊,你总的证明你自己成年了,要做个信用评估啊,总的有官方认可的真实身份吧,等等之类。
除此之外,合法的第三方数据来源,这个就不深入展开说了。但不管怎么样,还是那句话,除了银行,都得解决这个问题。那么,就必然会面临如何预测未知性别的问题。
每个平台体系内,总是能通过上面几种方式拿到部分或者很大一部分明确性别的数据,那个就是已知标注的样本。通过已知预测未知,非常之标准的监督学习的问题,或者说典型的归属到分类模型的机器学习问题。
02、手撕数据来源
我们第一个场景就是来做性别的预测,拿到标注好的性别数据,然后再拿到用户对应的各种维度的数据,作为特征,最终预测出靠谱的结果。
对于各大平台来说,体量够大的话,方式对的话,总是能找到很多性别差异显著(差异区分度大,加大预测的可行性)的行为特征。对于我们来说,我们需要找到尽可能的合理以及看似真实的数据,才能更好的手撕代码。
我从kaggle上找到两份跟性别预测相关,且关注人数达数百以上的脱敏数据,一份是之前talkingdata提供的数据,包含用户性别标志,以及各种用户起卸停APP的行为数据,还有关联的APP类别数据等,如果你要去搜索,直接搜索"TalkingData Mobile User Demographics"即可。
但我没用这份数据,虽然下意识的认为这份数据会很靠谱,but,大达5GB,我的那个小小阿里云机,绝壁是跑不动的,加上还有跑模型训练。
所以选择了另一份数据,kaggle搜索"twitter-user-gender-classification",由参赛方提供的脱敏twitter性别分类数据,看名字就很靠谱。但实际用了下,以及看了下评论,貌似真的不算靠谱,质量稍稍有点堪忧,总共2万多条数据,26个维度特征(绝大部分不可用)。
机器资源有限,精力有限,重点是了解这么一个机器学习的场景,以及实际的机器学习过程,大家不要在意这些细节啦。
03、提前的准备
在写代码之前,希望大家对于python有基础的认知,因为全程将由python完成,所以请自行学习python基础,请自行安装好anaconda3集成环境,请提前稍微熟悉一下python的编译集成环境jupyter notebook,以上,不懂得请goggle之,教程简直一大把。
所有数据预处理,清洗,都将使用numpy,pandas,绘制一些图可能会用到matplotlib等python工具库,虽然我们在文章的过程中可能会稍等学习,但是毕竟有限,请提前学习之。
大部分机器学习实践,都将使用sklearn2.X进行,文章涉及的部分会进行讲解,但毕竟时间有限,请先行了解。
为什么用sklearn?
因为python整套流程支持很足啊,数据的读入,清洗,观测,各种数学库,简直不要太方便,更何况,你觉得一个月几百块的阿里云机能跑的动深度学习的东西吗?连用个数据集,我都得掂量着用。
04、数据初探
任何机器学习的开头,都躲不开对于所持有数据的观测,连数据都不知道长啥样,你玩个锤子算法。

jupyter notebook的环境大概长这个样子,可以随意的创建文件夹,或者创建python文件,下面那个ipynb后缀的就是编译执行文件,不深入,请自行谷歌。
引入几个必然要用的包:
import pandas as pd #python知名数据处理包import numpy as np #跟上面一样知名,还更古老import matplotlib.pyplot as plt #同上知名,用于绘图,便于观测
读入数据:
data = pd.read_csv("./data/gender-classifier-DFE-791531.csv",header = 0,error_bad_lines=False,encoding="latin1",skip_blank_lines=True)#header=0,不需要自己指定表头,自带#error_bad_lines=False,错误行自动删除多余,就喜欢pd的各种聪明骚操作#encoding,编码,不多说#skip_blank_lines,空行跳过
看一下具体数据的样子:
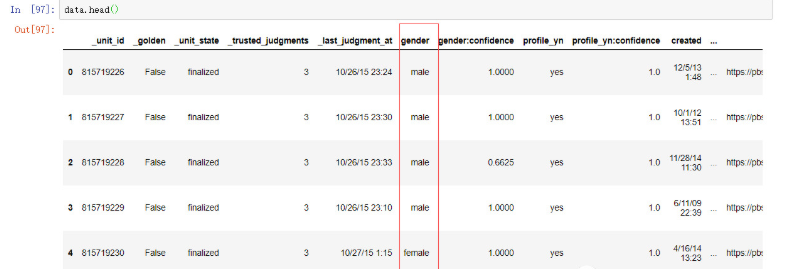
实在有点多,显示不全,26个维度,圈起来的就是gender标注列,就是我们一般预测模型里的Y值。
整体的特征维度如下(中文是我自己瞎琢磨翻译的,凑合着看,应该能看懂,不懂自行翻译工具翻译):
# _unit_id(唯一ID): a unique id for user# _golden(黄金标准,2值): whether the user was included in the gold standard for the model; TRUE or FALSE# _unit_state(检测状态,2值): state of the observation; one of finalized (for contributor-judged) or golden (for gold standard observations)# _trusted_judgments(可信的评论数量,连续值): number of trusted judgments (int); always 3 for non-golden, and what may be a unique id for gold standard observations# _last_judgment_at(最后评论时间): date and time of last contributor judgment; blank for gold standard observations# gender(性别): one of male, female, or brand (for non-human profiles)# gender:confidence(性别的可信度,置信区间): a float representing confidence in the provided gender# profile_yn(no代表是资料收集,非预测): "no" here seems to mean that the profile was meant to be part of the dataset but was not available when contributors went to judge it# profile_yn:confidence(profile_yn置信取间): confidence in the existence/non-existence of the profile# created(用户创建时间): date and time when the profile was created# description(用户描述): the user"s profile description# fav_number(关注人数): number of tweets the user has favorited# gender_gold(性别 黄金?): if the profile is golden, what is the gender?# link_color(十六进制,link颜色): the link color on the profile, as a hex value# name(名称): the user"s name# profile_yn_gold(二值): whether the profile y/n value is golden# profileimage(头像): a link to the profile image# retweet_count(被关注次数): number of times the user has retweeted (or possibly, been retweeted)# sidebar_color(边框颜色): color of the profile sidebar, as a hex value# text(随机抽取的tweets文本): text of a random one of the user"s tweets# tweet_coord(如果用户开启了定位,则显示经纬度): if the user has location turned on, the coordinates as a string with the format "[latitude, longitude]"# tweet_count(发布的tweet数): number of tweets that the user has posted# tweet_created(随机抽取的tweet创建时间): when the random tweet (in the text column) was created# tweet_id(随机抽取的tweet的id): the tweet id of the random tweet# tweet_location(tweet的定位,没有做规范化处理): location of the tweet; seems to not be particularly normalized# user_timezone(用户的时区): the timezone of the user
是不是看着不错?再来看一个数据:
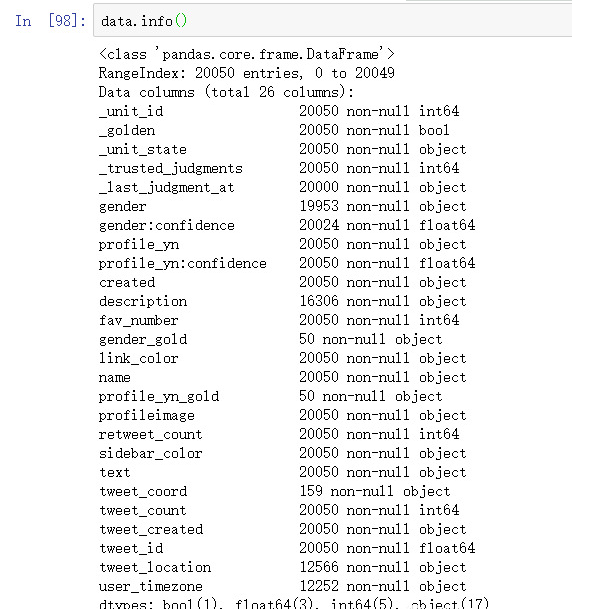
dataframe.info()函数,可以看到数据集的整体情况,是不是发现各种空值,数量凑不够20050的,凑够了20050的能不能用还两说。
05、特征选择
从基本的数据初探中,我们大概知道了数据的范围,但是能不能用,我们需要有个先行的判断,不能什么数据都丢到模型中去。
我们的目标是预测gender,性别分为了三类,而非常规的两类男女,这个大家应该要有点业务思维,推特上很多机构类型的账号是不难理解的,就跟微博上有很多机构账户是一个理儿。
从直观的角度,我们筛选出可能跟性别有关系的一些特征,加上了我自己基于性别预测的一些可能猜测,这是入选依据:
#寻找x的特征,性别判别,先直观圈选# + (_golden) golden标准,二值,估计是一种荣耀徽章之类的?# + (_trusted_judgments) 可信的评论数量,男女品牌 评论数理论上应该不同吧。# + (description) 个人简介,太有用了,但是是text文本,需要加大处理力度了。# + (fav_number) 关注人数,男女品牌关注行为可能不同。# + (gender_gold) 性别 黄金?什么鬼# + (link_color) link颜色,颜色一向跟性别强相关,拿下先。# + (name) 名称,理论上是有差别的。# + (retweet_count) 被关注数?女性 跟品牌 容易被关注?# + (sidebar_color) 头像边框颜色,理论上还是有特征差异的。# + (text) 随机抽取的一条推文,推文理论上能一定程度反应,但量应该多点。# + (tweet_coord) 开启定位,如果开启则显示经纬度,可以考虑做成二值特征。# + (tweet_count) 推文数量,不同性别这个指标活跃度不同?
我们先对性别做一个处理,几乎所有的模型,都只接受int float或者bool三种类型的原始数据,而我们的性别数据是female,male,以及brand。所以适当的转换一下:
##拿到y值series_female = data["gender"] == "female"series_male = data["gender"] == "male"series_brand = data["gender"] == "brand"df_female = data[series_female]df_male = data[series_male]df_brand = data[series_brand]#三种性别的个数print(f"Gender - female: {df_female["gender"].count()}")print(f"Gender - male: {df_male["gender"].count()}")print(f"Gender - brand: {df_brand["gender"].count()}")#将性别进行人工编码,female=0,male=1, brand=2df_female.gender = 0df_male.gender = 1df_brand.gender = 2#合并y值结果数据,行合并,ignore_index=True,默认columns相同,index纵向相加,若列合并,axis=1,但列数量必须相同df = pd.concat([df_female, df_male, df_brand], ignore_index=True)
输出如下:
Gender - female: 6700Gender - male: 6194Gender - brand: 5942
基本均匀分布,从这个维度来说,非常省心。还记得上个文章,我们提到过的异常情况检测吗,就是典型的样本不均衡的场景,会搞死人的。当前这种样本均衡的分类场景已经算是非常之仁慈了。
我们先定义一个观测特征与Y值分布的函数,用来观测所有待参考特征与Y之间的分布关系:
#特征与y的分布,构建一个散点分布函数def drawScatter(x, y, xLabel):plt.figure(figsize=(10,5))plt.scatter(x, y)plt.title("%s VS Gender" %xLabel)plt.xlabel(xLabel)plt.ylabel("Gender")plt.yticks(range(0, 2, 1)) # 纵轴起点,最大值,间隔, 对应的就是genderplt.grid()plt.show()
先拿tweet_count开刀,发推次数,说不定男生喜欢发,女生只喜欢看呢,是吧,万一品牌账号天天刷屏呢?
#tweet_count发布tweet数量drawScatter(df["tweet_count"],y,"tweet_count")
数值型特征,有了上面def的函数,就是这么简单:
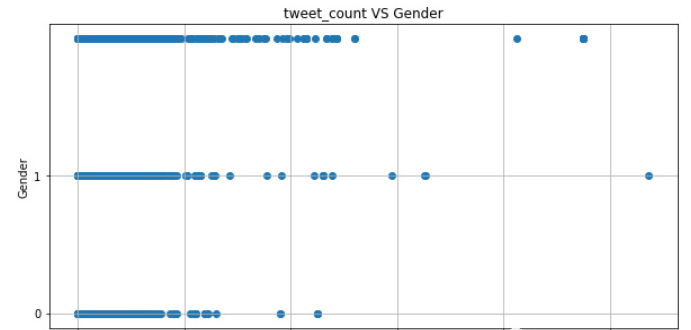
可以看到,实际上还是有些区分度的,整体来看,横坐标靠近0的地方差异不大,但是越往后面走,差异性就出来了。
果然,0=female比较喜欢"只看不发",1=male比女生更骚包一些,2=brand果然天天刷屏。还是有些差异性的。
再来看一个例子,sidebar_color_id边框颜色,颜色这东西,说不定很有性别差异度,男生总不能搞个大红大紫的是吧。但是由于颜色特征都是记录的颜色编码,诸如类似这种"C0DEED"的,不是搞艺术的不懂。
我们还是把他转换成数字吧,这里就要用到了特征label编码,说白了就是将类型转换为数字编码,非常非常见的一种将str类型转换为int编码类的方式:
#sidebar_color特征from sklearn.feature_selection import LabelEncoder #引入特征筛选的包#构建link_color字典dic_sidebar_colordic_sidebar_color = []df_sidebar_color = df["sidebar_color"]list_sidebar_color = df_sidebar_color.tolist()for i in list_sidebar_color:if i not in dic_sidebar_color:dic_sidebar_color.append(i)#通过字典进行label编码label_sidebar_color = preprocessing.LabelEncoder()label_sidebar_color.fit(dic_sidebar_color)df_sidebar_color_id_tmp = label_sidebar_color.transform(df_sidebar_color)df_sidebar_color_id = pd.DataFrame(df_sidebar_color_id_tmp, index=df.index, columns=["sidebar_color_id"])#调用分布绘制函数drawScatter(df_sidebar_color_id,y,"sidebar_color_id")
分布结果如下,从颜色的分布来看还是有差异的。

除了文本特征text,name,description,其他的特征要么是数值型,要么是label型,按如上两种方式处理即可。文本涉及到自然语言处理,初探部分我们先暂缓。
有些特征差异性大点,有些几乎没有差异:
然后我们把认为可能影响到Y分类的特征做成X吧,即特征的输入。
#拿到x特征集合from sklearn.model_selection import train_test_splitdf_x = pd.concat([df[["_trusted_judgments","fav_number","retweet_count","tweet_count"]],df_golden,df_link_color_id,df_sidebar_color_id],axis=1)#数据切割x_train, x_test, y_train, y_test = train_test_split(df_x, y, test_size = 0.25)print(f"Train : Text =>{y_train.count()} : {y_test.count()}")df_x.describe().T
是的,反正是练习嘛,我就认为所有特征都可能影响预测结果咯(实际上,后面我做了显著特征选择,结果还真下降了),顺带还使用train_test_split将X数据完美的切分为了训练数据集和测试数据集,切分比例为3:1。
df.describe()可以看到数值型特征的各种统计指标,T就是把行转列,方便观测,如下:
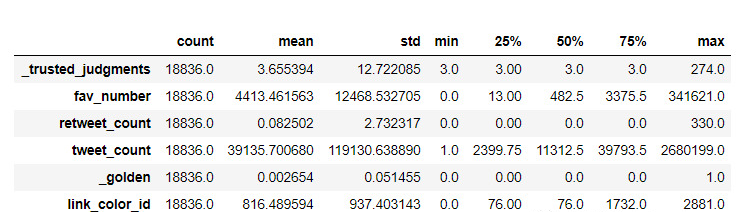
可以看到各种数量,mean均值,std标准差,min最小值,25%分位值,50%,75%分位值,max值等。
反正也看不出啥来,直接上预测代码吧,先写个评估的统一方法吧,不然每个模型都要写一遍多累(代码一会儿解释):
def print_score(y_t, y_p, confusion):text_accuracy = accuracy_score(y_t, y_p)text_0_recall = confusion[0,0]/(confusion[0,0]+confusion[0,1]+confusion[0,2])text_0_precision = confusion[0,0]/(confusion[0,0]+confusion[1,0]+confusion[2,0])text_1_recall = confusion[1,1]/(confusion[1,0]+confusion[1,1]+confusion[1,2])text_1_precision = confusion[1,1]/(confusion[0,1]+confusion[1,1]+confusion[2,1])text_2_recall = confusion[2,2]/(confusion[2,0]+confusion[2,1]+confusion[2,2])text_2_precision = confusion[2,2]/(confusion[0,2]+confusion[1,2]+confusion[2,2])text_avg_precision = (text_0_precision+text_1_precision+text_2_precision)/3text_avg_recall = (text_0_recall+text_1_recall+text_2_recall)/3print(f"0-precision: {text_0_precision}")print(f"0-recall: {text_0_recall}")print(f"1-precision: {text_1_precision}")print(f"1-recall: {text_1_recall}")print(f"2-precision: {text_2_precision}")print(f"2-recall: {text_2_recall}")print(f"avg-precison: {text_avg_precision}")print(f"avg-recall: {text_avg_recall}")print(f"accuracy: {text_accuracy}")
开始罗列各种模型了,请叫我模型工程师,准备好姿势:
#使用万能的xgboost算法,conda安装xgboost:conda install -c anaconda py-xgboostfrom xgboost import XGBClassifierxgb = XGBClassifier()xgb.fit(x_train,y_train)y_predict = xgb.predict(x_test)other_confusion = confusion_matrix(y_test, y_predict,labels=[0,1,2])print(f"confusion_matrix: {other_confusion}")#打印各个类别的precision和recallprint_score(y_test, y_predict, other_confusion)
xgboost号称kaggle竞赛中使用次数最多的模型,第一个就上他,号称万金油模型,也是最容易调优的模型。
完了?神秘的机器学习代码就完了呀?!完了呀。就这几行,你还想要几行,引入包,fit训练数据,然后predict测试数据,评估结果,标准流程,童叟无欺。
是的,没毛病,咱这篇文章就是要简单,这就是最简单的train+test流程。别纠结了,看结果:
confusion_matrix:[[956 547 199][494 804 223][252 386 848]]0-precision: 0.56169212690951820-recall: 0.56169212690951821-precision: 0.462867012089811-recall: 0.52859960552268252-precision: 0.66771653543307092-recall: 0.5706594885598923avg-precison: 0.5640918914774664avg-recall: 0.5536504069973643accuracy: 0.5538330855808027
confusion_matrix学名混淆矩阵,你可以看到每个类别分对分错的情况,每一行代表一类,分别是0 1 2, 每个纵列也是0 1 2。所以,针对于0类,00元素就是对的,针对1类,11元素就是对的,针对2类,22就是对的(可以看下上面的评估def,更容易理解),剩下的都是错分。
然后有了混淆矩阵,整体每一类的Precision(精准率?准确率?反正没人能说清),Recall召回率都一清二楚了。
而我们整体上会观测整体的accuracy,精确率,使用全局对的除于全局样本数,从整体的角度来衡量分类的精确情况。辅助于观测avg-P,avg-R。
从结果的角度看,很一般,0 2类表现稍好点,1类简直惨不忍睹,比瞎猜好点(猜是1/3概率嘛,这里好歹有接近50%)。至此,虽然结果貌似惨不忍睹,但是已经体现机器学习的作用了,毕竟乱猜只有1/3概率,这里硬生生拔高了相对于60%的准确度。
其实结果真的算好的了,其他几个模型,简直不能直视。
我们常挂在嘴边的LR:
from sklearn.linear_model import LogisticRegressionCVother_lr = LogisticRegressionCV()other_lr.fit(x_train, y_train)y_predict = other_lr.predict(x_test)other_confusion = confusion_matrix(y_test, y_predict,labels=[0,1,2])print(f"confusion_matrix: {other_confusion}")print_score(y_test,y_predict, other_confusion)confusion_matrix:[[987 358 357][666 368 487][506 111 869]]0-precision: 0.45715609078276980-recall: 0.57990599294947121-precision: 0.439665471923536441-recall: 0.241946088099934262-precision: 0.50729713952130762-recall: 0.5847913862718708avg-precison: 0.4680395674092046avg-recall: 0.4688811557737587accuracy: 0.4722871097897643
传统分类模型的中坚,SVM:
#使用SVMfrom sklearn.svm import SVCother_svc = SVC()other_svc.fit(x_train, y_train)y_predict = other_svc.predict(x_test)other_confusion = confusion_matrix(y_test, y_predict,labels=[0,1,2])print(f"confusion_matrix: {other_confusion}")print_score(y_test,y_predict, other_confusion)confusion_matrix:[[1653 26 23][1415 82 24][1121 45 320]]0-precision: 0.39460491764144190-recall: 0.97121034077555811-precision: 0.53594771241830061-recall: 0.053911900065746222-precision: 0.87193460490463212-recall: 0.21534320323014805avg-precison: 0.6008290783214583avg-recall: 0.4134884813571508accuracy: 0.43639838606922915
还有朴素贝叶斯,随机森林什么的,我就不一一贴了,虽然不至于一个比一个差,但是accuracy上0.5都难,这让我很为难。
从"广义理论"上说,既然model都有了,而且一下还好几个,你就可以拿新的数据,比如其他tweet的行为数据,处理成X的样子,丢进去,然后就可以拿到不那么靠谱的预测结果了。
本来,应该打完收工了?但是,如果把这个结果拿出去实际生产,你会被打死的。
06、这还没有完,我们应该走的更远
上面的结果不但是你们不可接受的,我也不可接受的。话说,如果业界算法工程师都是以上面的知识程度去拿年薪百万,哪个公司都是要破产的。
如上,我们确实基本上把机器学习到业务场景的流程都走了一遍,理解业务场景,拿到数据,观测数据,选择特征,选择模型,模型评估,最多再加个实际预测,都走了一边。
但是,还有很多待解决的问题,比如既然数值型,类别型的特征效果如此之差,text文本理论上包含更多的性别信息,男生总不能总发一些很娘炮的状态吧,品牌说不定天天发他的品牌宣传等。但是,文本的处理以及模型使用跟常规的是一致的吗?显然不是的,鬼知道他/她发了什么文本内容。
特征的选择以及观测有没有更加合理的方式,这种看分布图,肉眼可见实在是太原生态了,以及特征是否要进一步处理,比如连续型的特征是否要做分段处理。特征的选择,是否选择合理的会更加准确,多余的无效特征反而会降低效果?
模型训练预测过程真的这么简单吗?真的没有这么简单,算法工程师又有个别称"调参工程师",参数呢?很多情况下,参数对于结果的影响是巨大的,特别是有些算法,简直是参数杀手,典型如深度学习的一些模型。戏说,结果好坏全靠命,调好调坏全靠早晚一炷香。当然,这是开玩笑,调参也是有方法的,高效的方式能让你快速找到局部最优的参数(我不敢说全局最优,谁也不敢说)。
最终结果的评估,以及实际应用,有没有更合理的方式等等。
所以,残酷的现实就是,就算这篇懂了,你也连个入门都不算,最多算是门外一窥。在下个章节里,我们将沿着这个CASE,深化下去,解决如上问题,带你入门带你飞。
End.
作者:黄崇远
本文为转载分享,如果涉及作品、版权和其他问题,请联系我们第一时间删除(微信号:lovedata0520)
更多文章前往首页浏览http://www.itongji.cn/
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论