

文末附赠统计学最全干货导图~
 其他
其他
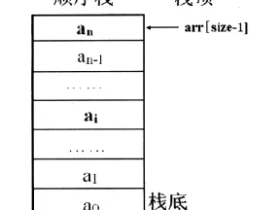
数据结构-栈和队列
前言本章节开始数据结构第二篇,栈和队列——栈:栈的存储结构、栈的基本操作队列:队列的存储结构、队列的基本操作
 数据分析
数据分析
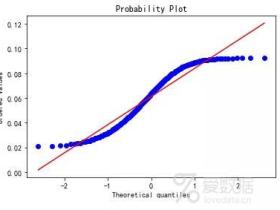
统计学干货 I 正态性检验
很多模型的假设条件都是数据是服从正态分布的。这篇文章主要讲讲如何判断数据是否符合正态分布。主要分为两种方法:描述统计方法和统计检验方法。描述统计就是用描述的数字或图表来判断数据是否...
 数据分析
数据分析
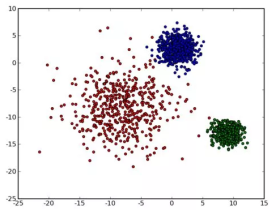
Sklearn参数详解—聚类算法
聚类是一种非监督学习,是将一份给定数据集划分成k类,这一份数据集可能是某公司的一批用户,也可能是某媒体网站的一系列文章,如果是某公司的一批用户,那么k-means做的就是根据用户的...
 数据分析
数据分析
为jupyter_notebook增加目录
jupyter_notebook是数据相关岗位从业者的一个不错的选择,很清晰、很方便,可以将分析过程和分析结果同步显示在一起。
 数据分析
数据分析
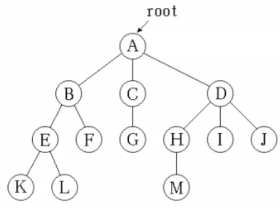
数据结构—树与二叉树
之前谈到的线性表、栈和队列都是一对一的数据结构,但是现实中也存在很多一对多的数据结构,这篇要写的就是一种一对多的数据结构———树。
 其他
其他
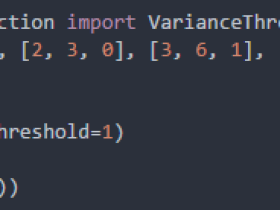
机器学习中的特征选择
本篇讲解一些特征工程部分的特征选择(feature_selection),主要包括以下几方面:特征选择是什么为什么要做特征选择特征选择的基本原则特征选择的方法及实现
 数据分析
数据分析
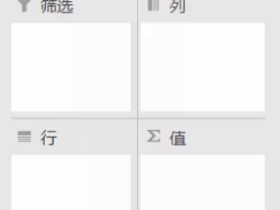
SQL 实现数据透视表功能
数据分组和数据透视表很像,Sql 中的数据分组大家应该都很熟悉了,用的就是 group by。数据透视表是作为一个数据分析师最基本,也是使用频率最高的一个功能。
数据分析
SKlearn参数详解—随机森林
随机森林(RandomForest,简称RF)是集成学习bagging的一种代表模型,随机森林模型正如他表面意思,是由若干颗树随机组成一片森林,这里的树就是决策树。
 数据分析
数据分析
如何轻松学习Python数据分析?
今天这篇文章来聊聊如何轻松学习『Python数据分析』,我会以一个数据分析师的角度去聊聊做数据分析到底有没有必要学习编程、学习Python,如果有必要,又该如何学习才能做到毫不费力...
评论