
六.模型分析
证据权重(Weight of Evidence,WOE)转换可以将Logistic回归模型转变为标准评分卡格式。
引入WOE转换的目的并不是为了提高模型质量,只是一些变量不应该被纳入模型,这或者是因为它们不能增加模型值,或者是因为与其模型相关系数有关的误差较大,其实建立标准信用评分卡也可以不采用WOE转换。
这种情况下,Logistic回归模型需要处理更大数量的自变量。尽管这样会增加建模程序的复杂性,但最终得到的评分卡都是一样的。
在建立模型之前,我们需要将筛选后的变量转换为WoE值,便于信用评分。
1.WOE转换
我们已经能获取了每个变量的分箱数据和woe数据,只需要根据各变量数据进行替换,实现代码如下:
#替换成woe函数def replace_woe(series, cut, woe): list = [] I = 0 while i<len(series): value=series[i] j=len(cut) - 2 m=len(cut) - 2 while j >= 0: if value>=cut[j]: j = -1 else: j -= 1 m -= 1 list.append(woe[m]) i += 1 return list
我们将每个变量都进行替换,并将其保存到WoeData.csv文件中:
# 替换成woedata["RevolvingUtilizationOfUnsecuredLines"] = Series(replace_woe(data["RevolvingUtilizationOfUnsecuredLines"], cutx1, woex1))data["age"] = Series(replace_woe(data["age"], cutx2, woex2))data["NumberOfTime30-59DaysPastDueNotWorse"] = Series(replace_woe(data["NumberOfTime30-59DaysPastDueNotWorse"], cutx3, woex3))data["DebtRatio"] = Series(replace_woe(data["DebtRatio"], cutx4, woex4))data["MonthlyIncome"] = Series(replace_woe(data["MonthlyIncome"], cutx5, woex5))data["NumberOfOpenCreditLinesAndLoans"] = Series(replace_woe(data["NumberOfOpenCreditLinesAndLoans"], cutx6, woex6))data["NumberOfTimes90DaysLate"] = Series(replace_woe(data["NumberOfTimes90DaysLate"], cutx7, woex7))data["NumberRealEstateLoansOrLines"] = Series(replace_woe(data["NumberRealEstateLoansOrLines"], cutx8, woex8))data["NumberOfTime60-89DaysPastDueNotWorse"] = Series(replace_woe(data["NumberOfTime60-89DaysPastDueNotWorse"], cutx9, woex9))data["NumberOfDependents"] = Series(replace_woe(data["NumberOfDependents"], cutx10, woex10))data.to_csv("WoeData.csv", index=False)
2.Logisic模型建立
我们直接调用statsmodels包来实现逻辑回归:
导入数据data = pd.read_csv("WoeData.csv")#应变量Y=data["SeriousDlqin2yrs"]#自变量,剔除对因变量影响不明显的变量X=data.drop(["SeriousDlqin2yrs","DebtRatio","MonthlyIncome", "NumberOfOpenCreditLinesAndLoans","NumberRealEstateLoansOrLines","NumberOfDependents"],axis=1)X1=sm.add_constant(X)logit=sm.Logit(Y,X1)result=logit.fit()print(result.summary())
输出结果:
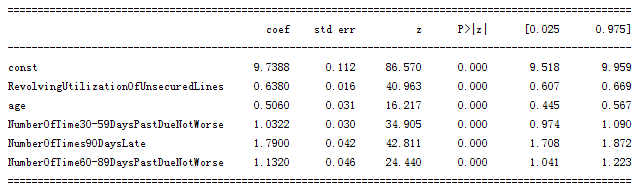
逻辑回归模型结果
逻辑回归各变量都已通过显著性检验,满足要求。
3.模型检验
到这里,我们的建模部分基本结束了。我们需要验证一下模型的预测能力如何。我们使用在建模开始阶段预留的test数据进行检验。通过ROC曲线和AUC来评估模型的拟合能力。
在Python中,可以利用sklearn.metrics,它能方便比较两个分类器,自动计算ROC和AUC。
实现代码:
#应变量Y_test = test["SeriousDlqin2yrs"]#自变量,剔除对因变量影响不明显的变量,与模型变量对应X_test = test.drop(["SeriousDlqin2yrs", "DebtRatio", "MonthlyIncome", "NumberOfOpenCreditLinesAndLoans","NumberRealEstateLoansOrLines", "NumberOfDependents"], axis=1)X3 = sm.add_constant(X_test)resu = result.predict(X3)#进行预测fpr, tpr, threshold = roc_curve(Y_test, resu)rocauc = auc(fpr, tpr)#计算AUCplt.plot(fpr, tpr, "b", label="AUC = %0.2f" % rocauc)#生成ROC曲线plt.legend(loc="lower right")plt.plot([0, 1], [0, 1], "r--")plt.xlim([0, 1])plt.ylim([0, 1])plt.ylabel("真正率")plt.xlabel("假正率")plt.show()
输出结果:
ROC曲线
从上图可知,AUC值为0.85,说明该模型的预测效果还是不错的,正确率较高。
七.信用评分
我们已经基本完成了建模相关的工作,并用ROC曲线验证了模型的预测能力。接下来的步骤,就是将Logistic模型转换为标准评分卡的形式。
1.评分标准

依据以上论文资料得到:
- a=log(p_good/P_bad)
- Score = offset + factor * log(odds)
在建立标准评分卡之前,我们需要选取几个评分卡参数:
- 基础分值
- PDO(比率翻倍的分值)
- 好坏比
这里, 我们取600分为基础分值,PDO为20 (每高20分好坏比翻一倍),好坏比取20。
# 我们取600分为基础分值,PDO为20(每高20分好坏比翻一倍),好坏比取20。z = 20 / math.log(2)q = 600 - 20 * math.log(20) / math.log(2)baseScore = round(q + p * coe[0], 0)
个人总评分=基础分+各部分得分
2.部分评分
下面计算各变量部分的分数。各部分得分函数:
#计算分数函数 def get_score(coe,woe,factor): scores=[] for w in woe: score=round(coe*w*factor,0) scores.append(score) return scores
计算各变量得分情况:
# 各项部分分数x1 = get_score(coe[1], woex1, p)x2 = get_score(coe[2], woex2, p)x3 = get_score(coe[3], woex3, p)x7 = get_score(coe[4], woex7, p)x9 = get_score(coe[5], woex9, p)
我们可以得到各部分的评分卡如下图所示:
各变量的评分标准
八.自动评分系统
根据变量来计算分数,实现如下:
#根据变量计算分数def compute_score(series,cut,score): list = [] i = 0 while i < len(series): value = series[i] j = len(cut) - 2 m = len(cut) - 2 while j >= 0: if value >= cut[j]: j = -1 else: j -= 1 m -= 1 list.append(score[m]) i += 1 return list
我们来计算test里面的分数:
test1 = pd.read_csv("TestData.csv")test1["BaseScore"]=Series(np.zeros(len(test1)))+baseScoretest1["x1"] = Series(compute_score(test1["RevolvingUtilizationOfUnsecuredLines"], cutx1, x1))test1["x2"] = Series(compute_score(test1["age"], cutx2, x2))test1["x3"] = Series(compute_score(test1["NumberOfTime30-59DaysPastDueNotWorse"], cutx3, x3))test1["x7"] = Series(compute_score(test1["NumberOfTimes90DaysLate"], cutx7, x7)test1["x9"] = Series(compute_score(test1["NumberOfTime60-89DaysPastDueNotWorse"], cutx9, x9))test1["Score"] = test1["x1"] + test1["x2"] + test1["x3"] + test1["x7"] +test1["x9"] + baseScoretest1.to_csv("ScoreData.csv", index=False)
批量计算的部分分结果:
批量计算的部分结果
九.总结及展望
本文通过对kaggle上的Give Me Some Credit数据的挖掘分析,结合信用评分卡的建立原理,从数据的预处理、变量选择、建模分析到创建信用评分,创建了一个简单的信用评分系统。
基于AI的机器学习评分卡系统可通过把旧数据(某个时间点后)剔除掉后再进行自动建模、模型评估、并不断优化特征变量,使得系统更加强大。
END.
作者:Carl
来源:知乎
本文为转载分享,如侵权请联系后台删除
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论