
描述统计学是数据挖掘的基础。
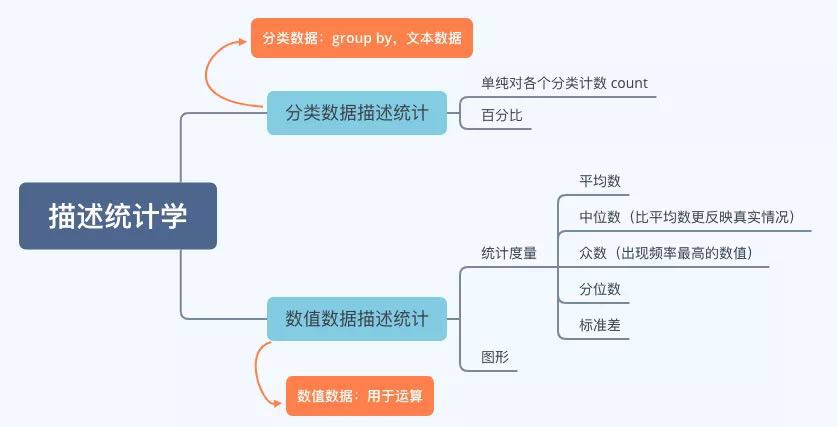
一.分位数
分位数(英语:Quantile),亦称分位点,是指用分割点(cut point)将一个随机变量的概率分布范围分为几个具有相同概率的连续区间。
分割点的数量比划分出的区间少1。
例如:3个分割点能分出4个区间。
常用的有中位数(二分位数)、四分位数(quartile)、十分位数(decile)、百分位数等。
q-quantile是指将有限值集分为q个接近相同尺寸的子集。
分位数指的就是连续分布函数中的一个点,这个点对应概率p。
四分位数(英语:Quartile)是统计学中分位数的一种,即把所有数值由小到大排列,然后按照总数量分成四等份,即每份中的数值的数量相同,处于三个分割点位置的数值就是四分位数。
这3个数叫做:
- 第一四分位数:又称较小四分位数,等于该样本中所有数值由小到大排列后第25%的数字。
- 第二四分位数:又称中位数,等于该样本中所有数值由小到大排列后第50%的数字。
- 第三四分位数:又称较大四分位数,等于该样本中所有数值由小到大排列后第75%的数字。
pandas.DataFrame.quantile()和numpy.percentile()计算结果一样。
pandas中有describe方法显示四分位数。
例子:
>>> ps = pd.DataFrame([1,2,3,4,5,6,7,8,9,10,11,12])>>> ps.describe() 0count 12.000000mean 6.500000std 3.605551min 1.00000025% 3.750000 #分割点50% 6.50000075% 9.250000max 12.000000
>>> ps.quantile(0.25)0 3.75 >>> ps.quantile(0.5)0 6.5
>>> np.percentile(ps, 50)6.5
分析方法中的二八法则,结合分位数来使用。
二.标准差&方差
描述数据离散程度。数据的波动性。
- 方差:统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。
- 标准差:对方差开跟号。因为方差会消除数据的单位。(元,缺少了业务的含义,所以引入标准差。)
例子:
a=[10,10,10,11,12,12,12]
b=[3,5,7,11,15,17,19]
a和b的中位数和平均数都11,但他们的方差不一样,a的方差<b的方差。
a数据集的离散程度小于b数据集。
均值+/-标准差,这个范围的数据占了整个数据集的大部分,可以说数值大部分在这个范围内波动。
阐述:数据集的平均值是m, 大部分在m+/-方差的范围内波动。
例子:
#还是上面的数据>>> ps.std()0 3.605551
三.权重统计:数据标准化之Z-Score标准化
Z-Score标准化是标准化的一种。可以发现数据中的趋势。
(样本i-均值)/标准差=数据标准化
它们可以通过现有样本进行估计。在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
#附加,mac-numbers使用公式的方法:1.单元格按=号,右侧弹出函数列,选择函数,然后选择需要计算的单元格。2.完成计算后,这个公式可以复制ctr+c, 然后选择整列,再ctr+v,应用到整列- 或者点击单元格,方框正下方有个小黄点,可以下拉。
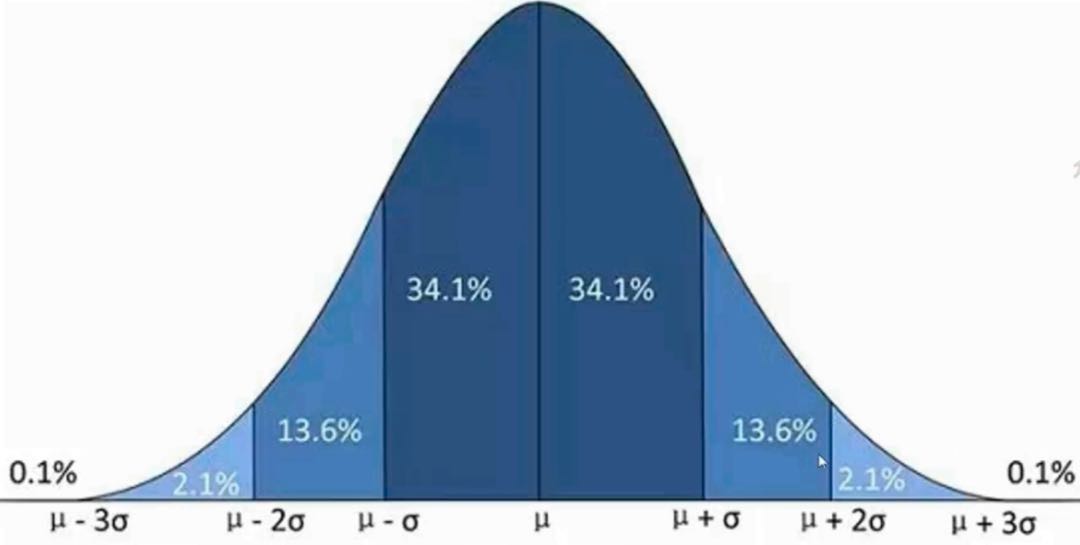
四.切比雪夫定理
19世纪俄国数学家切比雪夫研究统计规律中,论证并用标准差表达了一个不等式,这个不等式具有普遍的意义,被称作切比雪夫定理,其大意是:

任意一个数据集中,位于其平均数m个标准差范围内的比例(或部分)总是至少为1-1/m2,其中m为大于1的任意正数。
对于m=2,m=3和m=5有如下结果:
- 所有数据中,至少有3/4(或75%)的数据位于平均数2个标准差范围内。
- 所有数据中,至少有8/9(或88.9%)的数据位于平均数3个标准差范围内。
- 所有数据中,至少有24/25(或96%)的数据位于平均数5个标准差范围内 。
即随机数据集合,只有知道平均数和标准差,就知道这个数据集合的大概分布。
例子:某大学100个学生平均成绩70分,标准差5分,问有多少学生的成绩在60·80分?
答:
60-70=-10
80-70= 10
60/80位于2个标准差。
1-1/22 =3/4=75%。
所以60~80分的学生至少占75%
五.描述统计的可视化
1.box箱线图
用4分位数来表示数据的范围分布。
- 箱体表示占一半数量的数值
- 下四分位数到下边界,表示1/4数量的数值 (较小数)
- 上四分位数到上边界,表示1/4数量的数据 (较大数)

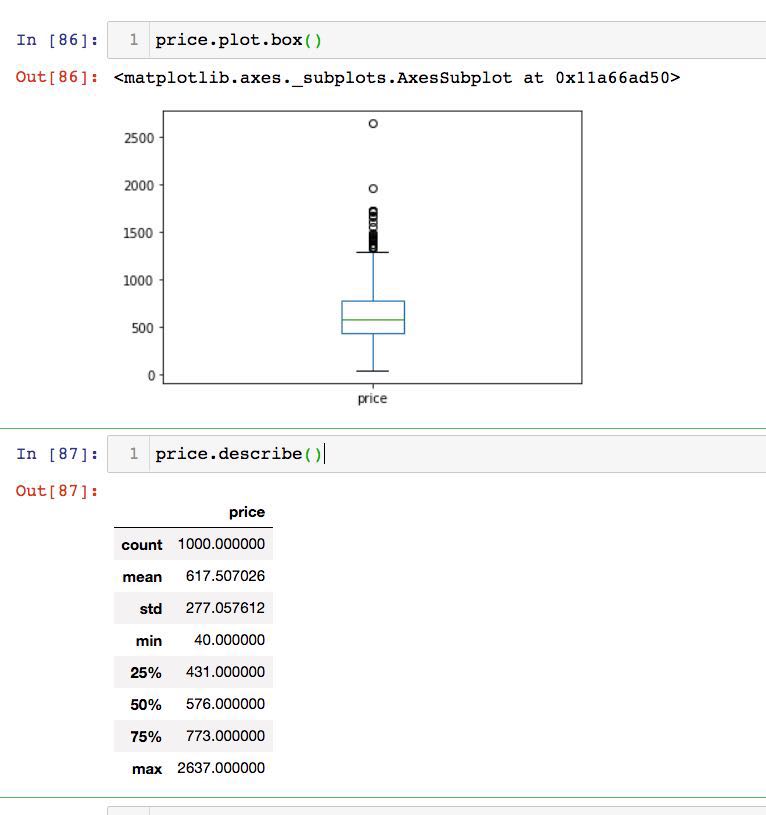
注意: 上面50%的价格分布在较小的区域
2.直方图 histogram
x轴的数据,每个范围/值都是唯一的。
在统计学中,直方图是一种对数据分布情况的图形表示,是一种二维统计图表,它的两个坐标分别是统计样本和该样本对应的某个属性的度量,以长条图的形式具体表现。
因为直方图的长度及宽度很适合用来表现数量上的变化,所以较容易解读差异小的数值。
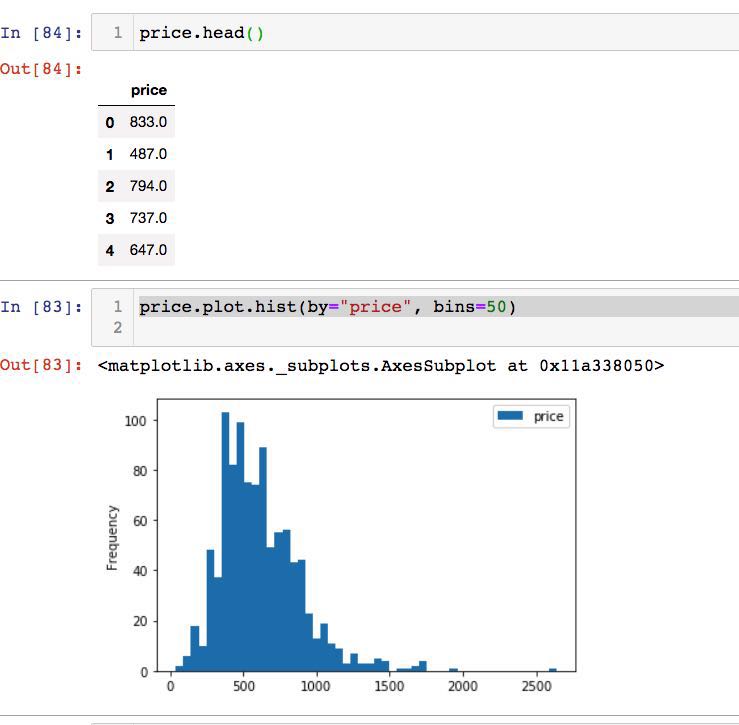
总共有数据1000个,使用参数bins=50, x轴的数据被等分成50份。
六.概率
1.交集和并集
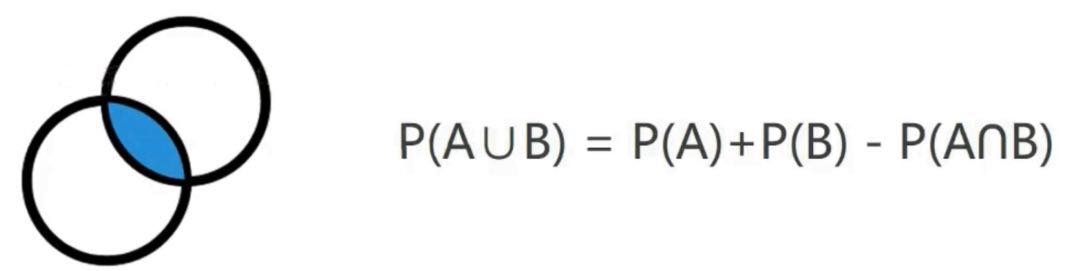
解释:A并B,有一部分是重合的,重合部分就是交集。计算A并B时,多了一块交集,所以需要减去多出的一块交集。
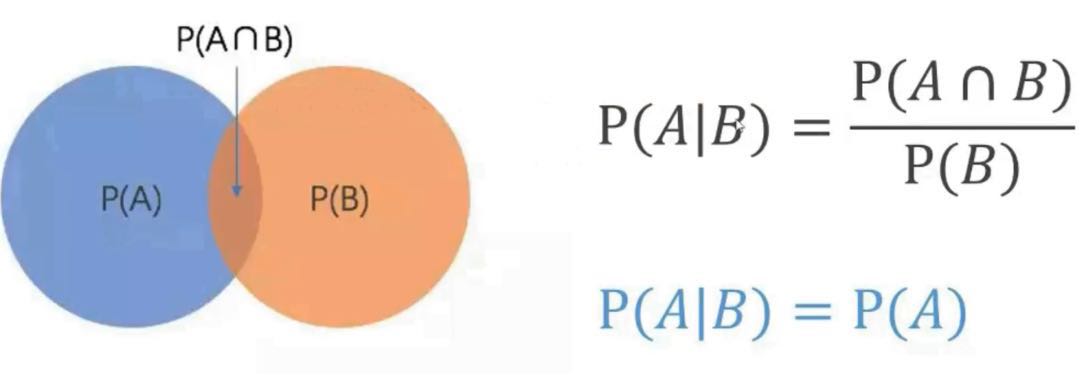
解释:用公式和符号表示: 在B已经发生的情况下,A发生的概率。圆A和B相交的面积/圆B的面积=在B已经发生的情况下,A发生的概率。
七.贝叶斯定理
例1:如果某种疾病的发病率为千分之一。现在有一种试纸,它在患者得病的情况下,有99%的准确率判断患者得病,在患者没有得病的情况下,有5%的可能误判患者得病。现在试纸说一个患者得了病,那么患者真的得病的概率是多少?
可以用分析图来分析:
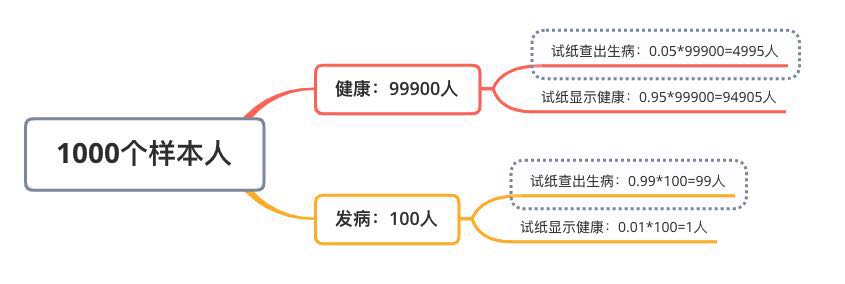
所以用试纸查出患者占总样本人数的比例为:(4995+99)/100000=5.094 %
但实际上这部分查出有病的人中(5094人),有4995人是误诊的。所以查出的这部分人中只有1.943%是真生病的人。
先验概率(历史经验):
- P(A1)表示生病人群的概率:0.1%
- P(A2)表示健康人群的概率:99.9%
新信息:
- 事件B表示用试纸检测,并判断生病。
- P(B|A1):是真实患者的条件下,试纸查出来是患者的概率:99%
- P(B|A2): 是健康人群条件下, 试纸误判是患者的概率:5%
应用贝叶斯定理:
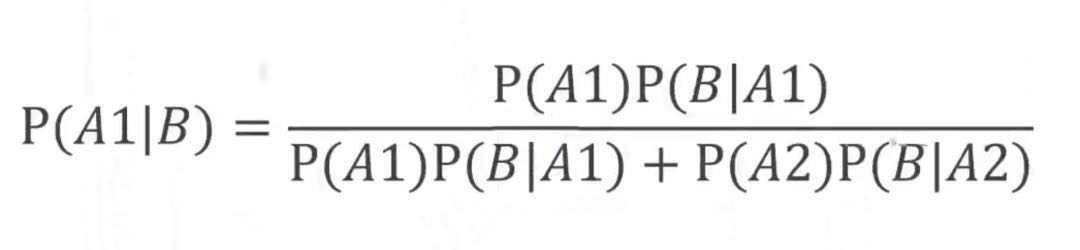
求得后验概率:
P(A1|B) 即用试纸检查出是患者的条件下,是真实患者的概率。1.943%
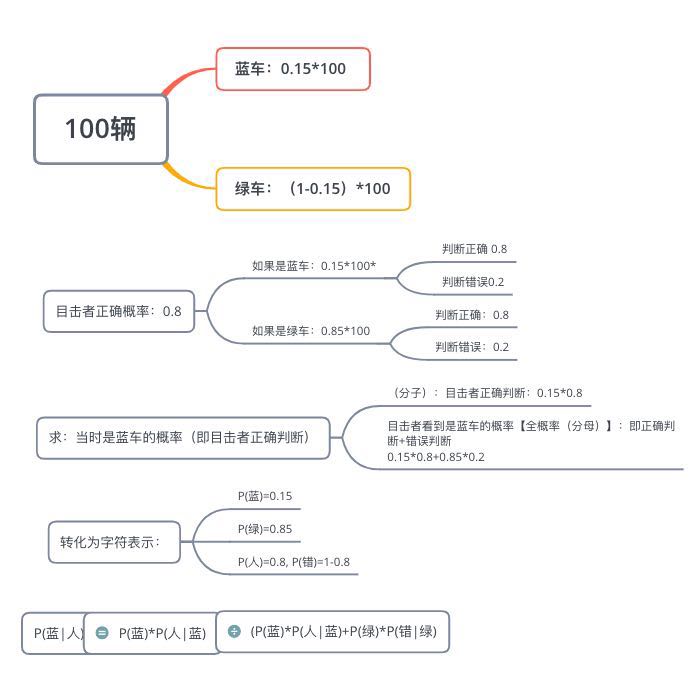
例2:一辆出租车在夜晚肇事之后逃逸,一位目击证人辨认出肇事车辆是蓝色的。已知这座城市 85% 的出租车是绿色的,15% 是蓝色的。警察经过测试,认为目击者在当时可以正确辨认出这两种颜色的概率是 80%, 辨别错误的概率是 20%. 请问,肇事出租车是蓝色的概率是多少?
注意,如果脑子乱,没有思路:
- 纸上画图(xmind思维导图)
- 假设一个真实的样本数据。
END.作者:Mr-chen来源:博客园本文为转载分享,如侵权请联系后台删除
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论