
关于聚类算法,大家应该都有一定的了解,就是把一群人或者其他数据分成若干类,大家习惯叫做n类,那这个n是怎么确定的呢?很多人可能会说靠拍,靠拍确实也不是不可以。但是总觉得不太科学。那应该怎么办呢?因为聚类是无监督学习,也就是没有正确答案,没有办法知道分几类是正确的,那应该怎么办呢,是不是只能靠拍了?
我们想想聚类的本质,其实就是把一群人(暂且可以理解成我们是对人进行分类)分成若干类,我们希望得到的一个结果就是,类与类之间差别(距离)要尽可能的大,同一类内部之间的差别要尽可能小,因为这样的结果才是我们聚类的目的呀。明确了目标以后,我们就可以开始尝试了,看n取多少的时候结果比较接近我们的目标。这个目标有一个比较正式的名字叫做轮廓系数(silhouette coefficient)。
轮廓系数的计算步骤如下:
计算样本i到同一类中其他样本的平均距离ai。ai越小,说明样本i与同类中其他样本的距离越近,即越相似。我们将ai称为样本i的类别内不相似度。
计算样本i到其他类别的所有样本的平均距离bi,称为样本i与其他类之间的不相似度。bi越大,说明样本i与其他类之间距离越远,即越不相似。
根据样本i的簇内不相似度ai和簇间不相似度bi ,定义样本i的轮廓系数为:
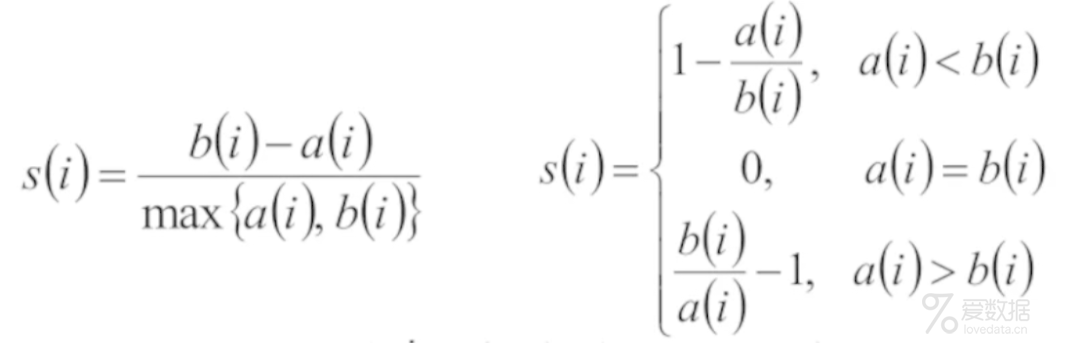
si的值介于[-1,1]之间,越接近于1说明bi越大ai越小,类别内部越相似,类别之间越不相似;越接近于0说明类别内部和类别之间的距离差不多,分界线很不明显;越接近于-1说明类别之间越相似类别内部反而不相似。
了解清楚原理以后,我们来看下在Python中怎么实现,这个系数在Sklearn库中是有现成的包可以供我们使用的:
silhouette_score:是获取模型总体的轮廓系数
silhouette_samples:是获取每个样本的轮廓系数
接下来我们来一个实战案例给大家演示下:
首先把我们需要用到的包导入进来:
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import numpy as np
接下来生成一组模拟数据以备模型使用:
X, y = make_blobs(n_samples=500,
n_features=2,
centers=4,
cluster_std=1,
center_box=(-10.0, 10.0),
shuffle=True,
random_state=1)
生成数据以后,开始训练模型:
kmeans = KMeans(n_clusters = 3,random_state = 0)
kmeans.fit(X)
pred_y = kmeans.predict(X) # 预测点在哪个聚类中
print(silhouette_score(X, pred_y))
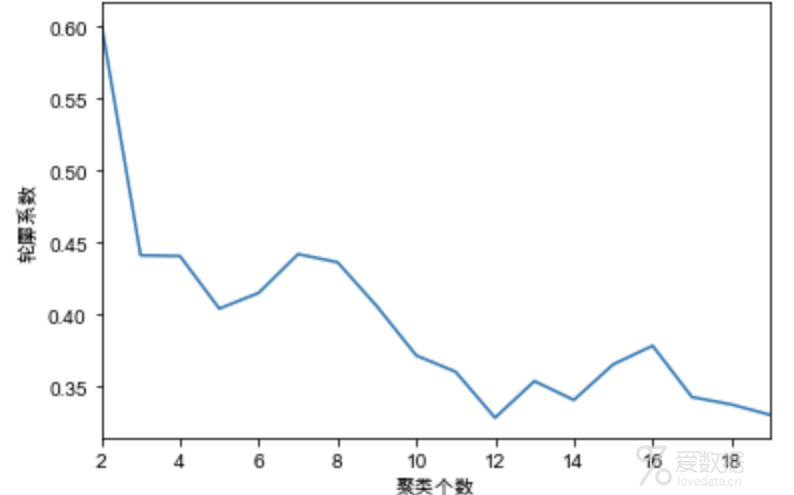
上面模型中我们随便给定一个类别数3,会得出如果把我们的模拟数据生成3类的话轮廓系数是0.58。3个是不是最好的类别数呢?不知道,我们就试吧,写一个for循环,遍历[2,20]类,代码如下:
score = []
for n in range(2,20):
kmeans = KMeans(n_clusters = n,random_state = 0)
kmeans.fit(X)
pred_y = kmeans.predict(X) # 预测点在哪个聚类中
score.append([n,silhouette_score(X, pred_y)])
pd.DataFrame(score).set_index(0).plot(legend = False)
plt.xlabel("聚类个数")
plt.ylabel("轮廓系数")
运行上面代码可以得到不同类别数对应的轮廓系数值,我们根据轮廓系数和业务需求双重目标来确定最佳的类别数。为什么还要考虑业务需求呢?因为我们聚类的结果一般都是需要拿给业务用的,比如用在精细化运营上,如果类别太多,可能不利于业务使用。所以要综合考虑轮廓系数和业务诉求。
如果想要获取每个样本的轮廓系数,则可以使用silhouette_samples函数,使用方法与silhouette_score是一样的,也是需要给定x值和预测的y值。
silhouette_samples(X, pred_y)
掌握了轮廓系数法,以后聚类个数再也不用靠拍了。
End.
作者:张俊红
来源:俊红的数据分析之路
本文已和作者授权,如需转载请与作者授权
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论