
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import plotly.graph_objs as go
import plotly as py
py.offline.init_notebook_mode()
pyplot = py.offline.iplot
import warnings
warnings.filterwarnings("ignore")
一.数据读取
data = pd.read_excel("./learn/lipsticks.xlsx")
data.head(5)
二.数据清洗
data.shape
data.info()
重复数据处理
重复值进行删除处理
data = data.drop_duplicates()
data.shape
并没有重复数据
缺失值处理
查看是否有缺失值
data.apply(lambda x: sum(x.isnull())/len(x),axis=0)
由返回值可知可以进行填充的缺失值有:原价、是否自营、店铺
- 原价填充为折扣价(无原价默认折扣价等于原价)
- 是否自营填充为非自营
- 店铺填充为非自营
进行填充
data.fillna({"原价":data["折扣价"],"是否自营":"非自营","店铺":"非自营"},inplace=True)
确认填充完成
data.isnull().any()
其它数据处理
浏览修改后的数据发现原价中包含有"新人价"、"x.x折"
- 新生成一列价格price_0: 新人价用折扣价填充
- 新生成一列价格price_1: x.x折用原价(= 折扣价/x.x折)填充
data[["原价","折扣价"]].head()
新人价用折扣价填充,创造原价无空值的一列
data["price_0"] = data["原价"].replace("新人价",data["折扣价"])
x.x折用原价(= 折扣价/x.x折)填充
#提取折扣价数字
def cut_price(x):
position = x.find("¥") # 找到则返回下标,否则返回-1
price = float(x[position+1:])
return price
data["disprice"] = data["折扣价"].apply(cut_price)
#提取折扣计算出原价
def cut_discount(x,y):
position = x.find("¥")
if position != -1: #说明为已为价格数据,直接返回
price = float(x[position+1:])
return price
else: #说明为折扣数据,需要计算出原价才可返回
discount = float(x[:len(x)-1])
price = (y*10)/discount
return price
data["price_1"] = data.apply(lambda x: cut_discount(x["price_0"],x["disprice"]),axis=1)
data["price_1"] = data["price_1"].round(2)
最后为比较打折力度,新生成一列"discount"
data["discount"] = data.apply(lambda x: x["disprice"]/x["price_1"],axis=1).round(2)
查看清洗结果
data.apply(lambda x: sum(x.isnull())/len(x),axis=0)
data.info()
三.数据分析
探索品牌热度及占比
fig, axes = plt.subplots(2, 1, figsize=(12, 16))
ax1 = data.groupby("品牌")["评论数"].sum().sort_values(ascending=True).plot(
kind="barh", ax=axes[0],width=0.8, alpha=0.8, color="#6385a7")
ax1.set_ylabel("品牌", fontsize=16)
ax1.set_title("品牌评论数总和", fontsize=18)
ax2 = data["国家"].value_counts().plot(
kind="pie",
ax=axes[1],
autopct="%.1f%%",
pctdistance=0.8,
shadow=True,
labels=data["国家"].value_counts().index,
labeldistance=1.1,
startangle=45,
radius=1.2,
wedgeprops={"linewidth": 1.5, "edgecolor": "k"},
textprops={"fontsize": 14, "color": "k"}
)
ax2.set_title("各产地国家占比", fontsize=18)
plt.subplots_adjust(hspace=.2)
plt.show()
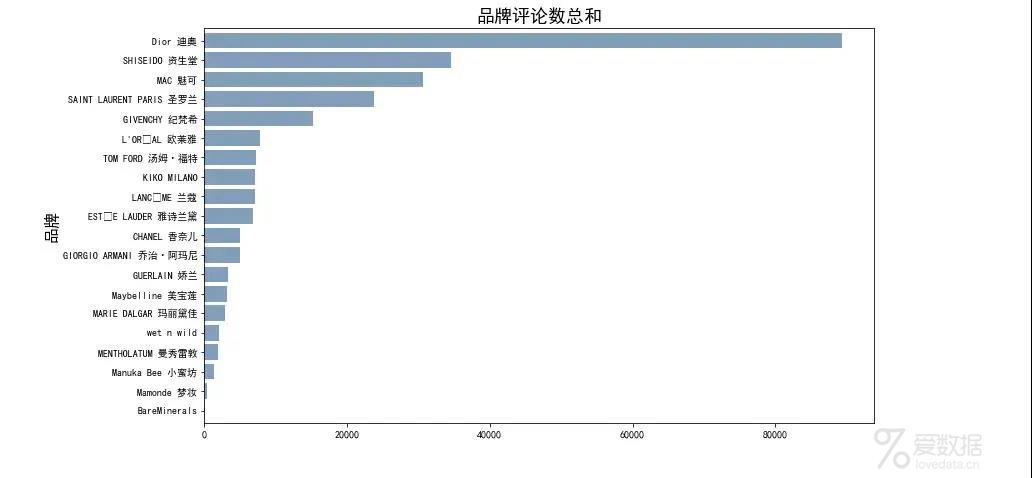
品牌评论数总和
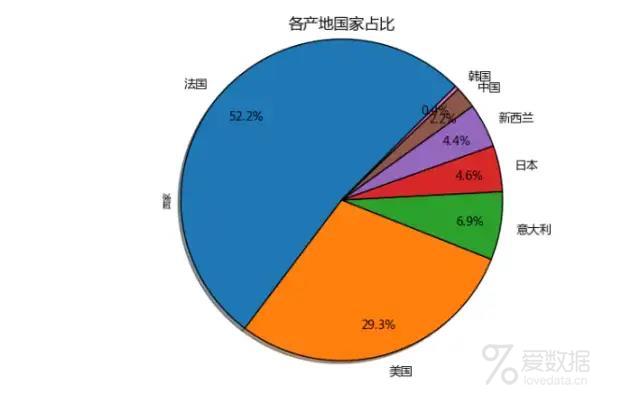
各产地国家占比
从可视化图表可以看出,网易考拉上迪奥的市场份额占比最大,资生堂、圣罗兰、纪梵希、MAC品牌的口红属于第二梯队,这些热门品牌中多数为法国,占52.2%达到一半以上,美国品牌的口红占比为29.3%。
各个品牌的SKU单品数量
plt.figure(figsize=(12,8))
data["品牌"].value_counts().sort_values(ascending=True).plot(kind="barh",width=0.8,alpha=0.6,color="#6385a7")
plt.title("各品牌SKU数",fontsize=24)
plt.show()
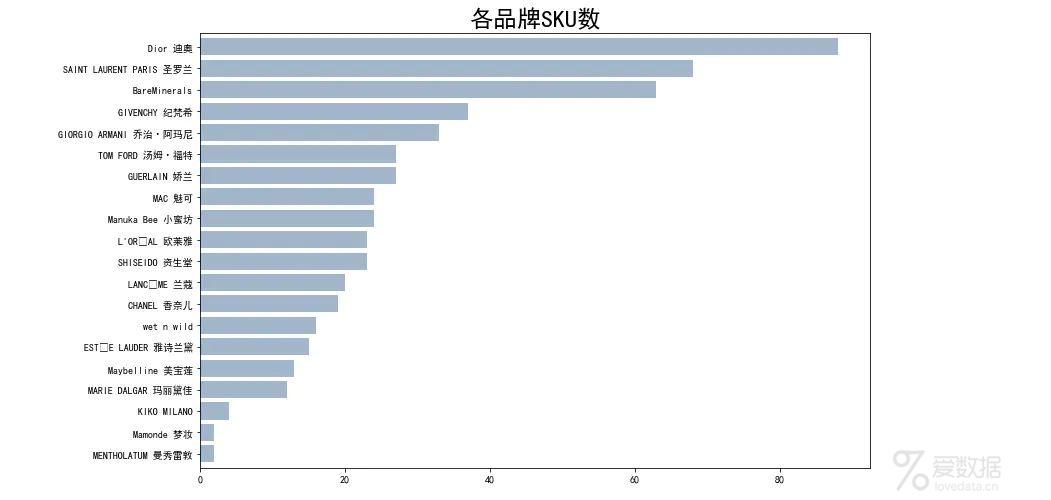
各个品牌的SKU单品数量
考拉海淘网上的口红大多来自于法国、美国,品牌中迪奥是消费者的主要选择;而位于最后的KIKO,梦妆,曼秀雷敦则比较小众;
热门品牌和热门单品的TOP10
plt.figure(figsize=(12, 8))
data_comments_mean = data.groupby("品牌")["评论数"].mean().sort_values(ascending=True)
data_comments_mean[-10:].plot(
kind="barh", width=0.8, alpha=0.4, color="r")
plt.yticks(fontsize=16)
plt.ylabel("品牌",fontsize=20)
plt.title("热门品牌TOP10",fontsize=24)
plt.show()
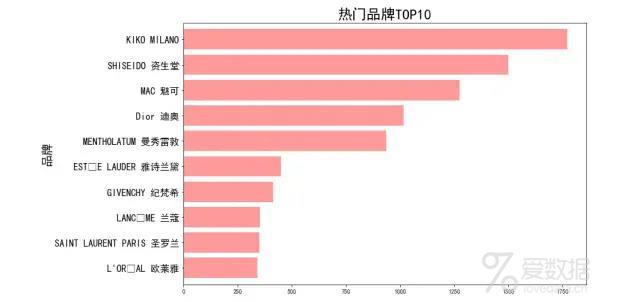
热门品牌TOP10
data_hot = data.groupby("商品标题")["评论数"].max().sort_values(ascending=True)
plt.figure(figsize=(16,12))
data_hot[-10:].plot(kind="barh",width=.8,color="r",alpha=.6)
plt.yticks(fontsize=20)
plt.xticks(fontsize=20)
plt.ylabel("品牌标题",fontsize=20)
plt.title("热门单品TOP10",fontsize=24)
plt.show()
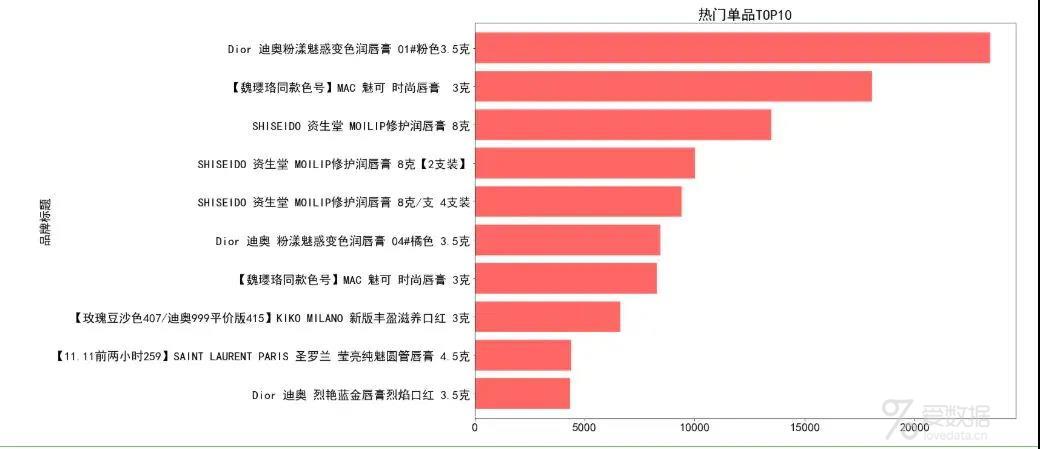
热门单品TOP10
对不同品牌定价分析
fig= plt.figure(figsize=(16,8))
data.groupby("品牌")["disprice"].mean().sort_values(ascending=False).plot(
kind="bar",width=0.8, alpha=0.6, color="#6385a7", label="价格")
y0 = data["disprice"].mean()
plt.axhline(y0, 0, 5,color="r", label="平均价格")
plt.ylabel("价格")
plt.title("各品牌折后价格比较", fontsize=16)
plt.legend(loc="best")
plt.show()

各品牌折后价格比较
plt.figure(figsize=(16, 12))
x = data.groupby("品牌")["discount"].mean()
y = data.groupby("品牌")["评论数"].mean()
s = data.groupby("品牌")["price"].mean()
txt = data.groupby("品牌")["商品标题"].count().index
sns.scatterplot(x, y, size=s,sizes=(100,1500),data=data)
for i in range(len(txt)):
plt.annotate(txt[i], xy=(x[i], y[i]))
plt.ylabel("热度", fontsize=20)
plt.xlabel("折扣", fontsize=20)
plt.axvline(data["discount"].mean(),0,2000,color="r",label="discount_average")
plt.legend()
plt.show()
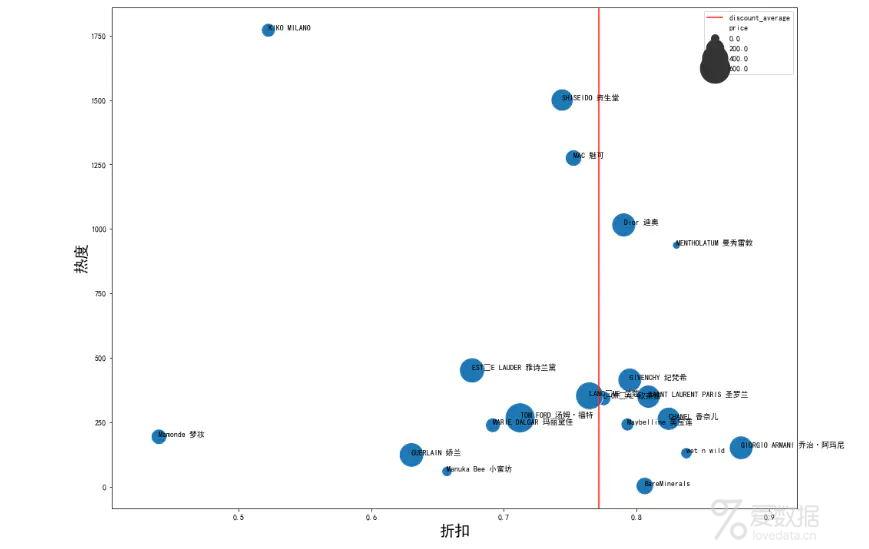
热度与折扣的关系图
梦妆折扣力度最大且价格低,阿玛尼折扣力度最小且价格高;TOM FORD定价最高,曼秀雷敦定价最低。
价格高的口红打折力度较小
口红价格主要分为两个档位,250和100元,热门品牌主要在低价位
口红出售的渠道分析
fig=plt.figure(figsize=(16,12))
ax1 = fig.add_subplot(221)
data["是否自营"].value_counts().plot(
ax=ax1,
kind="pie",
autopct="%.1f%%",
pctdistance=0.8,
shadow=True,
wedgeprops={"edgecolor":"k","linewidth":1.5},
textprops={"fontsize":"14","color":"k"}
)
ax2 = fig.add_subplot(222)
sns.scatterplot(x="disprice",y="discount",hue="是否自营",data=data,ax=ax2)
plt.xlim((0,800))
plt.title("(非)自营店折扣与定价")
ax3 = fig.add_subplot(223)
sns.boxplot(x="是否自营",y="disprice",data=data,ax=ax3)
plt.ylim((0,600))
ax4 = fig.add_subplot(224)
sns.boxplot(x="是否自营",y="discount",data=data,ax=ax4)
plt.show()
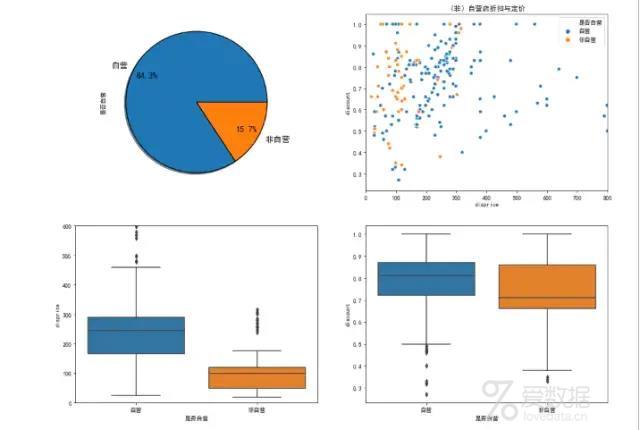
口红出售的渠道分析
口红自营为主,自营的定价普遍高于非自营的口红,且浮动更大;另外自营的折扣力度也稍大。
标签词云图展示
data1 = pd.concat([data["标签1"],data["标签2"],data["标签3"]])
data1.dropna()
data2 = data1.value_counts()
data2
from wordcloud import WordCloud,ImageColorGenerator
from PIL import Image
coloring = np.array(Image.open("tupian.png"))
wc = WordCloud(
font_path="simhei.ttf", #字体路径
background_color="White", #背景颜色
# width=400,
# height=200,
max_font_size=200, #字体大小
min_font_size=6,
mask=coloring, #背景图片
max_words=2000,
relative_scaling=0.1,
repeat=True # 默认为False,是否重复单词或者短语
)
wc.generate_from_frequencies(data2)
image_colors = ImageColorGenerator(coloring)
wc.to_file("lipsticks.png") #图片保存
# 显示图片
plt.figure(figsize=(12,10))
plt.imshow(wc.recolor(color_func=image_colors))
plt.axis("off") #关闭坐标
plt.show()

词云图
End.
作者:Asuana
来源:简书
本文为转载分享,如侵权请联系后台删除
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论