
风险管理是银行业可持续发展的根本。银行风险管理体系建设的目的在于保持资产质量稳定,将风险抵补能力始终控制在合理水平。
在当前经济大环境下,银行业务风险水平上升,金融行业进入强监管时代,各家银行对提升自身风险防控能力的需求日益迫切,而银行传统风险管理体系缺乏灵活性、防控手段较为落后等弊端,与大数据覆盖面广、维度丰富、实时性高和人工智能技术飞速发展的特点相呼应,使银行风控成为大数据和人工智能的热点应用领域和方向。
目前,传统中小银行在将数据驱动方法应用于风控领域(尤其是贷后)仍处于起步阶段,绝大多数还是依赖于专家经验的业务规则,这些撒网式的规则准确率和召回率都不理想,尚不能满足我们对风险防控的要求。因此,引入更多维度的数据,利用机器学习算法深层挖掘数据规律,对完善银行风险预警系统,提升风险防控能力,降低风险损失有着非常重要的意义。
银行数据驱动风控模型介绍
1. 模型分类
巴塞尔协议定义了金融风险类型:市场风险、作业风险、信用风险。我们主要关注的信用风险模型一般包括申请评分、行为评分、催收评分和反欺诈,也就是常说的A(Application score card)卡、B(Behavior score card)卡、C(Collection score card)卡和F(Anti fraud score card)卡。
2. 数据构成
申请评分卡特征项的组成元素主要有:
- 申请者的人口统计数据:年龄、性别、户籍状况、婚姻状况、职业、学历、申请渠道、证件类型、是否黑名单客户、工作年限等
- 申请者家庭财产、负债信息:是否有自有住宅、是否有车、是否有消费贷款、是否有经营贷款、是否在其他金融机构有负债、个人收入、家庭年收入、收入核验状态等
- 所申请的债项相关信息:申请额度、产品期限、利率、贷款目的等
- 银行已有客户在本行的信息:银行已有客户在本行的信息行内消费记录、申请日前6个月咨询次数、行内还款情况
- 征信信息:正在使用的信用产品数、申贷日期前2年逾期次数、上次逾期距今月份数、人行数字解读评分
行为 / 催收评分卡特征项的组成元素主要有:
- 逾期类行为信息:申贷日期前2年逾期次数、上次逾期距今月份数、当前逾期期数
- 还款类行为信息:还款情况、还款时长、已还款比例
- 征信信息:正在使用的信用产品数、人行数字解读评分
- 债项信息:贷款类型、贷款金额
- 人口统计类信息:年龄、性别、户籍状况、婚姻状况、职业、学历、申请渠道、证件类型、是否黑名单客户、工作年限
- 催收类信息:催收次数、催收信息反馈
- 账户信息:应用评分、行为评分、金卡/普卡、信用额度、自动还款、员工标志、额度调整、收益率
3. 模型构建的基本流程
模型构建一般由以下5个步骤构成:数据准备、模型设计、模型开发、模型评估、模型部署与监控。
(1)数据准备
数据准备是评分卡开发的初始阶段同时也是耗时最长的阶段,包括变量粗筛、数据匹配、数据处理、数据质量检查、描述性统计等步骤。
- 变量粗筛:根据业务经验,圈定需要选入的特征变量,确定变量的取数口径。
- 数据匹配:根据客户维一要素(如客户号)匹配客户各个维度的数据。
- 数据处理:经过一系列转换、处理将原始数据处理成可用作模型开发的格式化数据。
- 数据质量检查:检查数据的缺失值。同时,从业务角度考察数据的完整性和准确性。
- 描述性统计:查看数据的基本统计信息。对于分类型特征,查看该特征在各类别的占比以及各类别的违约概率。对于连续型特征,查看特征的平均值、中位数、极值等,查看数据的集中/离散趋势。
(2)模型设计
相关数据采集完毕后,下一步便是模型的设计。模型设计是评分卡开发的关键步骤。在这个过程中,我们将对数据进行初步分析,对整个模型开发的一些参数进行设计,整个模型设计的内容包括:模型细分、表现定义、表现期窗口、分类汇总、建模样本选择。
- 模型细分:可以考虑从产品/客群维度对模型进行细分,这样做的好处一方面可以提升模型的效果,另一方面也更契合业务的需求。
- 表现定义:定义好坏客户,一般可以通过滚定率分析并结合业务场景确定。
- 表现期窗口:圈定一个时间窗口并在这个时间窗口内完成好坏客户的定义。
- 分类汇总:排除项、被拒绝账户、坏账户、中间账户、表现不足账户、好账户、未开户账户等各账户的数量与占比。
- 建模样本选择:在历史数据中筛选出足够数量的好坏样本数构成建模样本。
(3)模型开发
模型的开发阶段包含的主要内容有:特征变量生成、栏位划分、单变量分析、多变量分析、模型评估与验证。这里牵涉到的内容较多,就不展开一一阐述了。
(4)模型评估
评估模型能否达到预期的效果并确保模型的稳定性。主要评估模型的区分能力、稳定性、排序能力和评分分布。检验一般分为样本时间内验证和样本时间外验证。
(5)模型部署与监控
模型有两种部署模式:一是直接将训练好的模型部署至服务器,配置为一个模型服务。模型服务可供其他系统调用,实现在线预测。二是通过模型提炼规则并部署至决策引擎。模型上线后,要对模型的效果及稳定性进行持续监控 ,一般监控模型KS值及PSI值,前者代表模型区分好坏客户的能力,后者代表模型在每个时间周期的变迁程度。
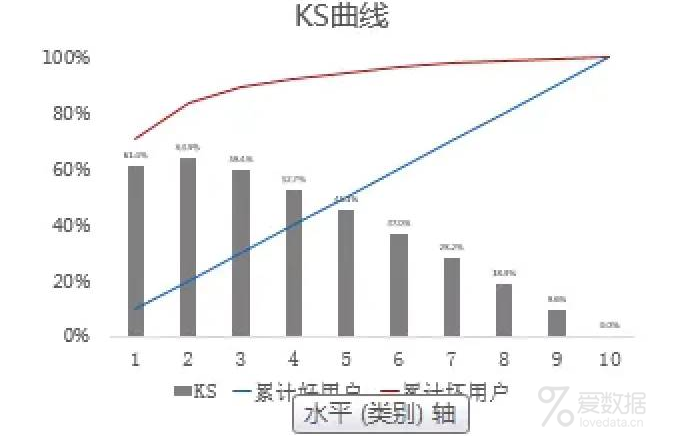
KS值(图片来源于知乎)
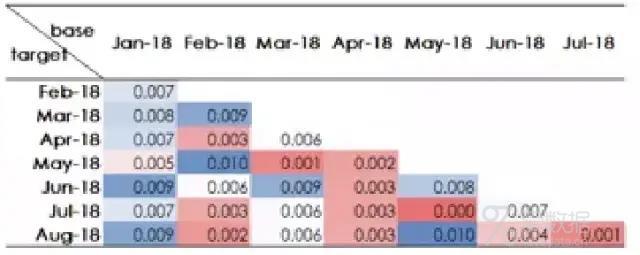
PSI值(图片来源于知乎)
数据驱动评分卡的优势
数据驱动方法的意义在于,当我们对一个问题暂时不能用简单而准确(一般真实的原理都是简单而准确的)的方法解决时,我们可以根据以往的历史数据,构造出近似的模型来逼近真实情况,这实际上是用计算量和数据量来换取研究时间。得到的模型虽然和真实情况有偏差但是足以指导实践。
——吴军博士《智能时代》
当前,随着大数据以及数据采集、存储、分析等技术的快速发展,几乎所有公司都在尽可能充分利用数据来获取竞争优势。这个进程中,大数据也带来了公司商务管理和决策的根本转变,这个转变被定义为数据驱动的决策,其概念表现为公司的管理决策尽可能基于数据和数据分析,而非是更多的依赖于业务人员的直觉和经验。风控领域亦是如此。相对于传统的专家评分,数据驱动评分有如下几点优势:
1. 数据驱动更为客观
数据驱动评分卡的构建过程中,数据更为充分,每个环境都有相应的数据论证和统计分析。并且可以通过更为深层次的挖掘数据的内涵,提取出更为深入和准确的洞察信息,降低了业务人员在决策过程中的介入和参与,从而减少个体因为经验、情绪以及信息不足而导致的偏差,使得评分更为客观。此外,可以推想,更为客观透明的评分机制也可能将得到更多人员的信任和支持,从而提升评分卡的效力和执行效果。
2. 数据驱动更适用于不断变化的决策环境
外部经济形势变化、政策调整以及公司业务的变动都会对模型的效果产生影响。相较于传统的利用专家业务规则的评分卡,数据驱动评分卡不仅引入了业务数据还将人口统计信息、行为数据、账户信息、外部数据纳入决策范围,使得数据评分卡在面对环境变化时有更为稳定的表现。同时,数据驱动评分卡可以实现自动化的更新,根据新的历史数据调整各指标在模型中的权重,以达成对新数据更好的预测效果。
3. 数据驱动使个体更具区分度
"机器学习+大数据"的模式使得数据驱动评分卡构建出的模型更复杂也更具精细化。比如业内常见的数据驱动评分卡中,标准分为660分,好坏客户比每翻一倍,分数增加20分。相对于专家评分卡,数据驱动评分卡中的客户评分更为分散,这也意味着个体与个体之间更具区分度,业务人员有更大空间去制定精细化的应用策略。
参考:
https://www.iyiou.com/p/55066.html 蒋韬:银行风险与智能应用的深深与浅浅
https://zhuanlan.zhihu.com/p/36539125 玩转逻辑回归之金融评分卡模型
https://www.zhihu.com/lives/1053679649619554304 黄志翔:互联网金融信用风险模型大揭秘
End.
作者:数据分析刀刀
来源:简书
本文为转载分享,如有侵权请联系后台删除
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论