
一.介绍
预测股票市场如何表现是最困难的事情之一。预测涉及很多因素-物理因素和生理因素,理性和非理性行为等。所有这些因素共同导致股票价格波动,很难以高精度预测。
我们可以将机器学习作为该领域的游戏规则改变者吗?使用有关组织的最新公告,季度收入结果等特征,机器学习技术有可能发掘出我们以前没有看到的模式和见解,并且可以用来做出准确无误的预测。

本文背后的核心思想是展示如何实现这些算法,因此我将简单描述这些技术并提供相关链接以便在必要时了解概念。如果你是时间序列世界的新手,我建议首先阅读以下文章:
二.理解问题描述
我们很快就会深入探讨本文的实现部分,但首先要确定我们要解决的问题。
基本上,股票市场分析分为两部分-基本面分析和技术分析。
- 基本面分析涉及根据当前的商业环境和财务业绩分析公司未来的盈利能力。
- 另一方面,技术分析包括阅读图标和使用统计数据来确定股票市场的趋势。
你可能已经猜到,我们的重点将放在技术分析部分。我们将使用Quandl的数据集(你可以在这里查找各种股票的历史数据),对于这个特定的项目,我使用了"塔塔全球饮料"的数据。是时候深入了!
我们将首先加载数据集并为问题定义目标变量:
源码如下:
# 导入包
import pandas as pd
import numpy as np
# 在notebook内绘图
import matplotlib.pyplot as plt
%matplotlib inline
# 设置图形大小
from matplotlib.pylab import rcParams
rcParams["figure.figsize"] = 20,10
# 标准化数据
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
# 读取文件
df = pd.read_csv("data.csv")
# 打印头部
df.head()
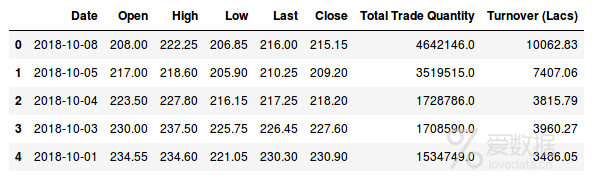
数据集中有多个变量-date(日期),open(开盘价),high(最高价),low(最低价)last(最后交易价)close(收盘价),total_trade_quantity(总交易额)和turnover(成交量)。
- "开盘价"和"收盘价"表示股票在特定日期交易的起始和最终价格。
- "最高价","最低价"和"最后交易价"代表当天股票价格的最高,最低和最后价格。
- "总交易额"是当天买入或者卖出的股票数量,而"营业额"(Lacs)是特定公司在特定日期的营业额。
另一个需要注意的重要事项是市场在周末和公共假期休市。再次注意上面的表格,缺少一些日期值-2018/10/2,2018/10/6,2018/10/7。在这些日期中,2号是国定假期,6号和7号是周末。
损益计算通常由当天股票的收盘价确定,因此我们将收盘价视为目标变量。
让我们绘制目标变量图表,以了解它在我们数据中是如何形成的:
源码如下:
# 将索引设置为日期
df["Date"] = pd.to_datetime(df.Date,format="%Y-%m-%d")
df.index = df["Date"]
# 图表
plt.figure(figsize=(16,8))
plt.plot(df["Close"], label="Close Price history")
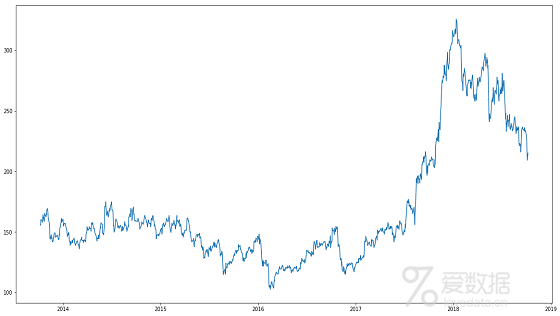
在接下来的部分内容中,我们将探索这些变量并使用不同的技术来预测股票每日的收盘价。
三.移动平均
1.介绍
"平均"很容易成为我们日常生活中最常见的事情之一。例如,计算平均分数以确定整体的业绩,或者找出过去几天的平均温度以了解今天的温度-这些都是我们定期执行的常规任务。因此,这是用于我们数据集进行预测的良好开始。
每天的预测收盘价将是一组之前观察值的平均值。我们将使用移动平均技术而不是简单平均值来预测每组的最新值。换句话说,对于每个后续步骤,在集合中移除最早的观测值同时考虑预测值。这是一个简单的图形,可以帮助你更清晰地理解这一点。

我们将在我们的数据集上实现这些技术。第一步是创建一个仅包含日期和收盘价列的数据框,将其拆分为训练集和验证集以验证我们的预测。
2.实现
# 使用日期和目标变量创建数据框
data = df.sort_index(ascending=True, axis=0)
new_data = pd.DataFrame(index=range(0,len(df)),columns=["Date", "Close"])
for i in range(0,len(data)):
new_data["Date"][i] = data["Date"][i]
new_data["Close"][i] = data["Close"][i]
在将数据拆分为训练集和验证集时,我们不能使用随机拆分,因为这会破坏时间序列。所以我在这里将去年的数据设置为验证集,将4年前的数据设置为训练集。
源码1:
# 拆分训练集和验证集
train = new_data[:987]
valid = new_data[987:]
源码2:
new_data.shape, train.shape, valid.shape
输出:
((1235, 2), (987, 2), (248, 2))
源码:
train["Date"].min(), train["Date"].max(), valid["Date"].min(), valid["Date"].max()
输出:
(Timestamp("2013-10-08 00:00:00"),
Timestamp("2017-10-06 00:00:00"),
Timestamp("2017-10-09 00:00:00"),
Timestamp("2018-10-08 00:00:00"))
下一步是为验证集创建预测值,并使用实际值检查RMSE。
译者注:RMSE为均方根误差,是一种常用的测量数值之间差异的量度。
源码:
# 做出预测
preds = []
for i in range(0,248):
a = train["Close"][len(train)-248+i:].sum() + sum(preds)
b = a/248
preds.append(b)
3.结果
源码:
# 计算rmse
rms = np.sqrt(np.mean(np.power((np.array(valid["Close"])-preds),2)))
rms
输出:
104.51415465984348
只检查RMSE并不能帮助我们理解模型的执行方式。让我们将其可视化以便获得更直观的理解。因此,这是预测值与实际值的关系图。
源码:
# 图表
valid["Predictions"] = 0
valid["Predictions"] = preds
plt.plot(train["Close"])
plt.plot(valid[["Close", "Predictions"]])
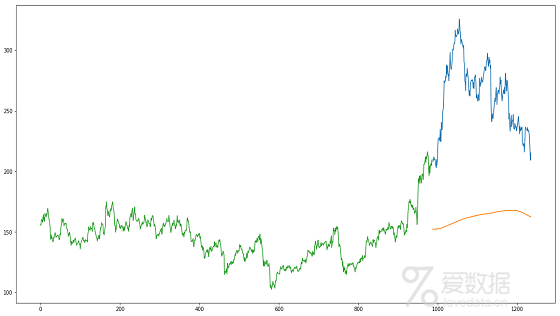
4.推论
RMSE值接近105,但结果不是很有希望(你可以从图表中收集信息)。预测值和训练集中的观测值具有相同的范围(最初呈现增长趋势然后缓慢下降)。
在下一节中,我们将介绍两种常用的机器学习技术-线性回归和kNN,并了解他们对股票市场的表现。
四.线性回归
1.介绍
可以在这个数据上实现的最基本的机器学习算法是线性回归。线性回归模型返回一个确定自变量和因变量之间关系的方程。
线性回归方程可以写成:
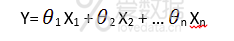
这里的x1,x2,...xn表示自变量,而系数θ1, θ2,… θn表示权重。你可以参考以下文章更详细地研究线性回归:
对于我们的问题描述,我们没有一组自变量。我们只有日期而已。让我们使用日期列来提取如-日,月,年,星期一/星期五等特征,然后拟合线性回归模型。
2.实现
我们将首先按升序对数据集进行排序,然后创建单独的数据集,以便创建任何新特征不会影响原始数据。
源码1:
# 将索引设置为日期值
df["Date"] = pd.to_datetime(df.Date,format="%Y-%m-%d")
df.index = df["Date"]
# 排序
data = df.sort_index(ascending=True, axis=0)
# 创建独立的数据集
new_data = pd.DataFrame(index=range(0,len(df)),columns=["Date", "Close"])
for i in range(0,len(data)):
new_data["Date"][i] = data["Date"][i]
new_data["Close"][i] = data["Close"][i]
源码2:
# 创建特征
# from fastai.structured import add_datepart
from fastai.tabular.transform import add_datepart
add_datepart(new_data, "Date")
new_data.drop("Elapsed", axis=1, inplace=True)
这些创建的特征如下:
‘Year’, ‘Month’, ‘Week’, ‘Day’, ‘Dayofweek’, ‘Dayofyear’, ‘Is_month_end’, ‘Is_month_start’, ‘Is_quarter_end’, ‘Is_quarter_start’, ‘Is_year_end’, and ‘Is_year_start’.
注意:我使用了fastai库中的add_datepart。如果你没有安装它,你可以简单的使用命令pip install fastai。否则,你可以在python中使用简单的for循环创建这些特征。我在下面展示了一个例子。
除此之外,我们可以添加我们认为与预测相关的特征集。例如,我的假设是本周的第一天和最后一天可能会影响股票的收盘价,远远超过其他天。所以我创建一个特征,可以确定某一天是周一/周五还是周二/周三/周四。这里我们能使用以下代码完成:
new_data["mon_fri"] = 0
for i in range(0,len(new_data)):
if (new_data["Dayofweek"][i] == 0 or new_data["Dayofweek"][i] == 4):
new_data["mon_fri"][i] = 1
else:
new_data["mon_fri"][i] = 0
如果星期几等于0或4,则列值将为1,否则为0。同样,你可以创建多个特征。如果你对可以帮助预测股票价格的特征有一些想法,请在评论部分分享。
我们现在将数据拆分为训练集和验证集,以检查模型的性能。
源码:
# 拆分训练集和验证集
train = new_data[:987]
valid = new_data[987:]
x_train = train.drop("Close", axis=1)
y_train = train["Close"]
x_valid = valid.drop("Close", axis=1)
y_valid = valid["Close"]
# 实现线性回归
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(x_train,y_train)
3.结果
源码:
# 做出预测并找到rmse
preds = model.predict(x_valid)
rms = np.sqrt(np.mean(np.power((np.array(y_valid)-np.array(preds)),2)))
rms
输出:
121.16291596523156
RMSE值高于之前的技术,这清楚地表明线性回归表现不佳。让我们看一下图表,并理解为什么线性回归没有做得好:
源码:
# 图表
valid["Predictions"] = 0
valid["Predictions"] = preds
valid.index = new_data[987:].index
train.index = new_data[:987].index
plt.plot(train["Close"])
plt.plot(valid[["Close", "Predictions"]])

4.推论
线性回归是一种简单的技术且容易理解,但是它有一些明显的缺点。使用回归算法的一个问题是模型适应日期和月份列。该模型不考虑预测点的先前值,而是考虑一个月前相同的日期或者一年前相同日期/月份的值。
从上图可以看出,2016年1月和2017年1月,股票价格出现下跌。这个模型预测2018年1月也是如此。线性回归技术可以很好的解决大型商业超市销售之类的问题,其中独立特征对于确定目标值是有用的。
五.k-近邻
1.介绍
这里可以使用另一个有趣的ML算法是kNN(k个最近的相邻值)。基于自变量,kNN找到新的数据点和旧数据点之间的相似性。让我用一个简单的例子来解释。
考虑11个人的身高和年龄。根据给定的特征("年龄"和"身高"),表格可以用图形格式表示,如下所示:
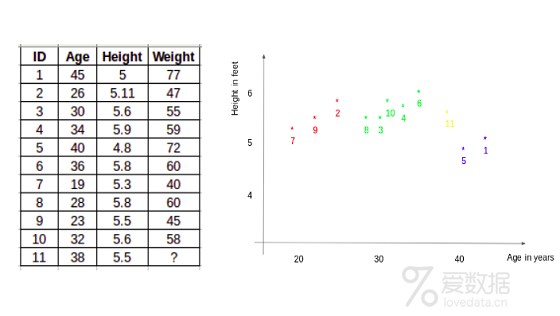
为了确定ID #11的权重,kNN考虑该ID最近相邻值的权重。ID #11的权重预计是其相邻值的平均值。如果我们考虑三个相邻值(k=3),ID #11的权重将是=(77+72+60)/3 = 69.66 kg。

有关kNN的详细了解,请参阅以下文章:
2.实现
源码:
# 导入库
from sklearn import neighbors
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
使用上一节相同的训练集和验证集:
源码:
# 缩放数据
x_train_scaled = scaler.fit_transform(x_train)
x_train = pd.DataFrame(x_train_scaled)
x_valid_scaled = scaler.fit_transform(x_valid)
x_valid = pd.DataFrame(x_valid_scaled)
# 使用gridsearch查找最佳参数
params = {"n_neighbors":[2,3,4,5,6,7,8,9]}
knn = neighbors.KNeighborsRegressor()
model = GridSearchCV(knn, params, cv=5)
# 拟合模型并进行预测
model.fit(x_train,y_train)
preds = model.predict(x_valid)
3.结果
源码:
# rmse
rms = np.sqrt(np.mean(np.power((np.array(y_valid)-np.array(preds)),2)))
rms
输出:
115.17086550026721
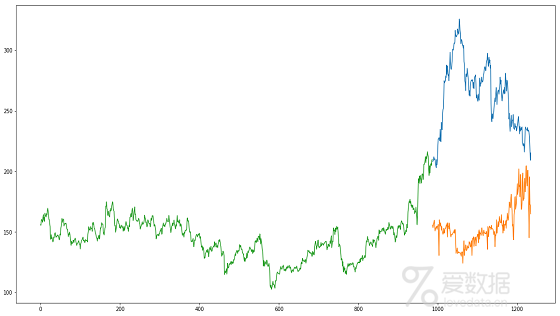
这里RMSE值没有太大差异,但预测值和实际值的图能提供更清晰的理解。
源码:
# 图表
valid["Predictions"] = 0
valid["Predictions"] = preds
plt.plot(valid[["Close", "Predictions"]])
plt.plot(train["Close"])
4.推论
RMSE值几乎与线性回归模型类似,并且图表表现相同的模式。像线性回归一样,kNN也确定了2018年1月的下降,因为这是过去几年的模式。我们可以有把握地说,回归算法在这个数据集上表现不佳。
让我们继续看看一些时间序列预测技术,以了解它们在面对股票价格预测挑战时的表现。
六.自动ARIMA
1.介绍
ARIMA是一种非常流行的时间序列预测统计方法。ARIMA模型考虑了过去值来预测未来值。ARIMA有三个重要参数:
- p(用于预测下一个值的过去值)
- q(用于预测未来值的过去预测误差)
- d(差分的顺序)
ARIMA的参数调整会消耗大量时间。因此,我们将使用自动ARIMA,它自动选择提供最小误差的(p,q,d)的最佳组合。要阅读有关自动ARIMA如何工作的更多信息,请参阅此文章:
使用自动ARIMA构建高性能时间序列模型
2.实现
源码:
from pyramid.arima import auto_arima
data = df.sort_index(ascending=True, axis=0)
train = data[:987]
valid = data[987:]
training = train["Close"]
validation = valid["Close"]
model = auto_arima(training, start_p=1, start_q=1,max_p=3, max_q=3, m=12,start_P=0, seasonal=True,d=1, D=1, trace=True,error_action="ignore",suppress_warnings=True)
model.fit(training)
forecast = model.predict(n_periods=248)
forecast = pd.DataFrame(forecast,index = valid.index,columns=["Prediction"])
2.结果
源码:
rms = np.sqrt(np.mean(np.power((np.array(valid["Close"])-np.array(forecast["Prediction"])),2)))
rms
输出:
44.954584993246954
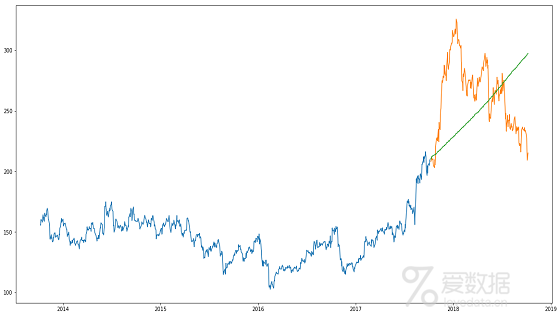
源码:
# 图表
plt.plot(train["Close"])
plt.plot(valid["Close"])
plt.plot(forecast["Prediction"])
4.推论
如前所述,自动ARIMA模型使用过去的数据来理解时间序列中的模式。使用这些值,该模型捕获了该系列中的增长趋势。虽然使用这种技术的预测远比先前实现机器学习模型的预测要好,但这些预测仍然不接近实际值。
从图中可以看出,该模型已经捕捉到了该系列中的一个趋势,但并没有关注季节性部分。在下一节中,我们将实现一个时间序列模型,该模型考虑了系列的趋势和季节性。
七.Prophet
1.介绍
有许多时间序列技术可以在股票预测数据集上实现,但是大多数这些技术在拟合模型之前需要大量的数据预处理。Prophet由Facebook设计和开创,是一个时间序列预测库,不需要数据预处理,实现起来非常简单。Prophet的输入是一个包含两列的数据框:日期和目标值(ds和y)
Prophet试图捕捉过去数据中的季节性,并在数据集很大时很好地运作。这是一篇有趣的文章,以简单直观的方式解释了Prophet:
译者注:Prophet可以理解为预言家或先知,为了保证库名文中会使用英文名称并不直接翻译为中文。
2.实现
源码:
# 导入prophet
from fbprophet import Prophet
# 创建数据框
new_data = pd.DataFrame(index=range(0,len(df)),columns=["Date", "Close"])
for i in range(0,len(data)):
new_data["Date"][i] = data["Date"][i]
new_data["Close"][i] = data["Close"][i]
new_data["Date"] = pd.to_datetime(new_data.Date,format="%Y-%m-%d")
new_data.index = new_data["Date"]
# 准备数据
new_data.rename(columns={"Close": "y", "Date": "ds"}, inplace=True)
# 训练集和预测集
train = new_data[:987]
valid = new_data[987:]
# 拟合模型
model = Prophet()
model.fit(train)
# 预测
close_prices = model.make_future_dataframe(periods=len(valid))
forecast = model.predict(close_prices)
2.结果
源码:
# rmse
forecast_valid = forecast["yhat"][987:]
rms = np.sqrt(np.mean(np.power((np.array(valid["y"])-np.array(forecast_valid)),2)))
rms
输出:
57.494461930575149
源码:
# 图表
valid["Predictions"] = 0
valid["Predictions"] = forecast_valid.values
plt.plot(train["y"])
plt.plot(valid[["y", "Predictions"]])
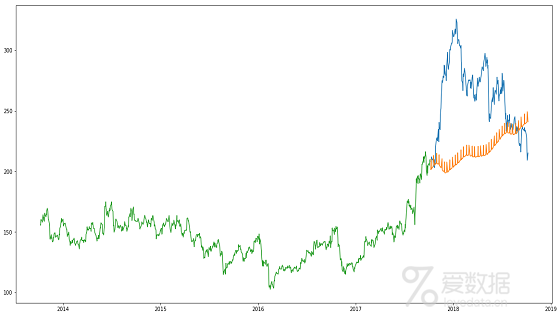
4.推论
Prophet(与大多数时间序列预测技术一样)试图从过去的数据中捕捉趋势和季节性。该模型通常在时间序列数据集上表现良好,但在这种情况下无法达到它的声誉。
事实证明,股票价格没有特定的趋势或季节性。它在很大程度上取决于市场目前的情况,从而价格上涨和下跌。因此,像ARIMA,SARIMA和Prophet这样的预测技术对于这个特定问题不会显示出良好的结果。
让我们继续尝试另一种先进技术-长短期记忆(LSTM)。
八.长短期记忆(LSTM)
1.介绍
LSTM广泛用于序列预测问题,并且已被证明是非常有效的。它们工作得很好是因为LSTM能够存储过去重要的信息,并忘记不重要的信息。LSTM有三个门:
- 输入门:输入门将信息添加到单元状态
- 遗忘门:它删除模型不再需要的信息
- 输出门:LSTM的输出门选择要显示为输出的信息
有关LSTM及其架构的更详细的了解,您可以阅读以下文章:
现在,让我们将LSTM实现为黑盒子,并检查它在我们的特定数据上的性能。
3.实现
源码:
# 导入所需的库
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, Dropout, LSTM
# 创建数据框
data = df.sort_index(ascending=True, axis=0)
new_data = pd.DataFrame(index=range(0,len(df)),columns=["Date", "Close"])
for i in range(0,len(data)):
new_data["Date"][i] = data["Date"][i]
new_data["Close"][i] = data["Close"][i]
# 设置索引
new_data.index = new_data.Date
new_data.drop("Date", axis=1, inplace=True)
# 创建训练集和验证集
dataset = new_data.values
train = dataset[0:987,:]
valid = dataset[987:,:]
# 将数据集转换为x_train和y_train
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(dataset)
x_train, y_train = [], []
for i in range(60,len(train)):
x_train.append(scaled_data[i-60:i,0])
y_train.append(scaled_data[i,0])
x_train, y_train = np.array(x_train), np.array(y_train)
x_train = np.reshape(x_train, (x_train.shape[0],x_train.shape[1],1))
# 创建和拟合LSTM网络
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(x_train.shape[1],1)))
model.add(LSTM(units=50))
model.add(Dense(1))
model.compile(loss="mean_squared_error", optimizer="adam")
model.fit(x_train, y_train, epochs=1, batch_size=1, verbose=2)
# 使用过去值来预测246个值
inputs = new_data[len(new_data) - len(valid) - 60:].values
inputs = inputs.reshape(-1,1)
inputs = scaler.transform(inputs)
X_test = []
for i in range(60,inputs.shape[0]):
X_test.append(inputs[i-60:i,0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0],X_test.shape[1],1))
closing_price = model.predict(X_test)
closing_price = scaler.inverse_transform(closing_price)
3.结果
源码:
rms = np.sqrt(np.mean(np.power((valid-closing_price),2)))
rms
输出:
11.772259608962642
源码:
# 用于绘图
train = new_data[:987]
valid = new_data[987:]
valid["Predictions"] = closing_price
plt.plot(train["Close"])
plt.plot(valid[["Close","Predictions"]])
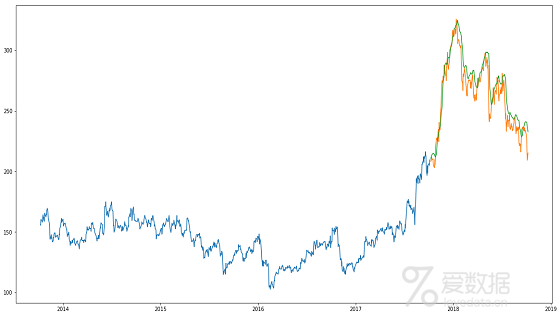
4.推论
哇! LSTM很容易超过我们目前所见的任何算法。可以针对各种参数调整LSTM模型,例如改变LSTM层的数量,添加丢弃值或增加次代的数量。但LSTM的预测是否足以确定股价是涨还是降?当然不是!
正如我在文章开头提到的那样,股票价格受到有关公司的新闻以及其他因素的影响,如公司的非货币化或合并/分拆。还有一些无形因素,事先往往无法预测。
九.结尾
时间序列预测是一个非常有趣的领域,正如我在撰写这些文章时所意识到的那样。在社区中有一种感觉,它是一个复杂的领域,虽然那里有一些事实,但是一旦掌握了基本技术,就不那么困难了。
注:本文中所有文章均可直接点开进行阅读。
End.
作者:简杨君(挖数网特邀认证作者)
本文为中国统计网原创文章,未经允许禁止转载,需要转载请微信联系授权(微信号:ishujiang)
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论