
系列文章:
一.评论数据爬取原理
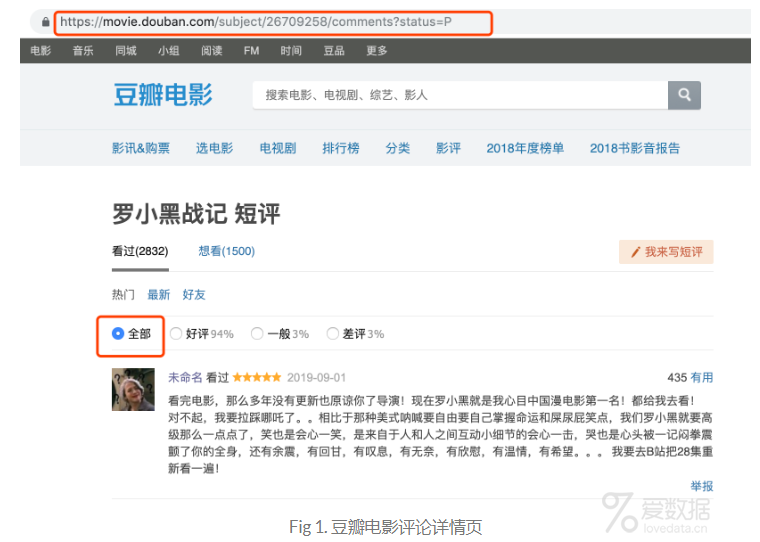
评论数据的爬取是基于Scrapy框架的,本次修改的主要地方是将之前的爬虫API链接改成了评论详情页https://movie.douban.com/subject/26709258/comments?status=P,如Fig 1所示:
通过F12我们可以清楚的看到这个评论的源码细节,每条comment的都是在一个div里面,并且div的class为comment-item,如Fig 2所示。
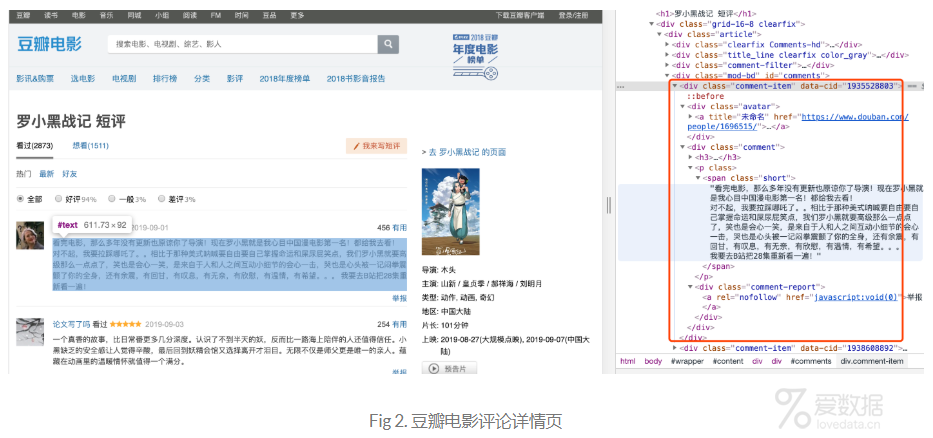
对于这种有规律的html页面,使用scrapy进行处理真的太方便了,我们可以先把comment-item匹配出来,得到的是一个list,然后通过遍历这个list,将每条评论的细节信息抠出来,提取的信息包括:用户名、用户url、用户头像图片url、投票数、评分数、评论内容、评论ID、豆瓣电影ID。提取评论的核心匹配代码如下:
- #先获取item
- item_regx = "//div[@class="comment-item"]"
- comment_item_list = response.xpath(item_regx).extract()
- if len(comment_item_list) > 1:
- for resp_item in comment_item_list:
- print("resp_item======:",resp_item)
- resp_item = etree.HTML(resp_item)
- #用户url
- url_regx = "//div[@class="avatar"]/a/@href"
- url_list = resp_item.xpath(url_regx)
- #用户
- username_regx = "//div[@class="avatar"]/a/@title"
- username_list = resp_item.xpath(username_regx)
- #头像路径
- avator_regx = "//div[@class="avatar"]/a/img/@src"
- avator_list = resp_item.xpath(avator_regx)
- #投票数量
- vote_regx = "//div[@class="comment"]/h3/span/span[@class="votes"]/text()"
- vote_list = resp_item.xpath(vote_regx)
- #评分
- rating_regx = "//div[@class="comment"]/h3/span[@class="comment-info"]/span[contains(@class,"allstar")]/@class"
- rating_list = resp_item.xpath(rating_regx)
- # 内容
- comment_regx = "//div[@class="comment"]/p/span[@class="short"]/text()"
- comment_list = resp_item.xpath(comment_regx)
- #评论ID
- comment_id_regx = "//div[@class="comment"]/h3/span/input/@value"
- comment_id_list = resp_item.xpath(comment_id_regx)
- comment = Comment()
- comment["douban_id"] = douban_id
- comment["douban_comment_id"] = comment_id_list[0] if len(comment_id_list) > 0 else ""
- comment["douban_user_nickname"] = username_list[0] if len(username_list) > 0 else ""
- comment["douban_user_avatar"] = avator_list[0] if len(avator_list) > 0 else ""
- comment["douban_user_url"] = url_list[0] if len(url_list) > 0 else ""
- comment["content"] = comment_list[0] if len(comment_list) > 0 else ""
- comment["votes"] = vote_list[0] if len(vote_list) > 0 else ""
- comment["rating"] = rating_list[0] if len(rating_list) > 0 else ""
- yield comment
当我们提取万当前页面之后,还需要找到下一页,如果存在下一页评论,就将下一页放入到Scrapy的Downloader里面,依次循环。这里说一下,由于在没登录状态下,豆瓣只允许翻100页,所以最后电影数据里面每部电影最多的也就220条。
- #下一页
- regx = "//a[@class="next"]/@href"
- next_url = response.xpath(regx).extract()
- if len(next_url)>0:
- url = "https://movie.douban.com/subject/%s/comments%s" %(douban_id, next_url[0])
- print("=====request Next url================:", url)
- bid = "".join(random.choice(string.ascii_letters + string.digits) for x in range(11))
- cookies = {
- "bid": bid,
- "dont_redirect": True,
- "handle_httpstatus_list": [302],
- }
- yield Request(url, cookies=cookies,meta={"main_url":url})
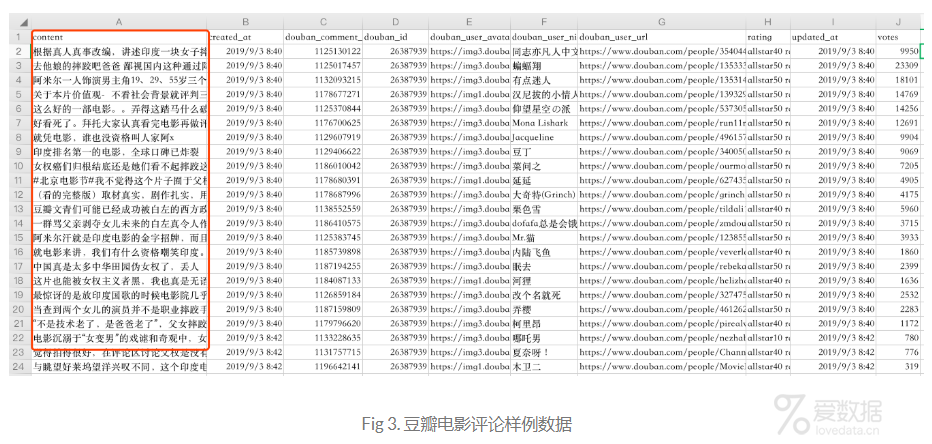
编写完上面的爬虫逻辑之后,配置好代理,启动程序,最后一晚上爬取了350万数据,差不多1G。样例数据如Fig 3所示:
二.评论数据分析
爬取到这么多数据,到底有多少可以用呢?为此笔者对数据进行了简单的探索。在笔者爬取的数据中,存在评论的电影数有7w+部,评论的用户数量有39w+,电影评论总数有350w+。 当然并不是所有的评论都是有效的,长度大于5的评论只有314w,大部分评论都是在30以内,属于短评数据。
这份数据,对于笔者来说,价值还是蛮大的,比如rating评分字段。虽然我们的数据有350w,但是带有rating的数据只有327w+,少了23w+。在这327w的评分里面,由于每部电影最多只能爬取220条,为此笔者对这份数据进行了统计,如Fig 4所示:
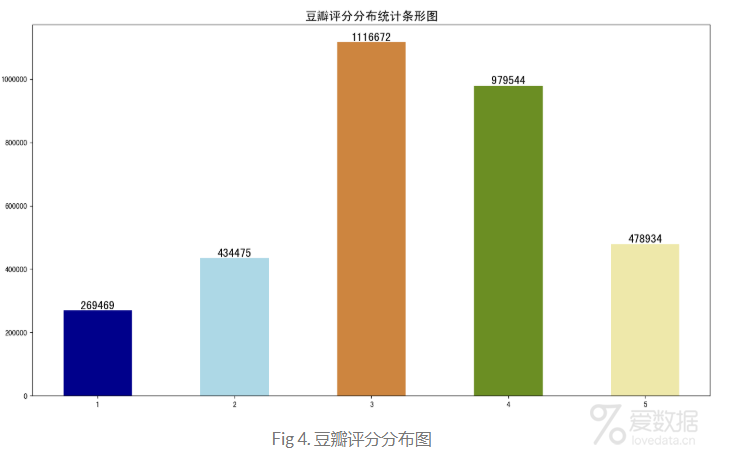
整体上与我们的猜想差不多,呈现一个类似正太分布的图,两端小中间大。通过这部分数据统计,笔者也更加有信心相信这份评论具有代表性。相当于从每部电影里面采样数据,然后得到这些评论,数据量大,基本上也就接近实际的评论分布了。顺手做了张评论词云,没有去掉停留词(看起来没啥感觉),先凑合吧。

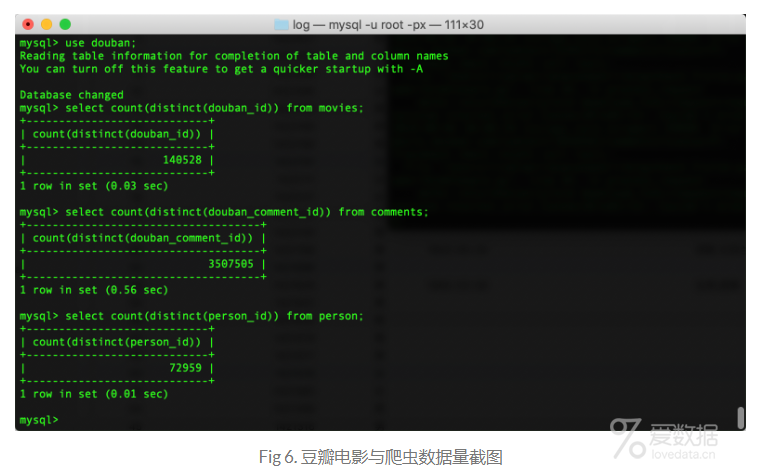
最后爬取的数据量如Fig 6所示。
三.结束语
OK,关于豆瓣评论数据的细节到此为止吧,具体的源码已经上传到笔者的Github中:https://github.com/csuldw/AntSpider,如有需要的,可以参考下,爬虫代码注释还需进一步完善。
四.References
- https://github.com/csuldw/AntSpider
- http://www.csuldw.com/2019/08/18/2019-08-18-building-knowledge-graph-based-on-douban-movie-data/
- http://www.csuldw.com/2019/08/12/2019-08-12-douban-movies-statistics/
- http://doc.scrapy.org/en/latest/topics/architecture.html
End.
作者:拾毅者
来源:『刘帝伟』维护的个人技术博客
本文均已和作者授权,如转载请与作者联系。
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论