
当你的才华还撑不起你的野心时,那你就应该静下心来学习。每次脑子都会有很多想法,每次做了之后,还是觉得需要沉淀下来提升自己更加重要。著名的红叶子理论:一个人职业的成功不在于红叶子的数目多少,而在于他是否具备一片特别硕大的红叶子,这片特别硕大的红叶子不是与生俱来,需要个人的不断努力,准确地识别到最适合发展的红叶子。
目录大纲
0 写在前面的话
1.1 初识Azkaban
1.2 为什么需要任务调度器
1.3 常见几种任务调度器
1.4 Azkaban和Hadoop的关系
1.5 Azkaban 底层原理
2 Azkaban任务调度平台搭建
3 Azkaban Web可视化平台详细介绍以及使用
4 Azkaban API 功能预览
4.1 对接Azkaban,进行二次开发,使其嵌入到系统中
5 平台搭建中的问题总结
1.1 初识Azkaban
起源:Linkedin开源的一个批量工作流调度器
特征:一个工作流内,多个作业可以按照特定的顺序执行
依赖关系:作业之间的顺序关系依靠key-value的形式来建立依赖关系
可视界面:提供可视化web界面
1.2 为什么需要任务调度器
定时任务的出现,可谓大大提高了工作效率。最简单的定时任务,就是你手机的闹钟,你给它一个定时任务,到了指定时间它就叫醒你。程序当中也是如此,那些反复繁琐的操作,可以交给任务调度器去执行,这样既能避免人为的失误,也能让工作人员从无意义的工作中解脱出来!
什么是工作流任务调度器?
很多时候,单一的任务并没有办法满足我们的业务需求,任务直接有关联性,这时候工作流就诞生了!
1.3 常见几种任务调度器
常见的几种工作流任务调度器介绍
Hamake:
- 描述语言:xml
- 依赖机制:data-driven
- 不需要web容器
- 支持hadoop 作业调度
- 运行模式:command line utility
- 事件通知:不支持
- 无需安装
Oozie
- 描述语言:xml
- 依赖机制:explicit
- 需要web容器
- 不支持hadoop作业调度
- 运行模式:daemon
- 事件通知:不支持
- 需要安装
Azkaban
- 描述语言:text file with key/value pairs
- 依赖机制:explicit
- 需要web容器
- 支持Hadoop 作业调度
- 运行模式daemon
- 事件通知:不支持
- 需要安装
Cascading
- 工作流描述语言:Java Api
- 依赖机制:explicit
- 不需要web容器
- 支持hadoop 作业调度
- 运行模式 API
- 事件通知:有
- 无需安装
市面上最流行的工作流任务调度器大致有以下这两种:
- ooize
- azkaban
下面就这两种,进行详细的阐述
ooize 偏重量级,功能全面,但是配置却更加复杂
azkaban 偏轻量级,功能稍微缺少一些, 但是配置简单
功能方面:
- 均可调度mapreduce,pig,java,脚本工作流任务
- 均可定时执行工作流任务
工作流传参
Azkaban支持直接传参,例如inputOozie支持参数和EL表达式
定时执行
- Azkaban的定时执行任务是基于时间的
- Oozie的定时执行任务基于时间和输入数据
资源控制
- Azkaban有较严格的权限控制,如用户对工作流进行读/写/执行等操作
- Oozie暂无严格的权限控制
1.4 Azkaban 和 Hadoop的关系
Azkaban 几乎是Hadoop的御用工作流任务调度器
1.5 Azkaban 底层原理简述
架构图:
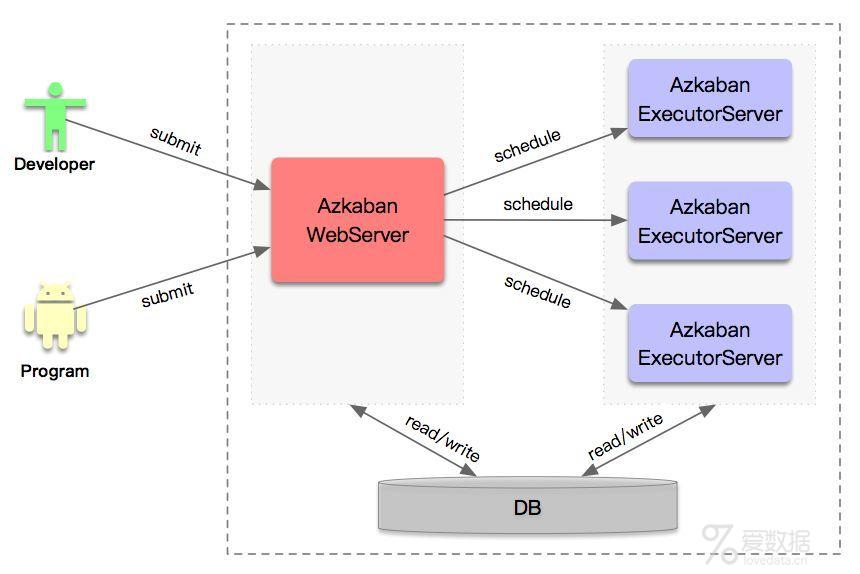
图片来源于网络。
从上图可见,Azkaban集群部署模式,主要有3个核心的组件:
Azkaban WebServer
Azkaban WebServer,是整个调度集群的核心,负责所有作业的管理和调度。
Azkaban ExecutorServer
Azkaban ExecutorServer,整个调度集群中实际运行作业的节点
DB
DB,是集群中所有节点运行共用的数据存储,包含作业信息、各种调度元数据等。
更加详细的了解,可以去谷哥或者度娘,本篇不做太深入的阐述
2 Azkaban任务调度平台搭建
注意:系统环境为linux系统
1. 下载安装
- 下载地址:http://azkaban.github.io/downloads.html
Azkaban Web 服务器:azkaban-web-server-2.5.1.tar.gz
Azkaban Excutor 执行服务器:azkaban-executor-server-2.5.1.tar.gz
Azkaban 脚本文件:azkaban-sql-script-2.5.1.tar.gz
2.安装说明
将以上三个压缩包下载下来,上传到需要安装azkaban的服务器上
3.安装步骤
1. 创建目录
切换到常用的/usr/local 目录下
[root@hadoop-demo ~]$ cd /usr/local
[root@hadoop-demo local]$ mkdir azkaban
2. 上传下载好的压缩包,解压到指定目录
解压命令:tar -zxvf 压缩包 -C 解压到那个目录
[root@hadoop-demo ~]$ tar -zxvf azkaban-web-server-2.5.1.tar.gz -C /usr/local/azkaban/
[root@hadoop-demo ~]$ tar -zxvf azkaban-executor-server-2.5.1.tar.gz -C /usr/local/azkaban/
3.解压脚本
解压azkaban的sql脚本
[root@hadoop-demo ~]$ tar -zxvf azkaban-sql-script-2.5.1.tar.gz
[root@hadoop-demo ~]$ cd azkaban-2.5.1/
4. 将create-all-sql-2.5.1.sql导入到MySQL数据库中
- 创建一个名为azkaban的数据库
- 选择表 --> 运行SQL文件 --> 选择sql
- 导入后,刷新表就可以看到
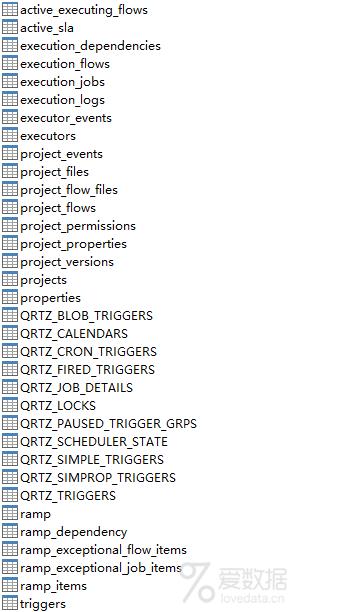
5. 创建SSL配置
- 执行命令
keytool -keystore keystore -alias jetty -genkey -keyalg RSA
会在当前目录生成一个keystore证书文件,需要填写一些信息,比如你的姓名,工作单位等。按照提示填写即可。
直接一路回车也是可以的,直接回车就是默认
[root@hadoop-demo azkaban]$ keytool -keystore keystore -alias jetty -genkey -keyalg RSA
输入密钥库口令:
再次输入新口令:
您的名字与姓氏是什么?
[Unknown]:
您的组织单位名称是什么?
[Unknown]:
您的组织名称是什么?
[Unknown]:
您所在的城市或区域名称是什么?
[Unknown]:
您所在的省/市/自治区名称是什么?
[Unknown]:
该单位的双字母国家/地区代码是什么?
[Unknown]: CN
CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=CN是否正确?
[否]: 是
输入 <jetty> 的密钥口令
(如果和密钥库口令相同, 按回车):
[root@hadoop-demo azkaban]$
- 然后把 keystore 考贝到 azkaban web服务器bin目录中使用mv命令或者copy
6.修改时区
[root@hadoop-demo azkaban]$ sudo cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
7.修改azkaban web 服务器配置
进入 azkaban web 服务器安装目录 conf 目录
[root@hadoop-demo ~]$ cd /usr/local/azkaban/azkaban-web-2.5.1/conf/
修改 azkaban.properties 文件
[root@hadoop-demo conf]$ vim azkaban.properties
配置文件详解:
#Azkaban Personalization Settings
azkaban.name=MyTestAzkaban #服务器 UI 名称
azkaban.label=My Local Azkaban #描述标签
azkaban.color=#FF3601 #‘Web UI的 颜色
azkaban.default.servlet.path=/index
web.resource.dir=/usr/local/azkaban/azkaban-web-2.5.1/web/ #默认根 web 目录
default.timezone.id=Asia/Shanghai #默认时区,已修改为亚洲/上海
... 篇幅有限,此处省略其他
修改 azkaban-users.xml配置文件
用户配置 进入 azkaban web 服务器 conf 目录,修改 azkaban-users.xml vim azkaban-users.xml 管理管理员用户
<azkaban-users>
<user username="azkaban" password="azkaban" roles="admin" groups="azkaban" />
<role name="admin" permissions="ADMIN" />
<role name="metrics" permissions="METRICS"/>
</azkaban-users>
修改azkaban executor服务器配置
进入 azkaban executor 服务器安装目录 conf 目录
[root@hadoop-demo ~]$ cd /usr/local/azkaban
cd azkaban-executor-2.5.1/conf/
修改azkaban.properties文件
[root@hadoop-demo conf]$ vim azkaban.properties
#Azkaban
default.timezone.id=Asia/Shanghai #时区
# Azkaban JobTypes 插件配置,插件所在位置
azkaban.jobtype.plugin.dir=/home/hadoop/apps/azkaban-2.5.0/azkaban-executor-2.5.0/plugins/jobtypes
#Loader for projects
executor.global.properties=/home/hadoop/apps/azkaban-2.5.0/azkaban-executor-2.5.0/conf/global.properties
azkaban.project.dir=projects
#数据库设置
database.type=mysql #数据库类型(目前只支持 mysql)
mysql.port=3306 #数据库端口号
mysql.host=hadoop03 #数据库 IP 地址
mysql.database=azkaban #数据库实例名
mysql.user=root #数据库用户名
mysql.password=root #数据库密码
mysql.numconnections=100 #最大连接数
# 执行服务器配置
executor.maxThreads=50 #最大线程数
executor.port=12321 #端口号(如修改,请与 web 服务中一致)
executor.flow.threads=30 #线程数
配置环境变量
[root@hadoopdemo ~]$ vi .bashrc
#Azkban
export AZKABAN_WEB_HOME=/usr/local/azkaban/azkaban-web-2.5.1
export AZKABAN_EXE_HOME=/usr/local/azkaban/azkaban-executor-2.5.0
export PATH=$PATH:$AZKABAN_WEB_HOME/bin:$AZKABAN_EXE_HOME/bin
// 保存之后使其立即生效
[root@hadoop3 ~]$ source .bashrc
运行启动
启动web服务器
[root@hadoop3-demo ~]$ azkaban-web-start.sh
后台启动方式
nohup azkaban-web-start.sh &
启动executor服务器
[root@hadoop-demo ~]$ azkaban-executor-start.sh
后台启动方式
nohup azkaban-executor-start.sh &
验证
打开谷歌或是火狐浏览器输入https://服务器ip:8443
可看到以下界面:
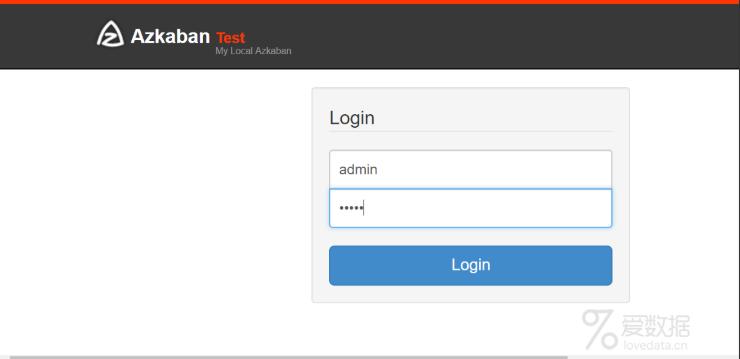
输入在配置文件azkaban-users.xml,中配置的用户名密码azkaban/azkaban,点击登录

3.Azkaban Web可视化平台介绍以及使用
首页有四个菜单
- projects:项目/工程,管理工程,已经工程下的工作流,作业等。左侧是分类,个人/分组/全部
- scheduling:显示定时任务
- executing:显示当前运行的任务
- history:显示历史运行任务
创建工程:
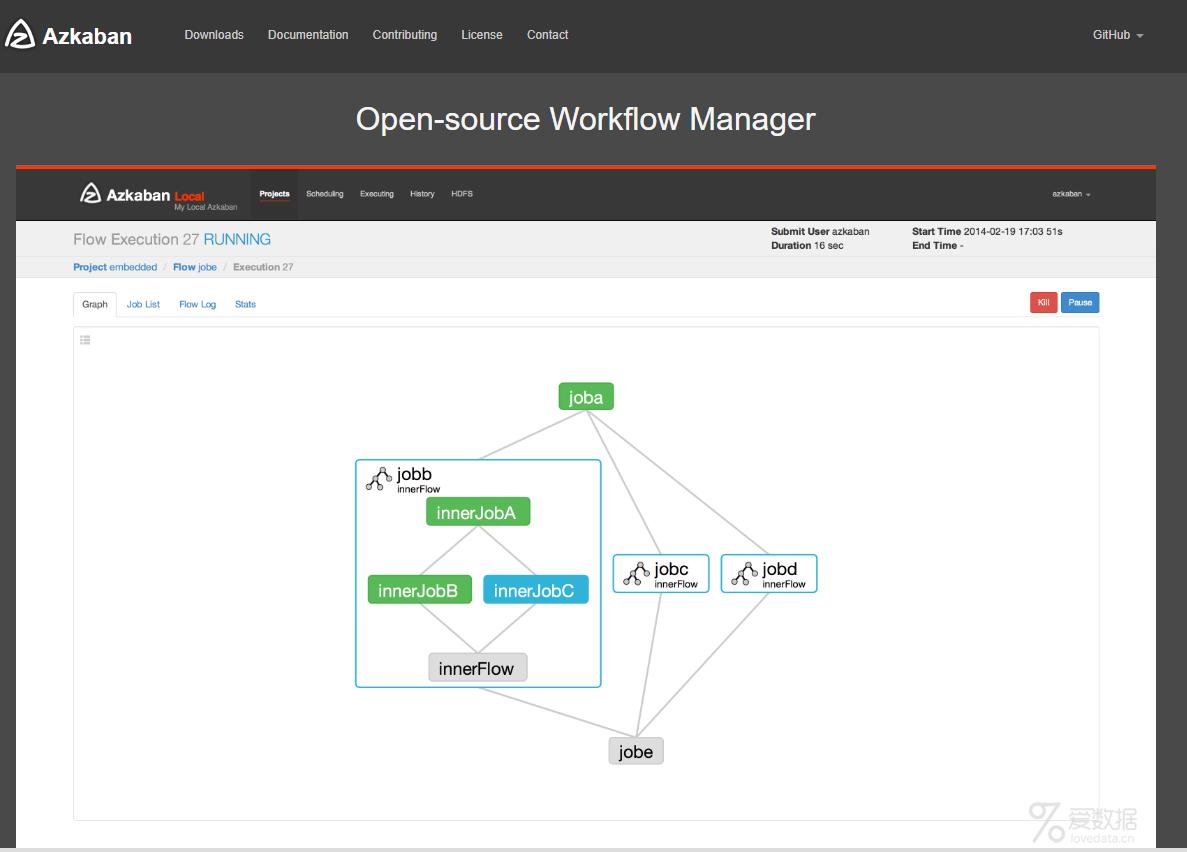
一个工程可以包含多个flows,一个flows可以包含多个job;job代表一个作业,作业可以是shell命令,shell脚本等。一个作业可以依赖其他作业,这样的作业组成的流图叫flow。
1、Command 类型单一 job 示例
(1)首先创建一个工程,填写名称和描述
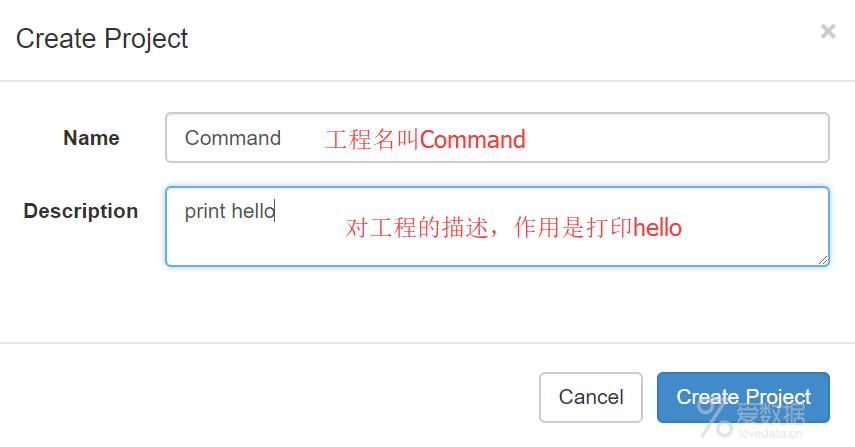
(2)点击创建之后
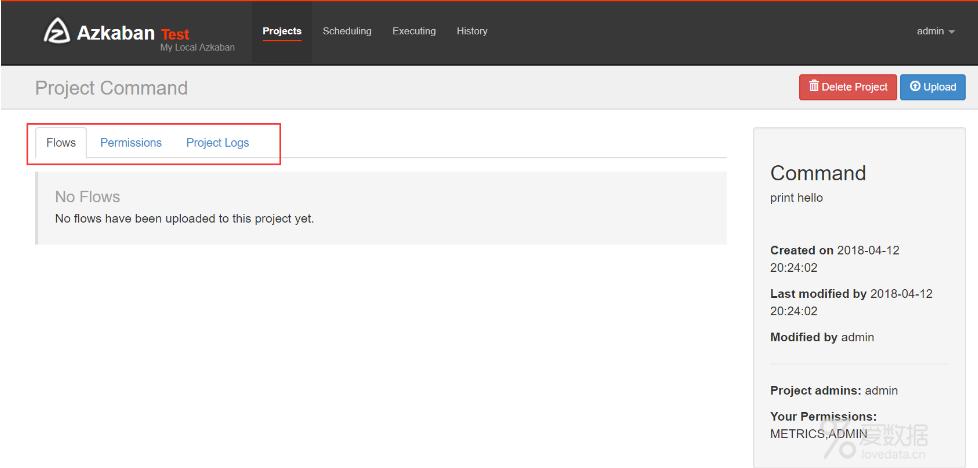
- Flows:工作流程,由多个job组成
- Permissions:权限
- Project Logs:项目日志
(3)job的创建
创建job很简单,只要创建一个以.job结尾的文本文件就行了,例如我们创建一个工作,用来打印hello,名字叫做command.job
可以先创建command.txt,写入一下内容后将后缀改为.job
# 第一个job
type=command
command=echo "hello"
这样job就创建好了,type等于command的意思是告诉azkaban用unix原生命令去运行。一个工程不可能只有一个job,我们现在创建多个依赖job,这也是采用azkaban的首要目的。
(4)将 job 资源文件打成压缩zip包
千万注意:只能是zip格式
(5)通过 azkaban web 管理平台创建 project 并上传压缩包
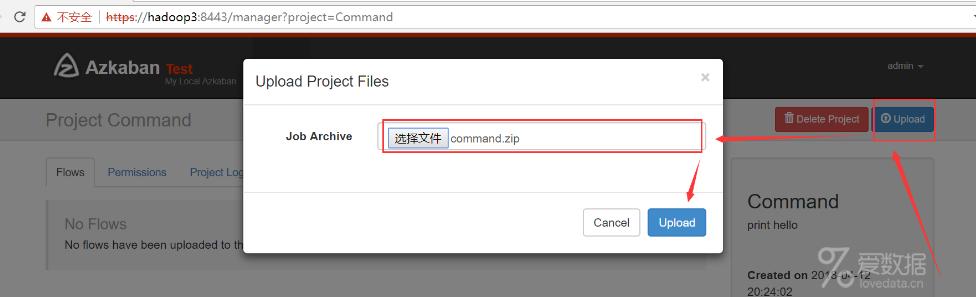
查看工程
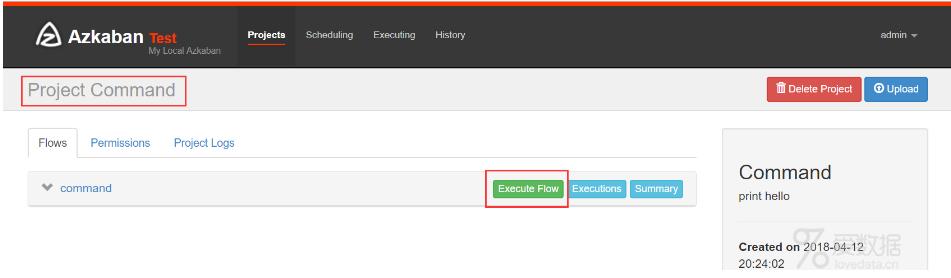
执行flow,点击Execute,Schedule是使用cron表达式定时执行
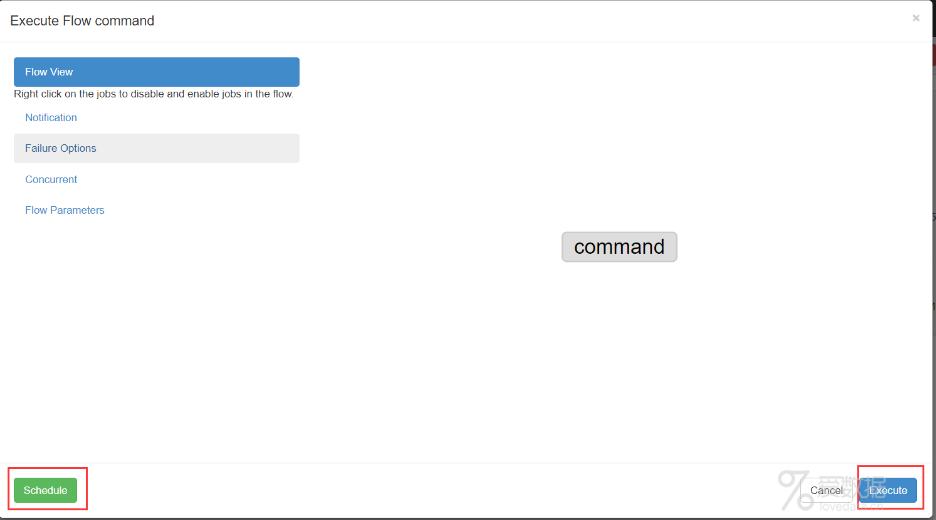
执行结果,点击details查看日志
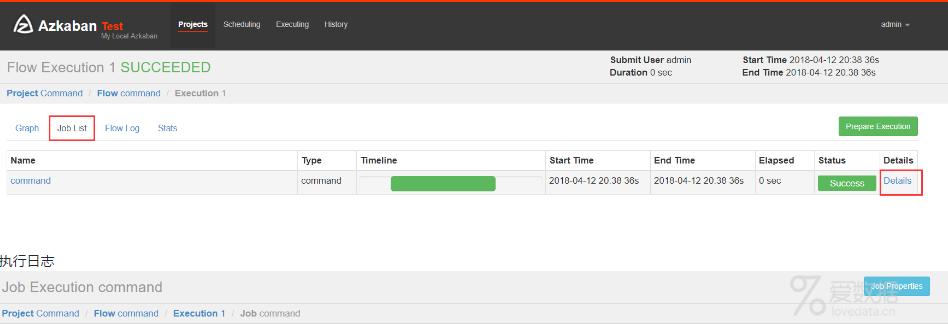
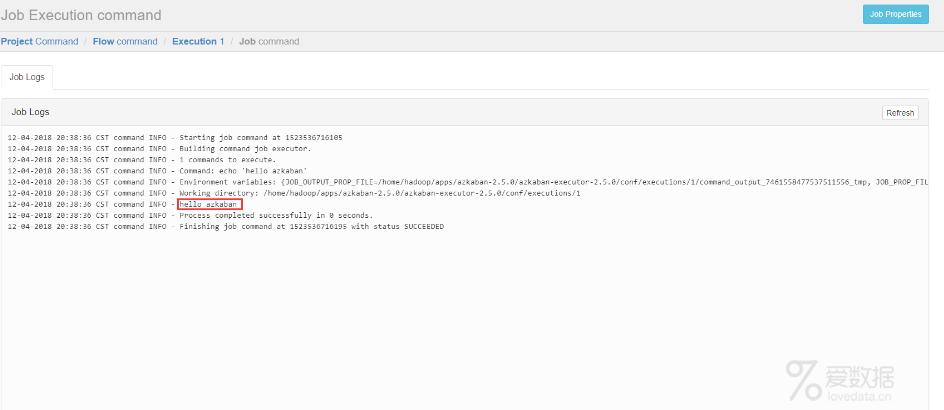
执行日志
2、Command 类型多 job 工作流 flow
(1)创建项目
我们说过多个jobs和它们的依赖组成flow。怎么创建依赖,只要指定dependencies参数就行了。定义3个job:
1、a.job
2、b.job
3、c.job
依赖关系:3依赖1和2
a.job
type=command
command=echo "a"
b.job
type=command
command=echo "b"
c.job
type=command
command=echo "c"
#多个依赖用逗号隔开
dependencies=a,b
(2)上传
说明
- Flow view:流程视图。可以禁用,启用某些job
- Notification:定义任务成功或者失败是否发送邮件
- Failure Options:定义一个job失败,剩下的job怎么执行
- Concurrent:并行任务执行设置
- Flow Parametters:参数设置。可指定执行器执行
(3)执行一次
设置参数,点击execute。绿色代表成功,蓝色是运行,红色是失败。可以查看job运行时间,依赖和日志,点击details可以查看各个job运行情况。
(4)执行定时任务
选择日期生成cron表达式,根据cron表达式进行定时执行
4 Azkaban API 功能预览
官方api地址:https://azkaban.github.io/azkaban/docs/latest/#ajax-api
文档是英文文档, 建议大家不要谷歌翻译, 谷歌翻译后更加不通顺,有阅读障碍
功能预览:
- Authenticate 认证登录
- Create a Project 创建项目
- Delete a Project 删除项目
- Upload a Project Zip 上传zip包
- Fetch Flows of a Project 获取一个项目中所有流的id
- Fetch Jobs of a Flow 获取一个流下面的所有作业
- Fetch Executions of a Flow 获取一个流的执行情况
- Fetch Running Executions of a Flow 获取一个正在执行的流的信息
- Execute a Flow 执行一个流
- Cancel a Flow Execution 关闭一个正在执行的流
- Schedule a period-based Flow (Deprecated) 定时执行一个流
- Flexible scheduling using Cron 使用cron表达式定时执行
- Fetch a Schedule 获取调度
- Unschedule a Flow 取消调度
- Set a SLA 设置SLA
- Fetch a SLA 获取一个SLA
- Pause a Flow Execution 暂停一个流
- Resume a Flow Execution 重新执行一个流
- Fetch a Flow Execution 获取流的详细执行情况
- Fetch Execution Job Logs 获取Job日志
- Fetch Flow Execution Updates 它通过lastUpdateTime过滤,后者只返回事后更新的作业信息。
4.1 对接Azkaban,进行二次开发,使其嵌入到系统中
这些是从生产环境中封装好的, 大家可以直接运用到实际工作中。
End.
挖数网专栏作者:尘心Jason
作者介绍:5年互联网大数据开发经验,丰富的项目开发经历
本文为中国统计网原创文章,未经允许禁止转载,需要转载请微信联系授权(微信号:lovedata0420)
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


2020-07-05 18:19 1F
写的很不错 不过介绍不够深入二次开发也没介绍
2020-07-05 19:23 B1
@ 111 欢迎投稿啊