
一.推荐系统结构
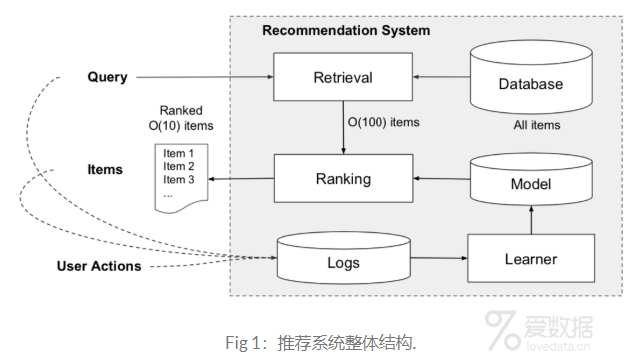
图一是Google app推荐系统的整体结构,当用户在app store上进行浏览的时候,就会产生相应的行为,包括用户、item、behavior等信息,这些信息都会逐一地写入log中。与此同时,这些用户行为也会伴随着queries和impression的产生。针对这些queries,首先app会针对用户的行为进行检索(Retrieval)。检索的结果是将相关的item list放入候选池(candidate pool),这一步通常是不同的机器学习模型+人为规则产生。接下来,优于候选池的结果是要大于我们推荐的item数量的,因此需要一个ranking系统对这些item进行打分。通常分数都是以概率的形式表示,即p(y|x),其中x表示用户的特征,通常有用户特征、item特征、上下文特征等。y表示用户做出的某种动作,如购买或者下载等行为,p表示产生这种行为的概率。本文介绍的模型主要应用于第二阶段:ranking。
二.Wide & Deep
2016年,Google针对Google Play的业务场景,提出了Wide & Deep模型。Paper开篇表示:广义线性模型结合非线性变换广泛的应用在大规模的输入数据稀疏的分类和回归任务中,特征交叉构建新特征的方法的确非常有效,但是却需要大量的特征工程。另外,基于DNN的方法虽然可以生成更多无法预见的高维特征,但是这种方法预测结果过于泛化,以至于推荐出来的物品相关性太弱。所以,Wide & Deep也就相应的诞生了。实验结果也表明,Wide & Deep方法要显著的优于wide-only和deep-only方法。下面来看看Wide & Deep内部细节。
推荐系统与搜索排序面临的一大共同挑战就是:如何让模型的结果具有更好的memorization 和 generalization。也就是说,模型需要对用户的历史行为有记忆性,同时模型也要具有更好的泛化能力。记忆性可以通过主题信息或者与已有item更相关的信息进行反馈,泛化能力则是让推荐结果更具多样性。那么,有没有一种方法能够同时让模型具备这两个优点呢?当然,Wide & Deep就是很好的模型。结构上,Wide & Deep其实是LR和DNN的结合,其LR部分仍然需要人工特征工程以体现特征的组合,Deep部分属于DNN。
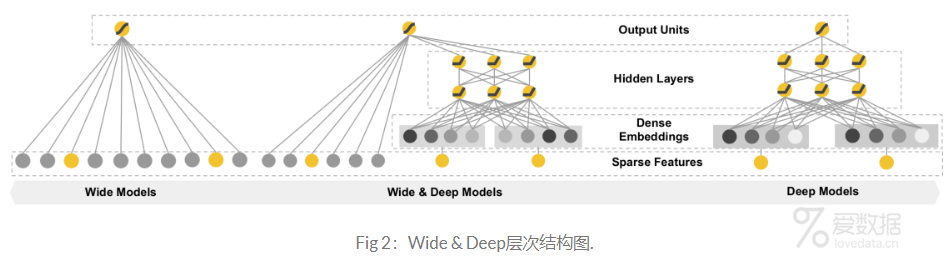

Deep & Wide确实是一大进步,但是对于wide部分,需要大量的人工进行特征工程,对于"想偷懒"的程序员来说,特征工程真的太麻烦了,为此DeepFM就随之诞生了。
三.DeepFM
DeepFM源自华为,设计上主要源自2016年Wide & Deep的启发。关于DeepFM的paper,2017年和2018年都发表了一篇,不过本文主要介绍DeepFM的结构,其他的暂且不论吧。其结构如Fig 3所示:
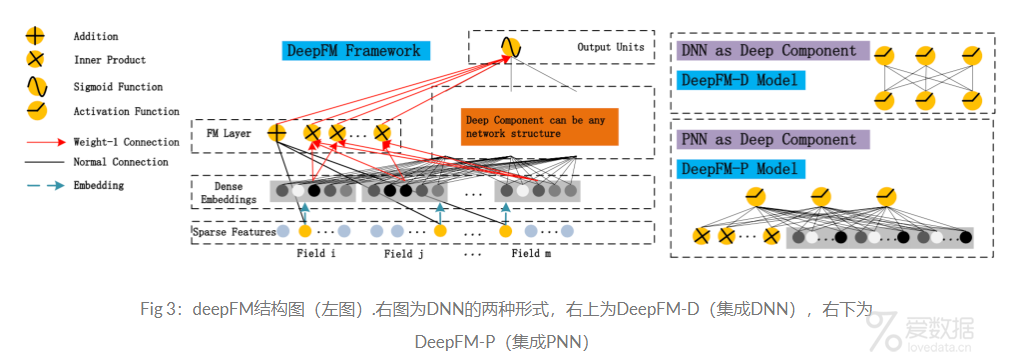

- DeepFM可以end-to-end训练,不需要任何的特征工程。FM作为低阶特征,DNN作为高阶特征。
- 训练更加高效,Wide和Deep两者共享同一个输入和embedding向量。与Wide & Deep相比,由于Wide & Deep需要人工的进行特征工程,因此增加了模型的复杂度。
- CTR预测结果更准确。
在预测结果上,表达式如下:

1.FM部分
deepFM的wide部分是FM,即factorization machine,Rendle于2010年提出,用于构建推荐场景的相互作用特征,具体细节可以参考笔者之前的一片文章FM算法原理分析与实践。在deepFM中,FM主要用于学习低阶特征,其目标表达式如下:
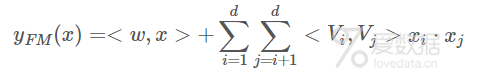
2.Deep部分
deepFM中的deep部分是一个前馈神经网络,主要用于学习高阶特征。但是与2016年原生的Wide & Deep相比,其输入大有不同,原生的Wide & Deep中DNN的输入可能极度稀疏,同时连续特征和类别特征夹杂在一起,并以field进行分组,在deepFM里,DNN的输入时连续的数值,并且与Wide部分共享输入。
其输出表达式如下:

四.模型对比
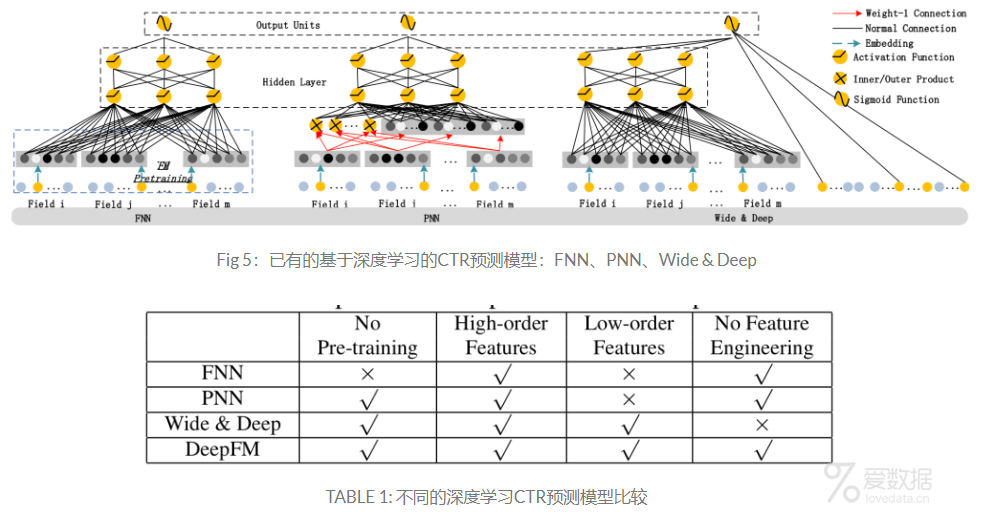
本文的核心在于DeepFM,那么DeepFM与其他模型相比,性能究竟如何呢?如Fig 5所示,DeepFM与Wide & Deep的区别在上面已经概括的差不多了,那么与FNN和PNN相比又有什么不同呢?首先简单介绍下什么是FNN和PNN。FNN是一个使用FM进行初始化的前馈神经网络,它采用FM进行pre-training,因此其精度和性能必然收到了FM阶段参数的影响,除此之外,FNN只能学习高阶特征,无法学习低阶特征。对于PNN,全称为Product-based Neural Network,为了获取高阶特征,PNN在embedding层和hidden layer之间增加了product layer。根据不同的product type,将其又划分为IPNN,OPNN,PNN*。与FNN一样,PNN忽略了低阶特征的信息,不过PNN不需要预排序。整体的对比结果如TABLE 1所示。
五.Conclusion
本文主要介绍了Wide & Deep 和DeepFM,并对两者的结构进行了分析。从大的方向来看,两者都集成了低阶特征,相比之下,DeepFM少了人工构建特征的步骤,则显得更加地灵活。如果读者在细节上有疑问,可以参考原始paper,参考文献中均已给出。后续的文章中,将逐步增加相应模型的实践案例,敬请期待。
六.References
- DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
- DeepFM: An End-to-End Wide & Deep Learning Framework for CTR Prediction
- Wide & Deep Learning for Recommender Systems
- CTR预估经典模型:GBDT+LR
- FM算法原理分析与实践
- https://www.cnblogs.com/arachis/p/FTRL.html
End.
作者:拾毅者
来源:『刘帝伟』维护的个人技术博客
本文均已和作者授权,如转载请与作者联系。
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论