
一.数据集处理
原始的电影评论数据共4428475条,样例数据如Fig 1所示,数据里面还夹着一些没有评分的数据,将这些RATING为NaN的过滤掉之后,剩下来的数据有4166704条。

除了数据评分取值的问题,CONTENT里的文本有的还是繁体,所以在进行情感分析之前,我们还需要对文本的格式统一起来,代码核心部分如下(仅供参考):
- fromlangconvimport*
- deftraditional2simplified(text):
- text = Converter("zh-hans").convert(text)
- returntext
- dataset["CONTENT"] = dataset.CONTENT.apply(lambdax: traditional2simplified(x))
对400多万的文本数据进行分类,乍一看也还算OK,不过在单机上还是有些吃力,所以我们需要对数据进行进一步的去脏以达到缩放的效果,而这一阶段需要做的工作量还是比较多的。
1.去除干扰评论数据
影评数据的评分RATING评分值为1-5星,这些评分跟评论的相关性还是比较大的。虽然如此,评论里面还是存在很多的干扰数据,笔者对数据集的进行了简单的比较,发现相同的评论,其RATING值居然不一样,这类数据还占了15%以上,真是恐怖如斯!!考虑到数据集的数据量本来就比较大,所以索性对这部分数据直接去掉了,最后剩下3795251条影评数据。
2.去除过短或过长的数据
在这份电影评论数据集里,文本长度从1-3000+不等,长度过于波动,不太符合短评数据的长度规范。为此,笔者将文本长度限制在了[5,140],上下都取闭区间(豆瓣的短评数据集长度为140),最后得到的数据集3582251条。
3.情感类别定义
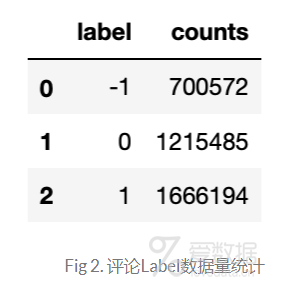
先前提到豆瓣电影评论携带的评分在1-5星,仔细看了评论内容你会发现,1-2星的评论以及4-5星的评论确实很难区分,好在豆瓣给出了1-5星每个星值的意义(1-很差,2-较差,3-还行,4-推荐,5-力荐),所以最后将评论划分为三个:1-2星为消极negative,3星为正常normal,4-5星为正向positive,如此以来,就将评论划分成三个类别了,各个类别的数据量如Fig 2所示。接下来就可以对这个label取值为3类的文本数据进行模型训练与预测了。
二.数据预处理
对于中文文本分词,这里采用的jieba,同时文本数据进行了去停留词处理,代码如下:
- importjieba
- fromsklearn.feature_extraction.textimportCountVectorizer
- defget_stopwords():
- stopwords = [line.strip()forlineinopen("data/stopwords/stopword_normal.txt",encoding="UTF-8").readlines()]
- returnstopwords
- importre
- stopwords = get_stopwords()
- deftext_process(text):
- """""
- 按照下面方式处理字符串
- 1. 去除标点符号
- 2. 去掉无用词
- 3. 返回剩下的词的list
- """
- text = re.sub("[s+.!/_,$%^*(+""]+|[+——!,。?、~@#¥%……&*()]", "",text)
- ltext = jieba.lcut(text)
- res_text = []
- forwordinltext:
- ifwordnotinstopwords:
- res_text.append(word)
- returnres_text
- X = dataset.CONTENT
- y = dataset.label
- bow_transformer = CountVectorizer(analyzer=text_process).fit(X)
- X = bow_transformer.transform(X)
通过上面的处理之后,我们可以得到X和y,接下来,可以用这部分数据进行模型训练了。
三.模型训练与评估
采用sklearn将数据集划分为训练集和测试集,即使比例为9:1,测试数据也有358226t条,一个demo足够了。
- fromsklearn.model_selectionimporttrain_test_split
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=99)
由于是多分类,所以就直接采用了MultinomialNB作为baseline,核心代码如下:
- rom sklearn.naive_bayesimportMultinomialNB
- nb = MultinomialNB()
- nb.fit(X_train, y_train)
- preds = nb.predict(X_test)
四.模型评估
得到了预测的preds值之后,直接调用sklearn的metrics里面的方法,就可以轻松地将相关的模型评估指标值计算,代码如下:
- rom sklearn.metricsimportconfusion_matrix, classification_report
- #根据预测值和真实值计算相关指标
- print(classification_report(y_test, preds))
输出结果:
- precision recall f1-score support
- -10.560.560.5670406
- 00.500.440.47121276
- 10.660.720.69166544
- accuracy0.59358226
- macro avg0.570.570.57358226
- weighted avg0.590.590.59358226
可以看出,三个label的平均precision和recall都接近0.6,整体上还是OK的,后续再进一步优化吧,预测方法封装如下:
- defsentiment_pred(text):
- text_transformed = bow_transformer.transform([text])
- score = nb.predict(text_transformed)[0]
- returnscore
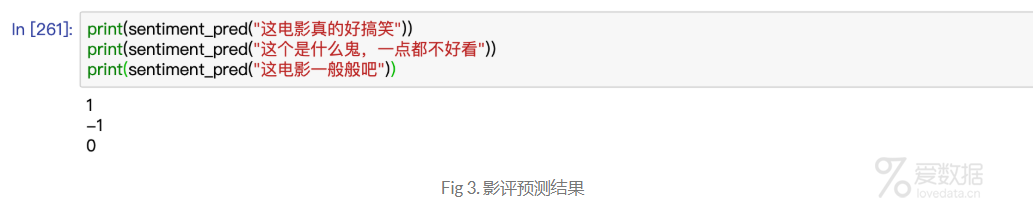
预测结果如下Fig 3,测试数据样例不要太当真,仅仅作为参考:
五.结束语
各位看客如有需要数据集的可见参考文献[1],其他的就不多说了,情感分类内部细节还有很多待处理,本文仅仅是一个简单的baseline,如果采用深度学习如LSTM进行分类的话,单机上内存可能会不够,所以还需要对数据集进行进一步的处理。OK,就将这个当做是下一个任务项吧!
六.References
End.
作者:拾毅者
来源:『刘帝伟』维护的个人技术博客
本文均已和作者授权,如转载请与作者联系。
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论