
送分题
free 或者 top-
total 总内存
-
used 已用内存
-
free 空闲内存
-
buff/cache 已使用的缓存
-
avaiable 可用内存

sync; echo 3 > /proc/sys/vm/drop_caches就可以清理buff/cache了,你说说我在线上执行这条命令做好不好?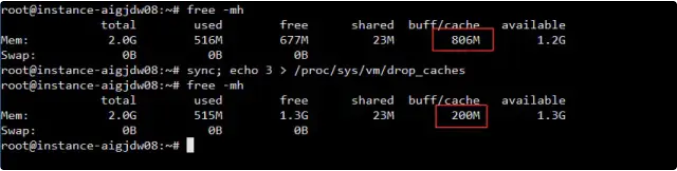
再谈SQL Join
回顾
join可以根据某些条件把指定的表给结合起来并将数据返回给客户端join的方式有:5 种 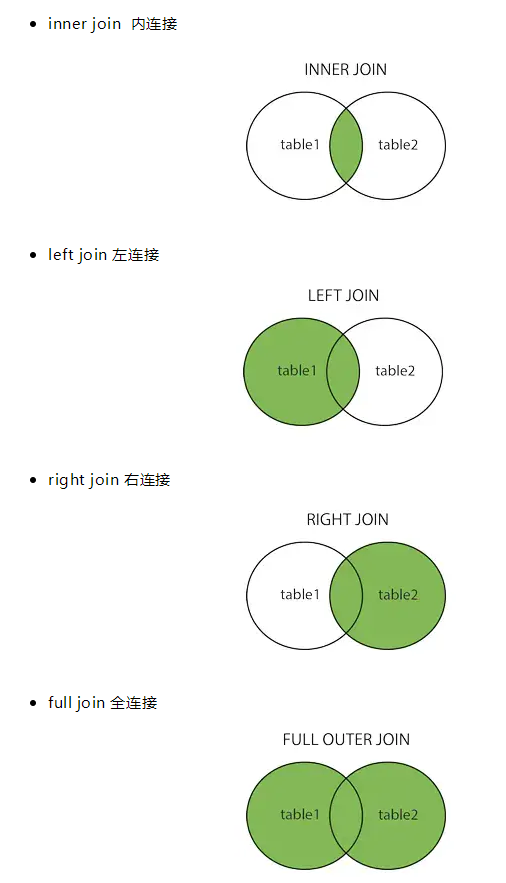
join语句,如何优化提升性能?-
数据规模较小 全部干进内存就完事了嗷 -
数据规模较大
可以通过增加索引来优化 join语句的执行速度 可以通过冗余信息来减少join的次数 尽量减少表连接的次数,一个SQL语句表连接的次数不要超过5次
join语句是相对比较耗费性能,对吗?缓冲区
内存块中, 以MySQL的InnoDB引擎为例,使用以下语句我们必然可以查到相关的内存区域show variables like "%buffer%"
join_buffer_size的大小将会影响我们join语句的执行性能一个大前提
硬盘上,并且以文件的形式进行存储。-
InnoDB以 页(page)为基本的IO单位,每个页的大小为16KB -
InnoDB会为每个表创建用于存储数据的 .ibd文件
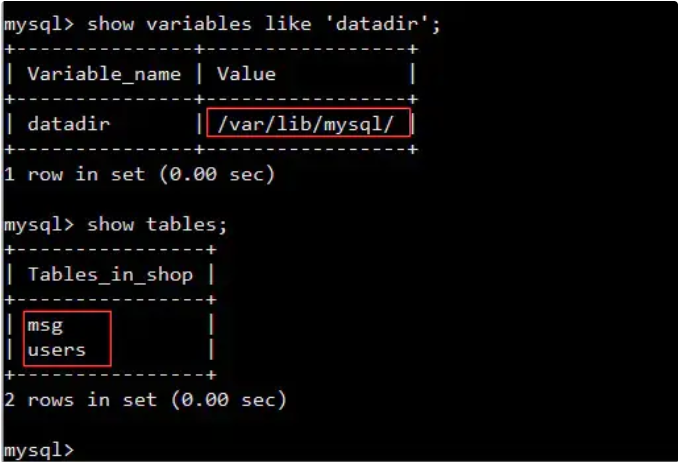
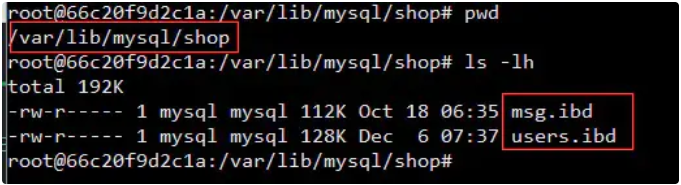
hbase、kafkaLinux有对此做出优化吗?提示,你可以再执行一次free命令看一下
-
buff/cache里面存的是什么,? -
为什么 buff/cache占了那么多内存,可用内存即availlable还有1.1G? -
为什么你可以通过两条命令来清理 buff/cache占用的内存,而想要释放used只能通过结束进程来实现?

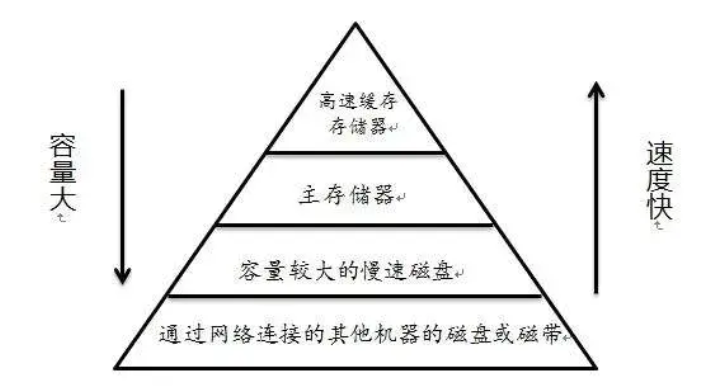
buff/cache所占用的内存,说明它就不重要, 清除它不会对系统的运行造成影响存储器层次结构的本质是,每一层存储设备都是较低一层设备的缓存
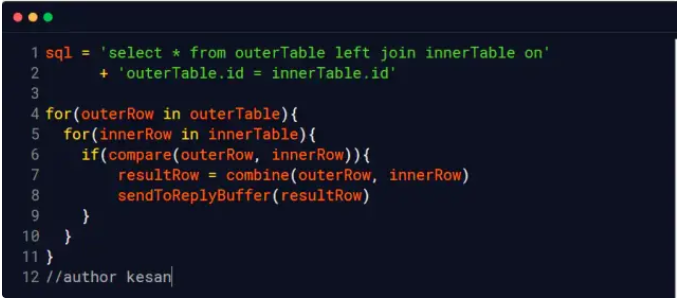
Join算法
join_buffer 你认为join_buffer里面存储的是什么?join_bufferNested Loop Join
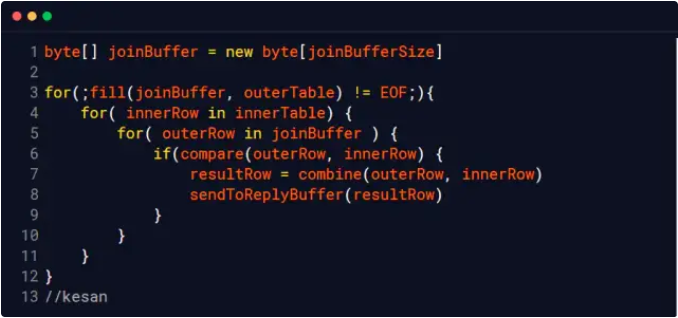
10000000次(假设这两个表的文件没有被操作系统给缓存到内存, 我们称之为冷数据表)Block nested loop
Block 块,也就是说每次都会取一块数据到内存以减少I/O的开销t_a 和t_b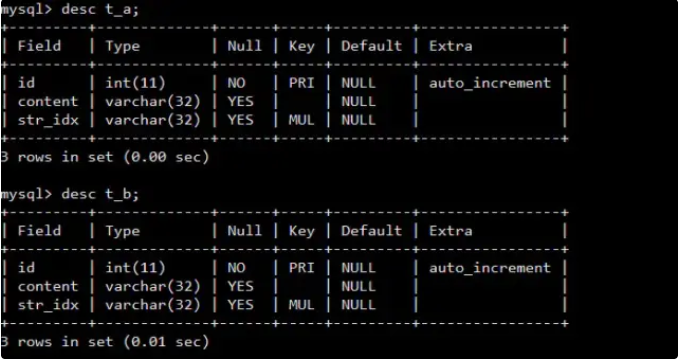
Block nested loop 算法
End.
作者:柯三
本文为转载分享,如果涉及作品、版权和其他问题,请联系我们第一时间删除(微信号:lovedata0520)
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论