
前面用两篇文章介绍了时间序列 (怎样理解时间序列一 ,怎样理解时间序列二),如果有看过的,应该对时间序列有一些了解了。上一篇介绍了ARIMA算法,它有很多参数,它有难懂的公式,它可以拟合相对复杂的数据,这些可以说明这个算法很好吗?当年王莽集结了40多万大军,军队中海油有虎、豹等猛兽,真的是吓死个人,但结果却被刘秀带着3000多个人打的哭爹喊娘,直接把新朝打崩了。所以,ARIMA也好Holt-Winters也好,算法怎样的复杂,逻辑多么的缜密,都不是重点,既然我是用你来预测的,你只要能给我一个准确的结果就足够了。那么,如何才能知道一个算法是否可以给我们一个值得信赖的结果呢?要等结果出来再验证吗,黄花菜已凉,再调整你还有何用?不慌,接下来我就介绍这个。
先不要急,首先,我们还要有这样一个认识,那就是有些数据我们可能永远无法预测到准确的结果。有了这个认识作为前提,可以避免让你走火入魔,因为有的数据它真的就没法预测啊。好了,我们先解决这个问题,什么样的数据不能预测呢?
我对预测有这样的一个理解,之所以时间序列可以预测某些数据序列,是因为我们可以将数据序列分成两部分:数据序列=函数+噪声。我们预测一个序列,就是把序列的函数部分找出来,各种时间序列算法,都是在拟合、寻找这个函数,算法拟合的函数和序列本身的函数越接近,这个算法预测的效果就会越好。有些序列是纯函数,比如xn=xn-1+2,这样的序列很容易找出它的函数,也可以对xn有精准的预测;有些序列是纯噪声,最典型如白光序列,噪声它之所以称之为噪声,就是因为噪声是没有任何规律的、不可预测的,因此这样的序列我们只能放弃。生活中大部分的序列既不是纯函数也不是纯噪声,而是两者都有。当序列函数部分占比更大时,意味着它被预测的价值更大;当序列噪声部分占比比较大,意味着它不可能预测的准确,偶尔的准确也只是运气,毕竟谁还没踩过几次狗屎呢。
现在我们知道一个序列是否值得预测了。总结一下,在预测之前对序列进行白噪声检验,若检测后被认定为白噪声,意味着很难有算法可以准确的预测这个序列了,当然你也选择不放弃,万一白噪声监测错了呢。若序列通过了白噪声的检验,意味着序列可以被预测,我们可以大胆的调试算法了。说了一大堆,回到我们的中心,怎样判断我们调试的算法的预测能力呢?
有一个方法可以判断所有的算法。再次拿出前面的公式:数据序列=函数+噪声。前面讲到,算法是在拟合序列的函数部分,如果算法拟合的函数和序列自身的函数非常相似,那么预测效果一定不差,但要预知这一点不容易,我们需要换个角度,数据序列-函数=噪声,如果数据序列-算法也等于噪声,那意味着算法拟合的函数和序列本身的函数相差不远了。所以我们监测拟合后的残差,如果残差为白噪声,意味着我们已经把序列的函数部分提取的差不多了,剩下的噪声已没有价值,这个模型也就通过了检验。
凡事总会有点意外,对于ARIMA算法,仅仅靠残差的白噪声检验还不够,算法的应用中有一个概念叫做过拟合,指的就是在拟合的过程中表现非常好,但上战场用来预测的时候就颓了。好比一学生平时做题贼溜,高考的结果却一塌糊涂,这还不如平时做题也很烂,也能让家人在高考前有个心理准备。对于ARIMA,为什么会有过拟合呢?前面介绍过ARIMA算法的公式了,这里再贴一下:
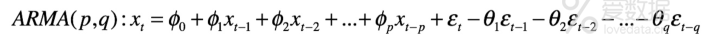
它有很多参数,  和
和  的个数分别是p和q个,都是未知的,如果p和q很大(也就是参数特别多),那么拟合效果一般会很好,但是函数过于复杂了,它可能是根据历史的序列强行构造的,而不能体现一般规律,就如这个学生平时都是背大量考试题来做题的,而没有掌握问题的通用方法一样。一般来说好的模型不会有太多的参数,参数多意味着稳定性差,所以ARIMA不能仅靠残差的白噪声检验,也要考虑算法参数的数量。好在ARIMA有这样两个考核指标:AIC和BIC。AIC和BIC是在算法的拟合效果基础上增加了参数数量作为惩罚项,其中BIC的惩罚项更大一些。因此在用ARIMA预测完之后,可以对比多个ARIMA的AIC或BIC的值。
的个数分别是p和q个,都是未知的,如果p和q很大(也就是参数特别多),那么拟合效果一般会很好,但是函数过于复杂了,它可能是根据历史的序列强行构造的,而不能体现一般规律,就如这个学生平时都是背大量考试题来做题的,而没有掌握问题的通用方法一样。一般来说好的模型不会有太多的参数,参数多意味着稳定性差,所以ARIMA不能仅靠残差的白噪声检验,也要考虑算法参数的数量。好在ARIMA有这样两个考核指标:AIC和BIC。AIC和BIC是在算法的拟合效果基础上增加了参数数量作为惩罚项,其中BIC的惩罚项更大一些。因此在用ARIMA预测完之后,可以对比多个ARIMA的AIC或BIC的值。
在实际应用中,调好一个模型后,要用以上两个方法来检查模型。但是,这样的检查只是类似于考试时我们现场对答案的检查,是必须的同时也是初级的。要放心的使用模型来实战,还需要让我们的模型来几次模拟考,模拟真实的预测环境,来检验模型的预测效果。
我们可以把数据分成两部分,一部分用来调试模型,另一部分用来检验模型。如果我们有4年(48个月)的数据,我们使用前3年(前36个月)的数据用来调整算法训练模型,再用模型逐步预测最后12个月的数据,最好采用滚动预测的方法,每次预测前进一个月,总共可以进行12次模拟检验,如果12次的预测效果都不错,这个模型大概率是比较靠谱的了。
如果模型经过一套检验下来表现并不好,有什么方法来改变吗?答案是:调整算法的参数(这,是一句有用的废话)。调整算法的参数当然是一个方法,当模型表现不理想时,一定是要尝试调整参数了。但是,很多情况是无论我们怎样调整参数,都不能达到预测的要求,这时还能做些什么。
分类算法中,有一个概念叫做集成学习,是由多个算法组合,多个算法共同决策并输出最终结果的,常见的算法比如随机森林和GBDT都是这样的算法。很多时候一个算法的结果不稳定,但多个算法的结果进行投票或平均后,结果就会好很多,很土,没处说理,却很好用。这样的方法也同样适用于时间序列,当一个算法输出的结果经常偏高或偏低很多时,可以寻其他的算法与之相平衡,然后将两个或多个算法进行运算后的结果作为最终结果。几个项目下来,我越来越喜欢这样的方法了。
最后,对时间序列做一个总结。我们都希望可以预测未来,可以准确点就更好了,这样的心情可以理解。因为对算法的陌生,加上对未来的未知和渴望,我们往往对算法有过大的期望,会觉得算法很复杂也很强大,它可以把我们办不到的事情做好。但是,时间序列它并没有那样的神奇,它所做的不过是把过去的规律进行总结,然后得到一个过得去的结果。如果一个数据不是很复杂,如果一个人愿意花时间对数据的历史进行思考和总结,他也一定可以对数据的未来有着不错的预测,可能不比算法差。所以,我觉得时间序列最大的价值也在于它可以不厌其烦的严谨的对待每一次预测,每一次预测都经过缜密的"思考"、"算计"、考虑了众多历史因素的,再输出结果。对于我们来说,它节省了我们的时间,也避免了我们的失误。当然,因为这样,数据量越大,算法的价值越多,因为大数据量下让一个人每次预测都考虑分析每个数据的意义,要比小数据量困难得多。但它可以得到我们自己无法预测到的,更为准确的结果吗?我觉得不能。
时间序列并不复杂,只要我们稍加学习,就可以用来对我们的数据进行预测。时间序列也并没有那样的神奇,它也不能突破一个人的预测能力。但它不怕辛苦,每次预测都经过严谨的计算,它可以节约我们的时间,减少我们的失误,整体上让我们对未来有着更精准的把握,学会应用时间序列,相信可以给我的工作带来便利和价值。
End.
作者:jiago 王佳东fr来源:知乎
本文均已和作者授权,如转载请与作者联系。
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论