
大家好,我是才哥。
今天我们介绍一款python标准库urllib.parse,这玩意主要用于解析URL,即将URL字符串分割成其组件,或者将URL组件组合成一个URL字符串。
我们在写爬虫的时候,往往会分析真实URL地址的一些规律,找出它的参数组件,然后组合成字典等格式的参数,在进行数据请求的时候代入。
记得我之前都是在开发者模式下,找到参数部分,然后拷贝到本地,手动改写为字典参数的形式来着。现在,我们可以试着用这个标准库进行自动化处理,直接复制Request URL的地址,然后解析。
1.先看一个例子
我们以网易财经沪深行情为例,在开发者模式下发现真实请求地址如下,参数蛮多的:
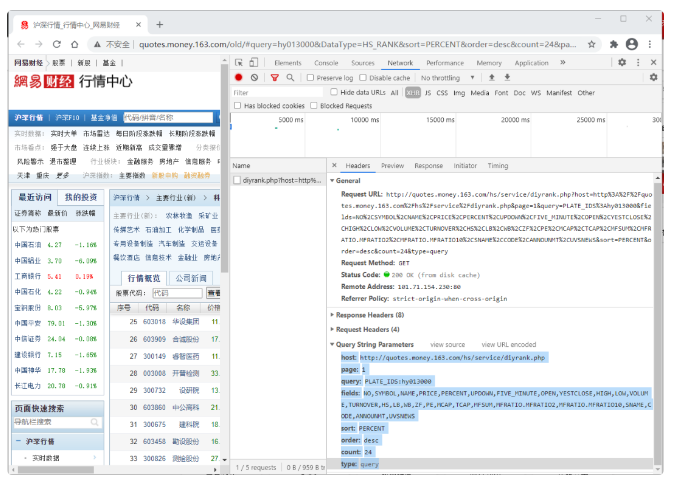
1.1. urlparse方法
这里我们先介绍urlparse方法,返回的是包含6个元素的元组。
from urllib.parse import urlparseurl = "http://quotes.money.163.com/hs/service/diyrank.php?host=http%3A%2F%2Fquotes.money.163.com%2Fhs%2Fservice%2Fdiyrank.php&page=1&query=PLATE_IDS%3Ahy013000&fields=NO%2CSYMBOL%2CNAME%2CPRICE%2CPERCENT%2CUPDOWN%2CFIVE_MINUTE%2COPEN%2CYESTCLOSE%2CHIGH%2CLOW%2CVOLUME%2CTURNOVER%2CHS%2CLB%2CWB%2CZF%2CPE%2CMCAP%2CTCAP%2CMFSUM%2CMFRATIO.MFRATIO2%2CMFRATIO.MFRATIO10%2CSNAME%2CCODE%2CANNOUNMT%2CUVSNEWS&sort=PERCENT&order=desc&count=24&type=query"o = urlparse(url)o输出结果如下:
ParseResult(scheme="http", netloc="quotes.money.163.com", path="/hs/service/diyrank.php", params="", query="host=http%3A%2F%2Fquotes.money.163.com%2Fhs%2Fservice%2Fdiyrank.php&page=1&query=PLATE_IDS%3Ahy013000&fields=NO%2CSYMBOL%2CNAME%2CPRICE%2CPERCENT%2CUPDOWN%2CFIVE_MINUTE%2COPEN%2CYESTCLOSE%2CHIGH%2CLOW%2CVOLUME%2CTURNOVER%2CHS%2CLB%2CWB%2CZF%2CPE%2CMCAP%2CTCAP%2CMFSUM%2CMFRATIO.MFRATIO2%2CMFRATIO.MFRATIO10%2CSNAME%2CCODE%2CANNOUNMT%2CUVSNEWS&sort=PERCENT&order=desc&count=24&type=query", fragment="")我们可以看到,解析出来的组件一共6种属性,分别是scheme、netloc、path、params、query和fragment。
以下是URL解析后的属性介绍:
| 属性 | 索引 | 值 | 值(如果不存在) |
|---|---|---|---|
scheme |
0 | URL协议 | scheme 参数 |
netloc |
1 | 网络位置部分 | 空字符串 |
path |
2 | 分层路径 | 空字符串 |
params |
3 | 最后路径元素的参数 | 空字符串 |
query |
4 | 查询组件 | 空字符串 |
fragment |
5 | 片段识别 | 空字符串 |
username |
用户名 | None | |
password |
密码 | None | |
hostname |
主机名(小写) | None | |
port |
端口号为整数(如果存在) | None |
这些属性都可以直接访问:
o.query # 查询组件参数,一般也就是我们发现有变化规律的地方,需要构建成字典参数一类输出为:
"host=http%3A%2F%2Fquotes.money.163.com%2Fhs%2Fservice%2Fdiyrank.php&page=1&query=PLATE_IDS%3Ahy013000&fields=NO%2CSYMBOL%2CNAME%2CPRICE%2CPERCENT%2CUPDOWN%2CFIVE_MINUTE%2COPEN%2CYESTCLOSE%2CHIGH%2CLOW%2CVOLUME%2CTURNOVER%2CHS%2CLB%2CWB%2CZF%2CPE%2CMCAP%2CTCAP%2CMFSUM%2CMFRATIO.MFRATIO2%2CMFRATIO.MFRATIO10%2CSNAME%2CCODE%2CANNOUNMT%2CUVSNEWS&sort=PERCENT&order=desc&count=24&type=query"1.2. urlsplit方法
urlsplit方法和上面的urlparse方法其实差不多,区别和英文名称类似,一个是拆分(split)、一个是解析(parse)。从返回的结果来看,是5个元素,不包含params(最后路径元素的参数)。
from urllib.parse import urlspliturlsplit(url)输出结果如下:
SplitResult(scheme="http", netloc="quotes.money.163.com", path="/hs/service/diyrank.php", query="host=http%3A%2F%2Fquotes.money.163.com%2Fhs%2Fservice%2Fdiyrank.php&page=1&query=PLATE_IDS%3Ahy013000&fields=NO%2CSYMBOL%2CNAME%2CPRICE%2CPERCENT%2CUPDOWN%2CFIVE_MINUTE%2COPEN%2CYESTCLOSE%2CHIGH%2CLOW%2CVOLUME%2CTURNOVER%2CHS%2CLB%2CWB%2CZF%2CPE%2CMCAP%2CTCAP%2CMFSUM%2CMFRATIO.MFRATIO2%2CMFRATIO.MFRATIO10%2CSNAME%2CCODE%2CANNOUNMT%2CUVSNEWS&sort=PERCENT&order=desc&count=24&type=query", fragment="")什么时候用它呢?
❝
This should generally be used instead of
urlparse()if the more recent URL syntax allowing parameters to be applied to each segment of thepath portion of the URL is wanted。
大概就是当分层路径包含多个参数的时候吧,如果用urlparse方法,则会出现分层路径path的部分参数跑去了params中。
比如:
from urllib.parse import urlsplit, urlparseurl = "http://www.xx.com/path1;params1/path2;params2?query=query"print(urlsplit(url))print(urlparse(url))输出结果对比如下:
SplitResult(scheme="http", netloc="www.xx.com", path="/path1;params1/path2;params2", query="query=query", fragment="")ParseResult(scheme="http", netloc="www.xx.com", path="/path1;params1/path2", params="params2", query="query=query", fragment="")看到这里,有盆友要问了,"对于我来说,大多数时候只需要知道查询组件query和query之前的整段而已,而且查询组件query需要给我整成字典格式最清晰啦。"
很有道理!!那我们继续看!
2. 查询参数转化为字典
关于将查询组件query转化为字典,我们可以用parse_qs方法。
大家记得o.query 为如下:
"host=http%3A%2F%2Fquotes.money.163.com%2Fhs%2Fservice%2Fdiyrank.php&page=1&query=PLATE_IDS%3Ahy013000&fields=NO%2CSYMBOL%2CNAME%2CPRICE%2CPERCENT%2CUPDOWN%2CFIVE_MINUTE%2COPEN%2CYESTCLOSE%2CHIGH%2CLOW%2CVOLUME%2CTURNOVER%2CHS%2CLB%2CWB%2CZF%2CPE%2CMCAP%2CTCAP%2CMFSUM%2CMFRATIO.MFRATIO2%2CMFRATIO.MFRATIO10%2CSNAME%2CCODE%2CANNOUNMT%2CUVSNEWS&sort=PERCENT&order=desc&count=24&type=query"我们试试效果:
from urllib.parse import parse_qsparse_qs(o.query)输出的结果如下:
{"host": ["http://quotes.money.163.com/hs/service/diyrank.php"], "page": ["1"], "query": ["PLATE_IDS:hy013000"], "fields": ["NO,SYMBOL,NAME,PRICE,PERCENT,UPDOWN,FIVE_MINUTE,OPEN,YESTCLOSE,HIGH,LOW,VOLUME,TURNOVER,HS,LB,WB,ZF,PE,MCAP,TCAP,MFSUM,MFRATIO.MFRATIO2,MFRATIO.MFRATIO10,SNAME,CODE,ANNOUNMT,UVSNEWS"], "sort": ["PERCENT"], "order": ["desc"], "count": ["24"], "type": ["query"]}哇,很不错!正是我们所需要的~以后再也不用复制粘贴后手动调整为字典格式啦!
另外,还有parse_qsl方法,可以将查询组件转化为元组组成的列表,大家可以自行演示哈~
3. 获取查询组件前面的部分
作为不专业的我,也不知道应该怎么专业的称呼前面的部分。
感觉吧,直接复制前面部分过来就好了吧。
# 直接复制到 ? 部分就行了base_url = "http://quotes.money.163.com/hs/service/diyrank.php?"4. 所以整个流程就是这样的
大家可以参考《python爬取股票最新数据并用excel绘制树状图》里的代码对比以下代码看下:
import requestsfrom urllib.parse import parse_qs, urlparse# 拷贝整体地址过来url = "http://quotes.money.163.com/hs/service/diyrank.php?host=http%3A%2F%2Fquotes.money.163.com%2Fhs%2Fservice%2Fdiyrank.php&page=1&query=PLATE_IDS%3Ahy013000&fields=NO%2CSYMBOL%2CNAME%2CPRICE%2CPERCENT%2CUPDOWN%2CFIVE_MINUTE%2COPEN%2CYESTCLOSE%2CHIGH%2CLOW%2CVOLUME%2CTURNOVER%2CHS%2CLB%2CWB%2CZF%2CPE%2CMCAP%2CTCAP%2CMFSUM%2CMFRATIO.MFRATIO2%2CMFRATIO.MFRATIO10%2CSNAME%2CCODE%2CANNOUNMT%2CUVSNEWS&sort=PERCENT&order=desc&count=24&type=query"# 解析URLo = urlparse(url)# 将请求参数部分转化为 字典格式params = parse_qs(o.query)# 设置可变参数,这里是页数page = 2params["page"] = [page]# 请求参数前面的部分base_url = "http://quotes.money.163.com/hs/service/diyrank.php?"# 请求数据r = requests.get(base_url, params=params)r.json()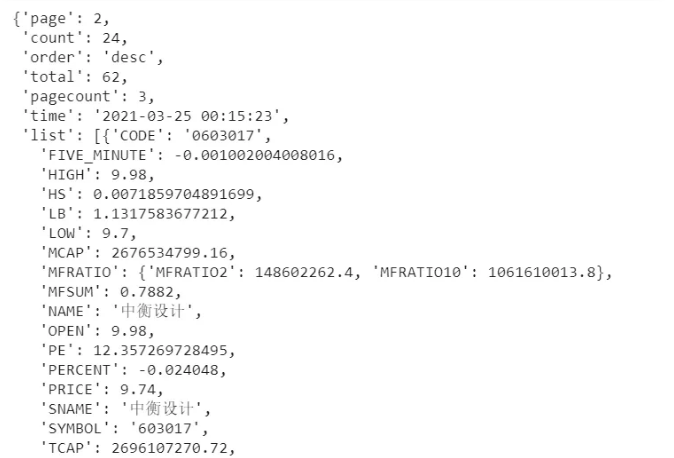 请求的数据预览截取
请求的数据预览截取5. 关于urllib.parse的其他操作
-
路径组合 urljoin
In [1]: from urllib.parse import urljoin ...: ...: urljoin("http://www.cwi.nl/%7Eguido/Python.html", "FAQ.html")Out[1]: "http://www.cwi.nl/%7Eguido/FAQ.html"In [2]: urljoin("http://www.cwi.nl/%7Eguido/Python.html", "./FAQ.html")Out[2]: "http://www.cwi.nl/%7Eguido/FAQ.html"In [3]: urljoin("http://www.cwi.nl/%7Eguido/Python.html", "../FAQ.html")Out[3]: "http://www.cwi.nl/FAQ.html"-
将字典转化为查询参数 urlencode
其实就是parse_qs的逆向操作:
In [4]: from urllib.parse import urlencode ...: ...: query = { ...: "a":1, ...: "b":"bbk" ...: } ...: ...: urlencode(query)Out[4]: "a=1&b=bbk"-
字符转义 quote和quote_plus
我们可以看到在第一部分例子中,复制出来的网址中有这样一部分:
❝
host=http%3A%2F%2Fquotes.money.163.com%2Fhs%2Fservice%2Fdiyrank.php
解析后其实是如下部分,: 变成了%3A ,/变成了%2F
❝
这其实就是字符转义了,在实际 请求数据的时候,url地址里的一些特殊字符会被转义。
关于转义部分,以后有机会我们详情学习下,大家可以这样看看了解下先:
In [5]: from urllib.parse import quote, quote_plusIn [6]: quote("abc d%e/")Out[6]: "abc%20d%25e/" # 未转义 / 号In [7]: quote_plus("abc d%e/")Out[7]: "abc+d%25e%2F" # 空格转义为了 + 号,且转义了 / 号 quote
quote-
解码操作 unquote和unquote_plus
这个就是上面的逆操作了:
In [8]: from urllib.parse import unquote, unquote_plusIn [8]: s1 = "abc+d%25e%2F" In [9]: unquote(s1)Out[9]: "abc+d%e/" # 未解码 + 号In [10]: unquote_plus(s1)Out[10]: "abc d%e/" # 解码 + 号 为 空格In [11]: s2 = "abc%20d%25e/"In [12]: unquote(s2)Out[12]: "abc d%e/"In [13]: unquote_plus(s2)Out[13]: "abc d%e/"以上就是本次全部内容,感谢大家查阅观看~
更多详情大家可以参考 本文 参考资料 ↓↓↓
[参考资料]:
https://docs.python.org/zh-cn/3/library/urllib.parse.html python官方中文文档
End.
作者:可以叫我才哥
介绍:混迹过北上深的资深游戏运营师,数据爱好者,喜欢学习分享游戏运营、数据分析、网络爬虫和数据可视化等知识笔记
本文为爱数据网站专栏作者原创文章,未经允许禁止转载,需要转载请微信联系授权(微信号:lovedata0520)
更多文章前往首页浏览http://www.itongji.cn/
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论