
一、前言
我们先来看个数据需求场景,现在我有一张明细表,这张表里面存储了每个店铺的成交明细,其中包含每个店铺所属的城市、地区、大区属性,我需要通过这张明细表获取到每个店铺、每个城市、每个省份、每个大区以及全国在最近一个月的成交量情况,我该怎么做呢?
明细表 t 如下:
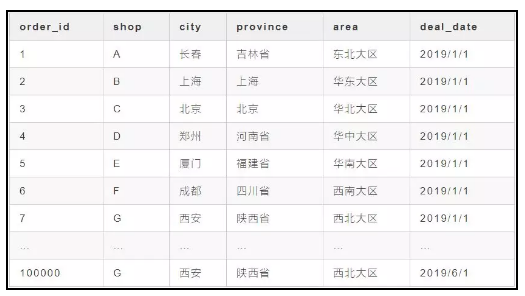
有一种最简单的方法就是,我们写5个 Sql 语句,然后将数据导出来在 Excel 中处理。5个 Sql 语句如下:想一下,我们要做上面的那个需求,我们应该怎么做呢?
全国成交量
select count(orderid) as sales from t where deal_date between "2019-05-01" and "2019-05-31"
大区成交量
select area ,count(orderid) as sales from t where deal_date between "2019-05-01" and "2019-05-31"group by area
省份成交量
select area ,province ,count(orderid) as sales from t where deal_date between "2019-05-01" and "2019-05-31"group by area ,province
城市成交量
select area ,province ,city ,count(orderid) as sales from t where deal_date between "2019-05-01" and "2019-05-31"group by area ,province ,city
店铺成交量
select area ,province ,city ,shop ,count(orderid) as sales from t where deal_date between "2019-05-01" and "2019-05-31"group by area ,province ,city ,shop
上面这种方法可以达到我们的目的,满足我们的需求,但是这种方法太低效了,我们在Excel中还需要做合并处理,很麻烦。能不能把上面几种结果在 Sql 中就进行合并处理,这样就不需要在 Excel 中合并了。答案是可以的,需要借助的就是 union 和 union all,对查询结果进行纵向合并。
union 和 union all的区别在于:前者是对合并后的结果进行去重处理,而后者返回合并后的所有数据。
具体代码如下:
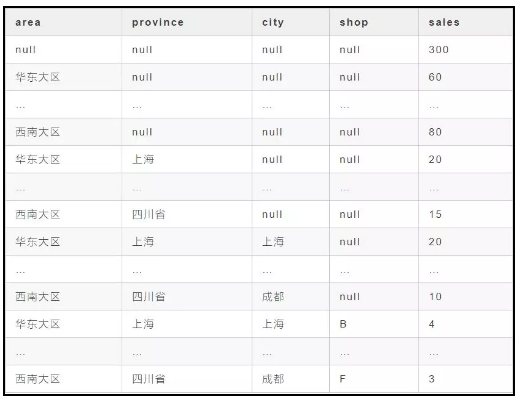
select null,null,null,null,count(orderid) as sales from t where deal_date between "2019-05-01" and "2019-05-31"union allselect area,null,null,null,count(orderid) as sales from t where deal_date between "2019-05-01" and "2019-05-31"group by areaunion allselect area,province,null,null,count(orderid) as sales from t where deal_date between "2019-05-01" and "2019-05-31"group by area,provinceunion allselect area,province ,city,null,count(orderid) as sales from t where deal_date between "2019-05-01" and "2019-05-31"group by area,province,cityunion allselect area,province,city,shop,count(orderid) as sales from t where deal_date between "2019-05-01" and "2019-05-31"group by area,province ,city,shop
大家应该注意到上面的语句中 select 了很多 null,那是因为union all 拼接的两个表的列数需要相等。最后出来的结果如下:
二、grouping sets
利用 union all 要比导出5个Sql然后再在 Excel 中处理简单多了,但是有没有发现上面的代码很长,很冗余。有人发现了,有人不仅发现了,还想出了一种更好的方法去解决,具体是什么方法呢?就是我们今天要讲的group by的 plus 版。真名叫做 grouping sets。这个 plus 可以根据不同维度组合进行聚合。比如根据大区聚合、根据大区和省份聚合、根据大区省份和城市聚合、根据大区省份城市和店铺聚合。
将上面 union all 语句用 grouping sets 改写以后,代码如下:
select null ,area ,province ,city ,shop ,count(orderid) as sales ,grouping_idfrom t where deal_date between "2019-05-01" and "2019-05-31"group by null ,area ,province ,city ,shopgrouping sets (null ,area ,(area,province) ,(area,province,city) ,(area,province ,city,shop))order by grouping_id
上面代码得到的效果和利用 union all 拼接得到的效果是一样的,但是要比拼接的代码简洁很多。group by后面放的字段表示要分组聚合的全部字段,grouping sets 后面放的是 group by 后面各种字段的组合,根据实际需求进行组合就行,组合字段用小括号括起来,也可以是单一字段。
在求取全国的成交量的时候其实是不需要分组聚合的,但是为了使用grouping sets,所以我们在求取全国成交量的时候用 group by null。
grouping_id 用来表示每个分组的序号。1表示第一个分组、2表示第二个分组、。。。我们可以根据grouping_id 选取出我们需要的组合。如果我们需要全国的成交量,让 grouping_id = 1即可;如果我们需要每个省份的成交量,让 grouping_id = 3即可。其他也是同样的道理。
三、cube
看完 grouping sets 后,我们再来看另一个 plus 版,就是cube。这个函数是对 group by 的维度的所有组合进行聚合。直接来看代码:
select area ,province ,count(orderid) as sales ,grouping_id from t where deal_date between "2019-05-01" and "2019-05-31"group by area ,provincewith cubeorder by grouping_id
上面代码是对区域和省份进行聚合,并利用了 cube ,最后得到的结果如下:
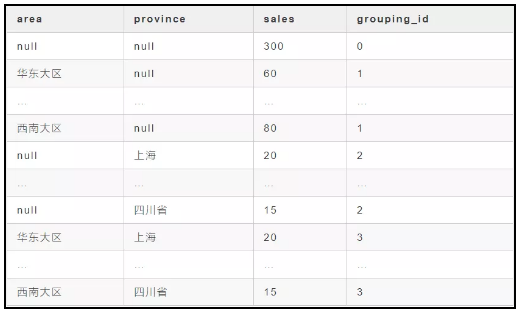
cube 会先对全部数据进行聚合,即 null,null,再对area,null 进行聚合,然后再对 null,province 进行聚合,最后再对 area,province进行聚合。
四、rollup
再来看一下最后一个 plus 版,就是 rollup。这个函数其实和cube 挺像的,是针对 group by 所有维度的部分组合。还是上面的例子,我们来看一下运行结果。代码如下:
select area ,province ,count(orderid) as sales ,grouping_id from t where deal_date between "2019-05-01" and "2019-05-31"group by area ,provincewith rolluporder by grouping_id
最后得到的结果如下:
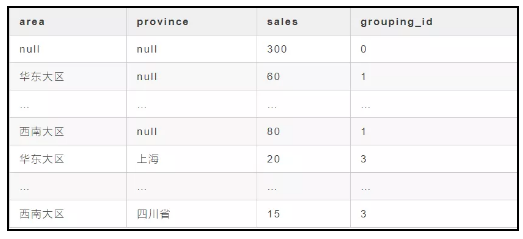
仔细观察一下 cube 和 rollup 得到的结果,我们会发现rollup 少了 null province 这一个组合,看出差别来了吧,rollup 是以最左侧指标为主进行组合聚合。
这一节讲的这几个 plus 版函数很实用,如果熟练掌握了,可以减少很多工作量的。
End.
爱数据网专栏作者:张俊红
作者介绍:一个数据科学路上的学习者、实践者、传播者
个人公众号:俊红的数据分析之路
本文为挖数网专栏作者原创文章,未经允许禁止转载,需要转载请微信联系授权(微信号:lovedata0520)
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论