
一、什么是窗口函数
我们都知道 SQL 中的聚合函数,聚合函数顾名思义就是聚集合并的意思,是对某个范围内的数值进行聚合,聚合后的结果是一个值或是各个类别对应的值。如下所示:
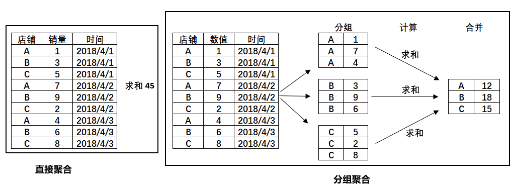
直接聚合得到的结果是所有店铺在这段时间内的所有销量之和,分组聚合(group by)得到的结果是每个店铺在这段时间内的销量之和。
这种聚合函数得到的数据行数是小于基础数据行数的,但是我们经常会有这样的需求,就是既希望看基础数据同时也希望查看聚合后的数据,这个时候聚合函数就满足不了我们了,窗口函数就派上用场了。窗口函数就是既可以显示原始基础数据也可以显示聚合数据。可能你还是不太理解,没关系,我也刚开始不太理解,我们看几个关于窗口函数的具体的应用就理解了。
二、聚合函数+over()
现在有如下的一张表 t 存储了每个店铺每天的销量:
shopname sales date A 1 2018/4/1 B 3 2018/4/1 C 5 2018/4/1 A 7 2018/4/2 B 9 2018/4/2 C 2 2018/4/2 A 4 2018/4/3 B 6 2018/4/3 C 8 2018/4/3
如果我们想看一下每个店铺每天的销量和一段时间内所有店铺销量的平均值的话该怎么做呢?答案就是可以用窗口函数来实现。只需要除了基础的查询代码以外,还需要在你要聚合的字段后面加一个 over(),语句如下所示:
select shopname ,sales ,date ,avg(sales) over()from t
最后结果如下所示:
shopname sales date avg_window_0A 1 2018/4/1 5B 3 2018/4/1 5C 5 2018/4/1 5A 7 2018/4/2 5B 9 2018/4/2 5C 2 2018/4/2 5A 4 2018/4/3 5B 6 2018/4/3 5C 8 2018/4/3 5
三、partition by子句
再想象一下,上面我们是拿每个店铺每天的销量和全部店铺全部天数的平均销量作比较,如果我们现在想让每个店铺每天的销量与自身全部天数的平均值作比较,该怎么实现呢?答案就是使用 partition by ,partition by的作用和 group by 是类似的,是进行分组聚合的,需要与 over() 搭配使用。
select shopname ,sales ,date ,avg(sales) over(partition by shopname)from t
最后结果如下所示:
shopname sales date avg_window_0A 1 2018/4/1 4B 3 2018/4/1 6C 5 2018/4/1 5A 7 2018/4/2 4B 9 2018/4/2 6C 2 2018/4/2 5A 4 2018/4/3 4B 6 2018/4/3 6C 8 2018/4/3 5
四、order by子句
order by 就是按照某一列数值进行排序,主要与接下来的序列函数结合使用,当 order by 与聚合函数一起使用时,是顺序聚合的。什么叫顺序聚合呢?给大家举一个求和的聚合与 order by 结合使用的例子,就是类似于累计和的效果,具体代码如下:
select shopname ,sales ,date ,sum(sales) over(partition by shopname order by date)from t
最后运行结果如下:
shopname sales date sum_window_0A 1 2018/4/1 1A 7 2018/4/2 8A 4 2018/4/3 12B 3 2018/4/1 3B 9 2018/4/2 12B 6 2018/4/3 18C 5 2018/4/1 5C 2 2018/4/2 7C 8 2018/4/3 15
当 order by 与序列函数一起使用时就是用于排序。
五、序列函数
什么是序列函数,就是可以将数据整理成一个有序的序列,然后我们可以在这个序列里面挑选我们想要的序列对应的数据。
1、 ntile
ntile 函数主要是用于将整表数据进行切片分组,默认是对表在不做任何操作之前进行切片分组的,比如现在整个表有9行数据,你要切片分成3组,那么就是第 1-3 行为一组,4-6 行为一组,7-9 行为一组。我们将店铺销量表切分成3组,代码如下:
select shopname ,date ,sales ,ntile(3) over()from t
最后结果如下:
shopname sales date ntile_window_0A 1 2018/4/1 1B 3 2018/4/1 1C 5 2018/4/1 1A 7 2018/4/2 2B 9 2018/4/2 2C 2 2018/4/2 2A 4 2018/4/3 3B 6 2018/4/3 3C 8 2018/4/3 3
上面是把销量表切分成3组了,但是对我们实际应用中没什么实际作用啊,你想一下,你拿一个乱序分组有什么用?如果我们和 order by结合使用就有用了,比如我先按照 sales 升序排列,然后再进行切片分组,这个时候的切片就有意义了。也可以在分组内(partition by)近行切片分组,示例如下:
select shopname ,date ,sales ,ntile(3) over(partition by shopname order by sales)from t
最后结果如下:
shopname sales date ntile_window_0A 1 2018/4/1 1A 4 2018/4/3 2A 7 2018/4/2 3B 3 2018/4/1 1B 6 2018/4/3 2B 9 2018/4/2 3C 2 2018/4/2 1C 5 2018/4/1 2C 8 2018/4/3 3
2、row_number
row_number() 从 1 开始,按照顺序(注意这里是顺序不是排序)生成该条数据在分组内的对应的序列数,row_number() 的值不会存在重复,当排序的值相同时,按照表中记录的顺序进行排列。
因为 row_number() 是按照顺序生成对应的序列,而不是按照排序来生成序列的,所以 row_number() 一般需要与 order by 进行结合使用。
你现在想看一下,在一段时间内每个店铺 sales 对应最早的一次 date 是什么时候?该怎么看呢?这个时候就可用 row_number() 与 order by 相结合,代码如下:
select shopname ,date ,sales ,row_number() over(partition by shopname order by date)from t
因为我们是要查看每个店铺最早的一次 date,所以需要对 date 进行升序排列。最后结果如下:
shopname sales date row_number_window_0A 1 2018/4/1 1A 7 2018/4/2 2A 4 2018/4/3 3B 3 2018/4/1 1B 9 2018/4/2 2B 6 2018/4/3 3C 5 2018/4/1 1C 2 2018/4/2 2C 8 2018/4/3 3
我们只需要把 num = 1 的部分取出来就是我们想要的结果。
3、 lag和lead
lag 的英文意思是滞后,而 lead 的英文意思是超前。对应的 lag 是让数据向后移动,而 lead 是让数据向前移动。你可能不太理解,无所谓,直接来看实例。
现在你想看一下每个店铺这一次和上一次 date 的时间差,你该怎么看呢?可以借助 lag,代码如下:
select shopname ,date ,sales ,lag(date,1) over(partition by shopname order by date)from t
最后结果如下:
shopname sales date lag_window_0A 1 2018/4/1 NULLA 7 2018/4/2 2018/4/1A 4 2018/4/3 2018/4/2B 3 2018/4/1 NULLB 9 2018/4/2 2018/4/1B 6 2018/4/3 2018/4/2C 5 2018/4/1 NULLC 2 2018/4/2 2018/4/1C 8 2018/4/3 2018/4/2
现在你想看一下每个店铺这次和下一次 date 之间的时间差,你又该怎么看呢?可以借助 lead,代码如下:
select shopname ,date ,sales ,lead(date,1) over(partition by shopname order by date)from t
最后结果如下:
shopname sales date lead_window_0A 1 2018/4/1 2018/4/2A 7 2018/4/2 2018/4/3A 4 2018/4/3 NULLB 3 2018/4/1 2018/4/2B 9 2018/4/2 2018/4/3B 6 2018/4/3 NULLC 5 2018/4/1 2018/4/2C 2 2018/4/2 2018/4/1C 8 2018/4/3 2018/4/3
4、first_value和last_value
first_value 和 last_value 都是顾名思义,就是获取第一个值和最后一个值。但是不是真正意义上的第一个或最后一个,而是截至到当前行的第一个或最后一个。
现在你想看一下每个店铺的首次 date 和最后一次 date,你会怎么看呢?就可以直接借助first_value 和 last_value,代码如下:
select shopname ,date ,sales ,first_value(date) over(partition by shopname order by date) ,last_value(date) over(partition by shopname order by date)from t
最后结果如下:
shopname sales date first_value_window_0 last_value_window_0A 1 2018/4/1 2018/4/1 2018/4/1A 7 2018/4/2 2018/4/1 2018/4/2A 4 2018/4/3 2018/4/1 2018/4/3B 3 2018/4/1 2018/4/1 2018/4/1B 9 2018/4/2 2018/4/1 2018/4/2B 6 2018/4/3 2018/4/1 2018/4/3C 5 2018/4/1 2018/4/1 2018/4/1C 2 2018/4/2 2018/4/1 2018/4/2C 8 2018/4/3 2018/4/1 2018/4/3
End.
爱数据网专栏作者:张俊红
作者介绍:一个数据科学路上的学习者、实践者、传播者
个人公众号:俊红的数据分析之路
本文为挖数网专栏作者原创文章,未经允许禁止转载,需要转载请微信联系授权(微信号:lovedata0520)
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论