
一、前言
写过或者学过 Sql 的人应该都知道 left join,知道 left join 的实现的效果,就是保留左表的全部信息,然后把右表往左表上拼接,如果拼不上就是 null。除了 left join以外,还有inner join、outer join、right join,这些不同的 join 能达到的什么样的效果,大家应该都了解了,如果不了解的可以看看网上的帖子或者随便一本 Sql 书都有讲的。今天我们不讲这些 join 能达到什么效果,我们主要讲这些 join 的底层原理是怎么实现的,也就是具体的效果是怎么呈现出来的。
为什么要讲底层原理呢?因为只有懂底层原理了,才知道如何更好的去写 join 语句,最后才能提高 select 的查询速度。
join 主要有Nested Loop、Hash Join、Merge Join这三种方式,我们这里只讲最普遍的,也是最好的理解的Nested Loop,Nested Loop 翻译过来就是嵌套循环的意思,那什么又是嵌套循环呢?嵌套大家应该都能理解,就是一层套一层;那循环呢,你可以理解成是 for 循环。
Nested Loop 里面又有三种细分的连接方式,分别是Simple Nested-Loop Join、Index Nested-Loop Join、Block Nested-Loop Join,接下来我们就分别去看一下这三种细分的连接方式。
在正式开始之前,先介绍两个概念,驱动表(也叫外表)和被驱动表(也叫非驱动表,还可以叫匹配表,亦可叫内表),简单来说,驱动表就是主表,left join 中的左表就是驱动表,right join 中的右表是驱动表。一个是驱动表,那另一个就只能是非驱动表了,在 join 的过程中,其实就是从驱动表里面依次(注意理解这里面的依次)取出每一个值,然后去非驱动表里面进行匹配,那具体是怎么匹配的呢?这就是我们接下来讲的这三种连接方式。
二、Simple Nested-Loop Join
Simple Nested-Loop Join 是这三种方法里面最简单,最好理解,也是最符合大家认知的一种连接方式,现在有两张表table A 和 table B,我们让 table A left join table B,如果是用第一种连接方式去实现的话,会是怎么去匹配的呢?直接上图:
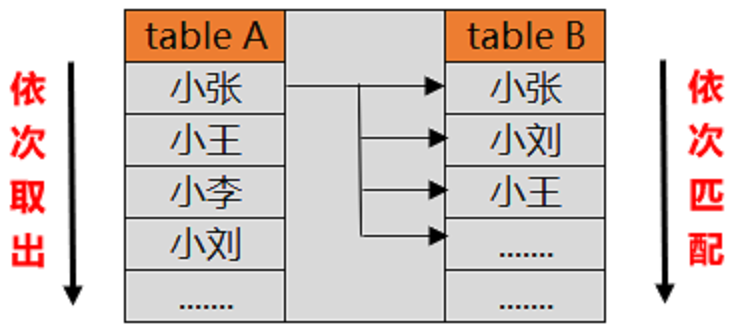
上面的 left join 会从驱动表 table A 中依次取出每一个值,然后去非驱动表 table B 中从上往下依次匹配,然后把匹配到的值进行返回,最后把所有返回值进行合并,这样我们就查找到了table A left join table B的结果。是不是和你的认知是一样的呢?利用这种方法,如果 table A 有10行,table B 有10行,总共需要执行10 x 10 = 100次查询。
这种暴力匹配的方式在数据库中一般不使用。
三、Index Nested-Loop Join
Index Nested-Loop Join 这种方法中,我们看到了 Index,大家应该都知道这个就是索引的意思,这个 Index 是要求非驱动表上要有索引,有了索引以后可以减少匹配次数,匹配次数减少了就可以提高查询的效率了。
为什么会有了索引以后可以减少查询的次数呢?这个其实就涉及到数据结构里面的一些知识了,给大家举个例子就清楚了。
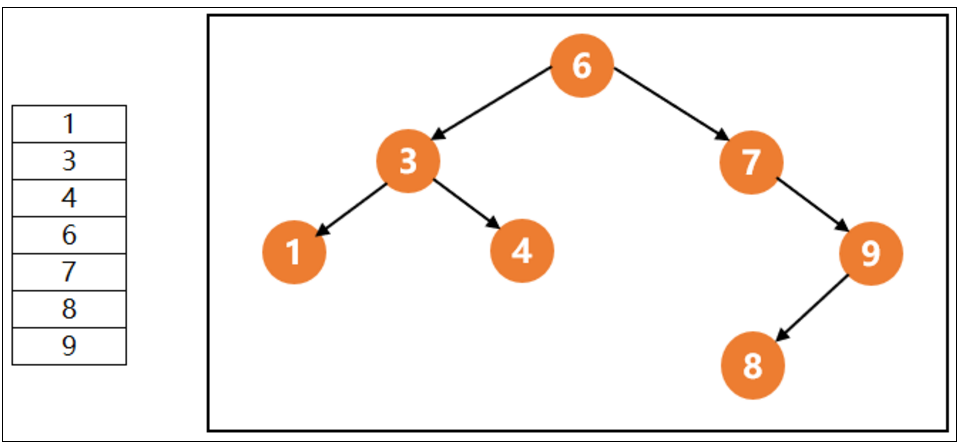
上图中左边就是普通列的存储方式,右边是树结构索引,什么是树结构呢?就是数据分布的像树这样一层一层的,树结构有一个特点就是左边的数据小于顶点的数,右边的数大于顶点的数,你看右图中,左边的数3是不是小于顶点6,右边的数7是不是大于顶点6;左边的数1是不是小于顶点3,右边的数4是不是大于顶点3。
假如我们现在要匹配数值9,如果是左边这种数据存储方式的话,我们需要从第一行依次匹配到最后一行才能找到数值9,总共需要匹配7次;但是如果我们是用右边这种树结构索引的话,我们先拿9和最上层顶点6去匹配,发现9比6大,我们就去顶点的右边去找,再去和7匹配,发现9仍然比7大,再去7的右边找,就找到了9,这样我们只匹配了3次就把我们想要的9找到了。是不是相比匹配7次节省了很多时间。
数据库中的索引一般用 B+ 树,为了让大家更好的理解,我上面画的图只是最简单的一种树结构,而非真实的 B+ 树,但是原理是一样的。感兴趣的同学可以去看我写的数据结构的文章:
如果索引是主键的话,效率会更高,因为主键必须是唯一的,所以如果被驱动表是用主键去连接,只会出现多对一或者一对一的情况,而不会出现多对多和一对多的情况。
四、Block Nested-Loop Join
理想情况下,用索引匹配是最高效的一种方式,但是在现实工作中,并不是所有的列都是索引列,这个时候就需要用到 Block Nested-Loop Join 方法了,这种方法与第一种方法比较类似,唯一的区别就是会把驱动表中 left join 涉及到的所有列(不止是用来on的列,还有select部分的列)先取出来放到一个缓存区域,然后再去和非驱动表进行匹配,这种方法和第一种方法相比所需要的匹配次数是一样的,差别就在于驱动表的列数不同,也就是数据量的多少不同。所以虽然匹配次数没有减少,但是总体的查询性能还是有提升的。
End.
爱数据网专栏作者:张俊红
作者介绍:一个数据科学路上的学习者、实践者、传播者
个人公众号:俊红的数据分析之路
本文为挖数网专栏作者原创文章,未经允许禁止转载,需要转载请微信联系授权(微信号:lovedata0520)
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论