
马蜂窝数据仓库的架构、模型与应用实践
3.4 主题分类
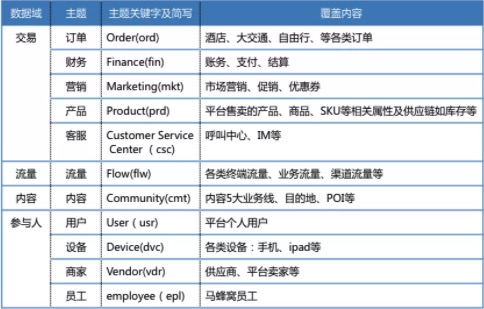
基于对目前各个部门和业务系统的梳理,马蜂窝数据仓库共设计了 4 个大数据域(交易、流量、内容、参与人),细分为 11 个主题:
以马蜂窝订单交易模型的建设为例,基于业务生产总线的设计是常见的模式,即首先调研订单交易的完整过程,定位过程中的关键节点,确认各节点上发生的核心事实信息。模型是数据的载体,我们要做的就是通过模型(或者说模型体系)归纳生产总线中各个节点发生的事实信息。订单生产总线:
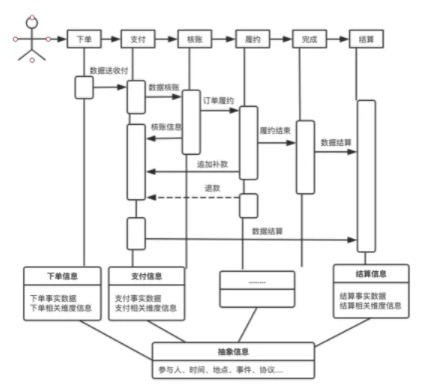
如上图所示,我们需要提炼各节点的核心信息,为了避免遗漏关键信息,一般情况下抽象认为节点的参与人、发生时间、发生事件、发生协议属于节点的核心信息,需要重点获取。以下单节点为例,参与人包括下单用户、服务商家、平台运营人员等;发生时间包括用户的下单时间、商家的确认时间等;发生的事件即用户购买了商品,需要记录围绕这一事件产生的相关信息;发生协议即产生的订单,订单金额、约定内容等都是我们需要记录的协议信息。
在这样的思路下,总线架构可以在模型中不断添加各个节点的核心信息,使模型支撑的应用范围逐步扩展、趋于完善。因此,对业务流程的理解程度将直接影响产出模型的质量。
涉及的业务节点越多,业务流程也就越复杂。从数据的角度看,这些业务过程会产生两种基本的场景形态,即数据的拆分和汇聚。随着流程的推进,前一节点的原子业务单位在新节点中可能需要拆分出更多信息,或者参与到新节点的多向流程。同样,也可能发生数据的汇聚。以某个订单为例,下单节点数据是订单粒度的,而到支付节点就发生了数据拆分。数据的拆分、汇聚伴随着总线的各节点,可能会一直发散下去。
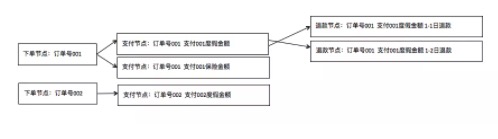
鉴于上述情况,在模型实现过程中,我们不能把各节点不同粒度的数据信息都堆砌在一起,那样会产生大量的冗余信息,也会使模型本身的定位不清晰,影响使用。因此,需要输出不同粒度的模型来满足各类应用需求。例如既会存在订单粒度的数据模型,也会存在分析各个订单在不同时间节点状态信息的数据模型。
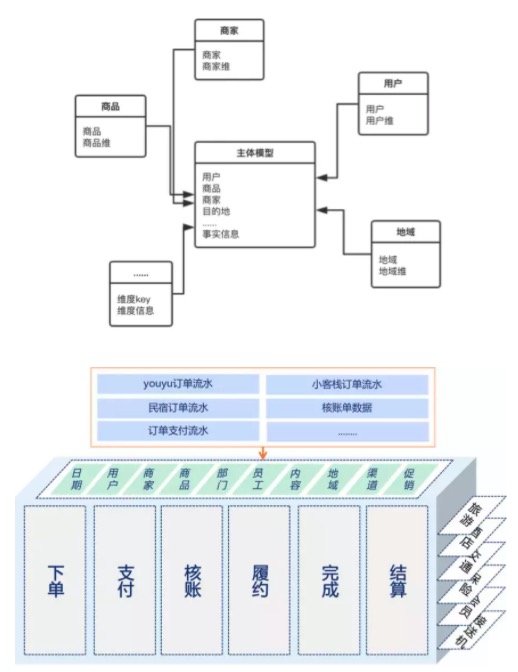
基于维度建模的思路,在模型整合生产总线各节点核心信息之后,会根据这些节点信息进一步扩展常用的分析维度,以减少应用层面频繁关联相关分析维度带来的资源消耗,模型会反范式冗余相关维度信息,以获取应用层的使用便捷。最终建立一个整合旅游、交通、酒店等各业务线与各业务节点信息的马蜂窝全流程订单模型。
Part.4 数据仓库工具链建设
为提升数据生产力,马蜂窝数据仓库建立了一套工具链,来实现采集、研发、管理流程的自动化。现阶段比较重要的有以下三大工具:
1. 数据同步工具
同步工具主要解决两个问题:
- 从源系统同步数据到数据仓库
- 将数据仓库的数据同步至其他环境
下面重点介绍从源系统同步数据到数据仓库。蜂窝的数据同步设计支撑灵活的数据接入方式,可以选择抽取方式以及加工方式。抽取方式主要包括增量抽取或者全量抽取,加工方式面向数据的存储方式,是需要对数据进行拉链式保存,或者以流水日志的方式进行存储。
接入时,只需要填写数据表信息配置,以及具体的字段配置信息,数据就可以自动接入到数据仓库,形成数仓的 ODS 层数据模型,如下:
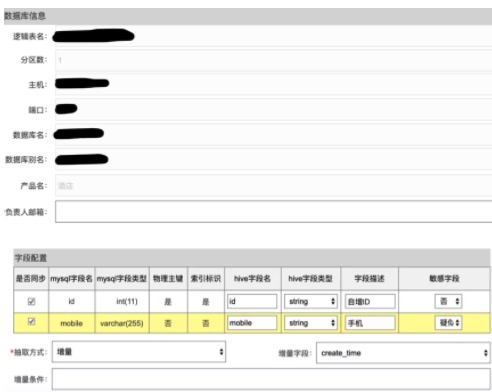
2. 任务调度平台
我们使用 Airflow 配合自研的任务调度系统,不仅能支持常规的任务调度,还可以支持任务调度系统各类数据重跑,历史补数等需求。
别小看数据重跑、历史补数,这两项功能是在选择调度工具中重要的参考项。做数据的人都清楚,在实际数据处理过程中会面临诸多的数据口径变化、数据异常等,需要进行数据重跑、刷新、补数等操作。
我们设计的「一键重跑」功能,可以将相关任务依赖的后置任务全部带出,并支持选择性地删除或虚拟执行任意节点的任务:
- 如果选择删除,这该任务之后所依赖的任务均不执行
- 如果选择虚拟执行,则会忽略(空跑)掉该任务,后置的所有依赖任务还是会正常执行。
3. 元数据管理工具
元数据范畴包括技术元数据、业务元数据、管理元数据,在概念上不做过多阐述了。元数据管理在数据建设起着举足轻重的作用,这部分在数仓应用中主要有 2 个点:
(1)血缘管理
血缘管理可以追溯数据加工整体链路,解析表的来龙去脉,用于支撑各类场景,如:
- 支持上游变更对下游影响的分析与调整
- 监控各节点、各链路任务运行成本,效率
- 监控数据模型的依赖数量,确认哪些是重点模型
(2)数据知识管理
通过对技术、业务元数据进行清晰、详尽地描述,形成数据知识,给数据人员提供更好的使用向导。我们的数据知识主要包括实体说明与属性说明,具体如下:
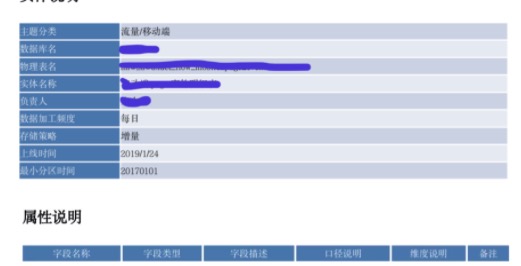
当然,数仓工具链条中还有非常多工具,例如自动化建模工具,数据质量管理工具,数据开发工具等,都已经得到了很好地实现。
Part.5 数仓应用——指标平台
有了合理的数仓架构、工具链条支撑数据研发,接下来,就要考虑如何把产出的数据对外赋能。下面以马蜂窝数据应用利器-指标平台,进行简单介绍。
几乎所有的企业都会构建自己的指标平台,每个企业建立的标准都不一样。在这个过程中会遇到指标繁多、定义不清楚、查询缓慢等问题。为尽量避免这些问题,指标平台在设计时需要遵循几大原则:
- 指标定义标准,清晰,容易理解,且不存在二义性,分类明确
- 指标生产过程简单、透明、可配置化
- 指标查询效率需要满足快速响应
- 指标权限管理灵活可控
基于以上原则,马蜂窝的指标平台按照精细化的设计进行打造,指标平台组成架构如下图:
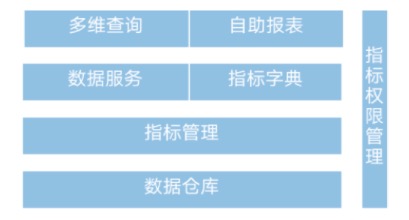
其中:
- 数据仓库是指标数据的来源,所有指标目前都是通过数据仓库统一加工的
- 指标管理包括指标创建与指标元数据管理:数仓负责生产并创建最核心、最基础的指标;其他人员可以基于这些指标,按照规则进行指标的派生;元数据管理记录指标的具体来源路径,说明指标的数据来源是数仓表,或者是 Kylin,MySQL 或 ES
- 指标字典对外呈现指标的定义、口径、说明等,保证指标的透明化及可解释性
- 数据服务接受指标的查询请求,针对不同场景判断查询的成本,选择最优链路进行指标查询,并返回指标查询的结果
- 多维查询将可以提供查询服务的指标与维度通过界面呈现,用户可以基于维度选择指标或基于指标选择维度,查询具体需要的数据
- 权限管理贯彻始终,可以支持表级、指标级、维值级别的权限管理
Part.6 总结
企业的数据建设需要经历几个大的步骤:
- 第一步,业务数据化:顾名思义,一切业务都能通过数据反映,主要指的是将传统线下流程线上化;
- 第二步,数据智能化:光有数据还不行,还需要足够的智能,如何通过智能化的数据支撑运营、营销及各类业务,这是数据中台当前解决的主要问题;
- 第三步,数据业务化:也就是我们常说的数据驱动业务,数据不能只是数据,数据价值最大化在于可以驱动新的业务创新,带动企业增长。
目前大部企业目前都停留在第二个阶段,因为这一步需要足够夯实,才能为第三步打好基础,这也是为什么各大企业要投入很大成本到大数据平台、数据仓库乃至数据中台的建设中。
马蜂窝数据中台的建设才刚刚起步。我们认为,理想的数据中台需要具备数据标准化、工具组件化、组织清晰化这三个核心前提。为了向这一目标迈进,我们将建立统一、标准化的数据仓库作为当下数据中台的重点工作之一。
数据来源于业务,最终也将应用于业务。只有对数据足够重视,与业务充分衔接,才能实现数据价值的最大化。在马蜂窝,从管理层,到公司研发、产品、运营、销售等各角色,对数据非常重视,数据产品的使用人数占公司员工比例高达 75%。
大量用户的使用,驱动着我们在数据中台建设的路上不断前进。如何将新兴技术能力应用到数据仓库的建设,如何以有限的成本高效解决企业在数据建设中面临的问题,将是马蜂窝数仓建设一直的思考。
End.
作者:马蜂窝技术
本文为转载分享,如果涉及作品、版权和其他问题,请联系我们第一时间删除(微信号:lovedata0520)
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论