
由于疫情的关系,原本线下的AWD改成线上CTF了,比赛内容是关于大数据的。
一、比赛介绍
大数据总体来说分为三个过程。
第一个过程是搭建hadoop环境。
hadoop就是一个集成环境,这个环境里面包含了很多软件。这些软件的功能各不相同,比如文件分布式等;总的来说,就是为了大数据而服务的一个环境。
第二个过程就是爬取数据。
其中有爬取视频的弹幕。这个要比单纯的爬取视频麻烦一点,因为每个网站对弹幕的算法不一样。一会儿我会写两个爬虫,分别爬取B站和A站的弹幕你们就知道了。
第三个过程就是分析数据。
二、爬虫
爬虫其实是一种代称,只是功能比较特殊,所以这么叫。在没学爬虫之前,先想想看,我们正常是如何获取一些信息呢?比如我们想知道周杰伦的歌单都有什么的时候。
第一步肯定是去百度搜索周杰伦,然后我们就可以在qq音乐之类的音乐网站上看到周杰伦的歌单。爬虫也得这样。它没有你想象的那么神奇,肯定是要在某些网站上操作才行。
接着,你就可以一点一点的记录下来周杰伦的信息。我们的爬虫实现的也是这样的过程,只不过你一秒钟只能访问一个页面,而爬虫一秒钟可以访问几万个页面。
三、爬取网站弹幕
1、A站
A站相对于B站要简单一点、我们先观察网页,如下,这个是我随便打开的一个视频。
现在网站上的这些数据大部分都是动态的,因此我们不能直接用html解析器来解析网页,得直接爬取xhr里面的数据。
先按F12抓包。然后我们在搜索栏中随便搜索一条我们的弹幕。
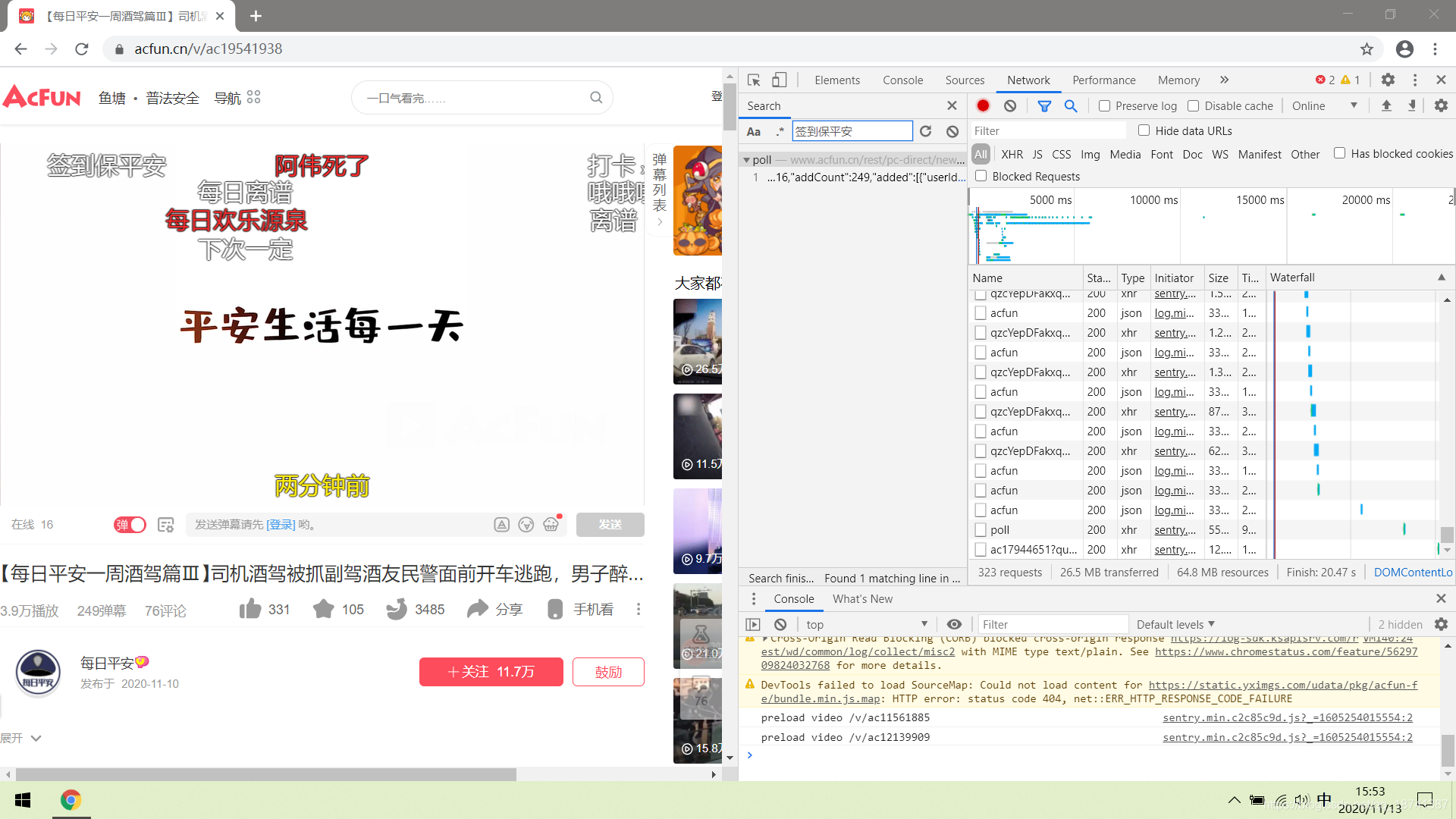
我们双击这个查找的结果并进行观察。点到privew,可以发现这里面包含了我们所有的弹幕。
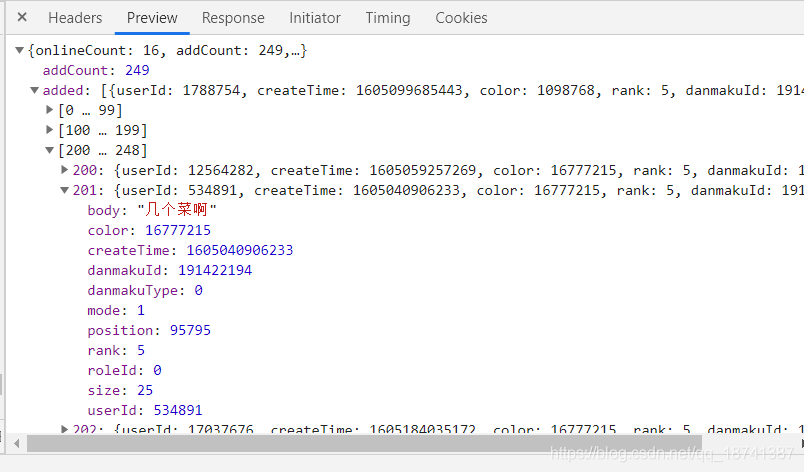
因此,这种网站直接爬取就行了。点到headers,我们观察参数以及请求方式。


这些得到了以后,上脚本。
import requests
url="https://www.acfun.cn/rest/pc-direct/new-danmaku/poll"
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36",
"cookie":""
#注意,cookie要填你自己的。A站有些特殊,爬取的时候需要加上cookie。
}
data={
"videoId":"15779946",
"lastFetchTime":"0",
"enableAdvanced":"true"
}
html=requests.post(url,headers=headers,data=data)
html=html.json()
html=html["added"]
for i in html:
print(i["body"])
效果如图:
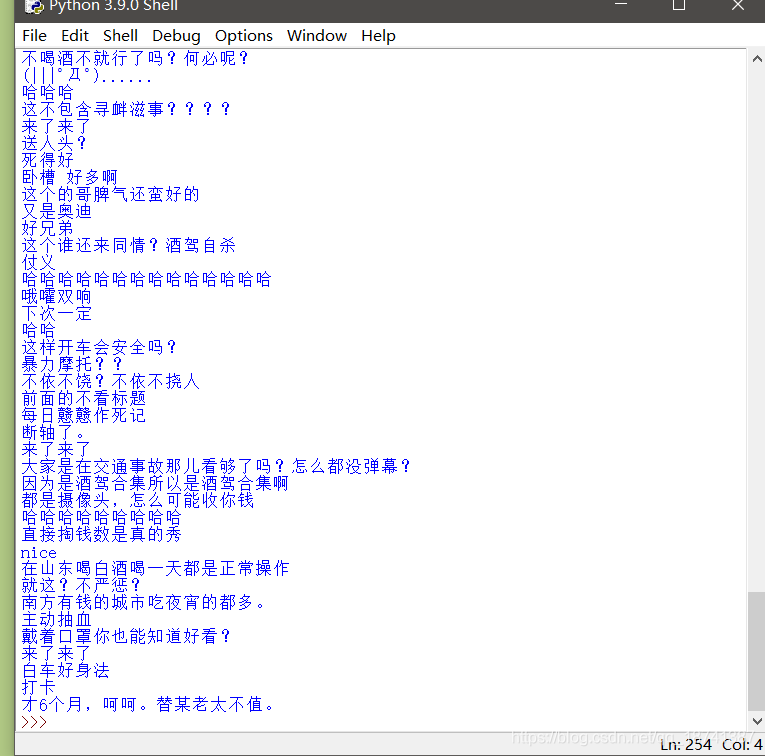
数量我数了一下,刚好是这个视频的弹幕数。你们可以添加自己的东西上去,比如增加写入文件的功能。
2、B站
B站的弹幕是另一种算法。
B站将弹幕单独剥离出来到了一个网页上,需要视频对应的cid才可以获得到弹幕对应的码,然后获得视频的弹幕信息。
举个例子:【哔哩哔哩2019拜年祭】
首先,我们要获取到视频的视频号以前是av号,现在是bv号。
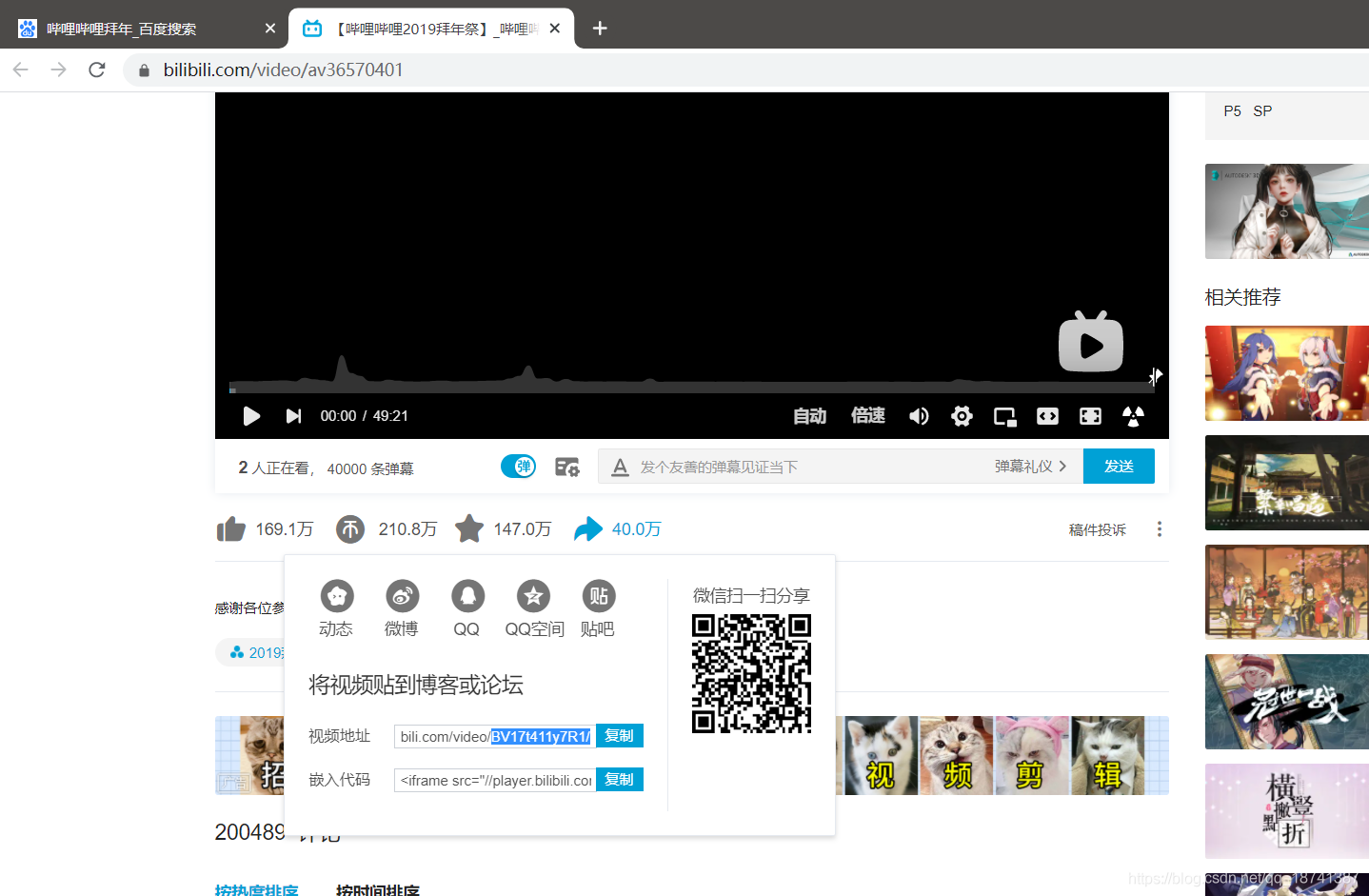
然后将这个链接加上你的bv号。这个是哔哩哔哩的一个api,可以获得cid。
https://api.bilibili.com/x/player/pagelist?bvid=BV17t411y7R1&jsonp=jsonp
将连接中的bvid换成bv号。
如图,我们发现了视频有4个cid。
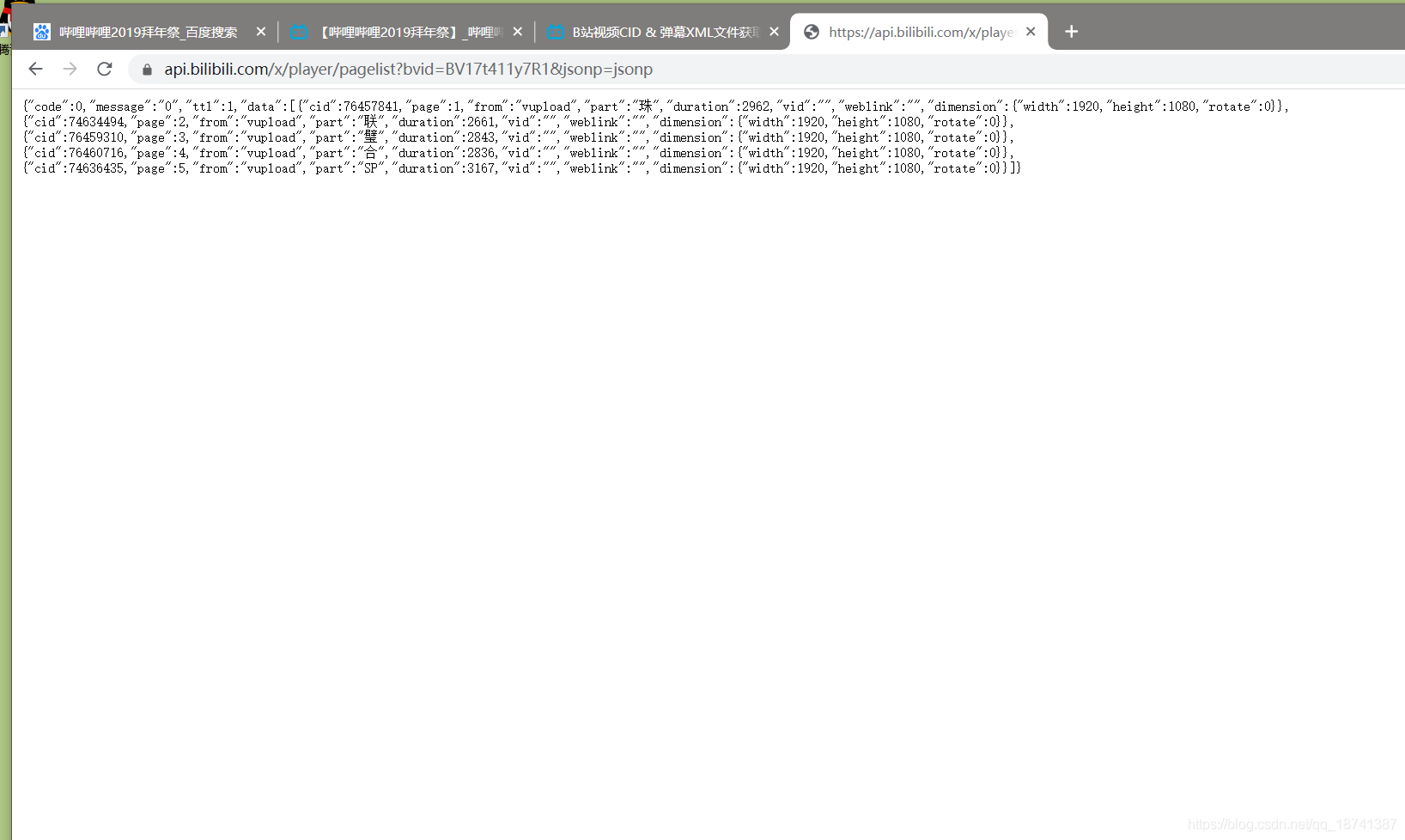
接着我们使用下一个api,这样就可以获得弹幕了。
https://comment.bilibili.com/76457841.xml
将后面的数字换成刚找到的cid。
结果如图:
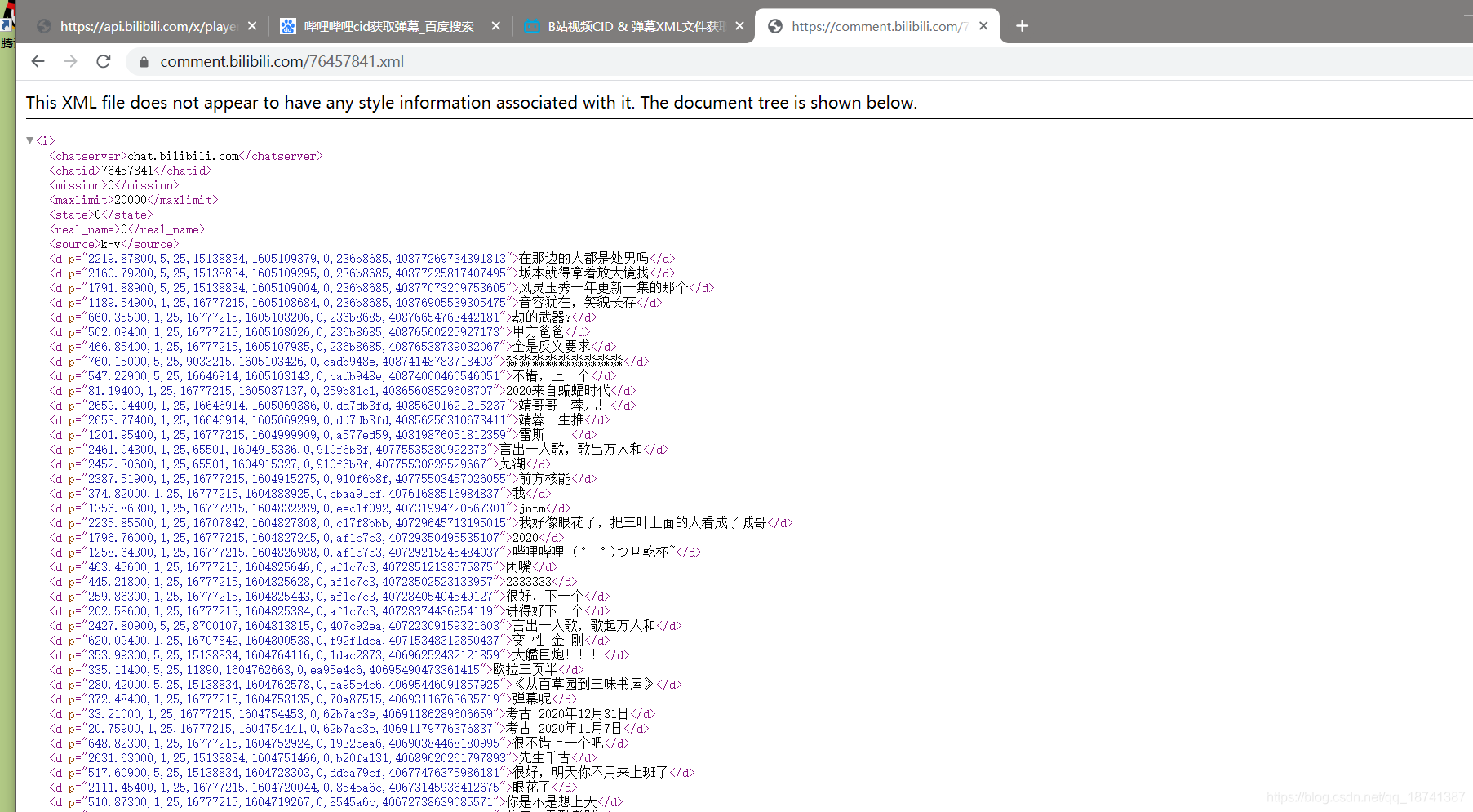
这就是我们手动获得弹幕的流程,接下来就是用爬虫做出来就行了。
第一步,将bv转成av号。其实你可以直接用bv号,但是由于我做这个帖子之前的时候用的是av号找的,所以加了这么一步。
这一步直接去网上找工具就行了,有很多,就不往代码上面加了。
第二步,用刚才给的第二个api获得cid。我们使用爬虫即可,将网址构造成规定的格式。
https://www.bilibili.com/widget/getPageList?aid=?
问号换成aid。
第三步,爬取。可以看到我们最终返回的是一个xml文件,所以用爬虫里面的xml解析器解析即可,直接上代码。
import requests
from bs4 import BeautifulSoup
import lxml
aid=input("请输入av号:如果是bv码请转换为av号
")
file_name=input("请输入保存文件名:
")
f=open(file_name,"a",encoding="utf-8")
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36"
}
get_cid="https://www.bilibili.com/widget/getPageList?aid="+aid
cid_list=eval(requests.get(get_cid).text)
for cid in cid_list:
cid=cid["cid"]
xml="https://comment.bilibili.com/"+str(cid)+".xml"
html=requests.get(xml,headers=headers)
html.encoding=html.apparent_encoding
soup=BeautifulSoup(html.text,"xml").find_all("d")
for dm in soup:
f.write(dm.text+"
")
f.close()
这个是直接将弹幕文件保存到本地了,为了方便后续的分析。
结果如图:

一共是九万多条弹幕。在这里就不一个一个展示了。
四、数据分析
要说分析的话其实这个是很广的,得依据特定的要求来做。
第一个,高频词统计。
代码是我copy的,简单但是好用。
(将上一步的文件放到和脚本同一个目录下)
import jieba.analyse
f=open(r"bilibil周年庆.txt",encoding="utf-8")#打开文件
text=f.read()#读取文件
text_list=jieba.analyse.extract_tags(text,topK=40)#进行jieba分词,并且取频率出现最高的40个词
text_list=",".join(text_list)#用空格将这些字符串连接起来
print(text_list)
如图,40个出现字数最多的词汇就被统计出来了。
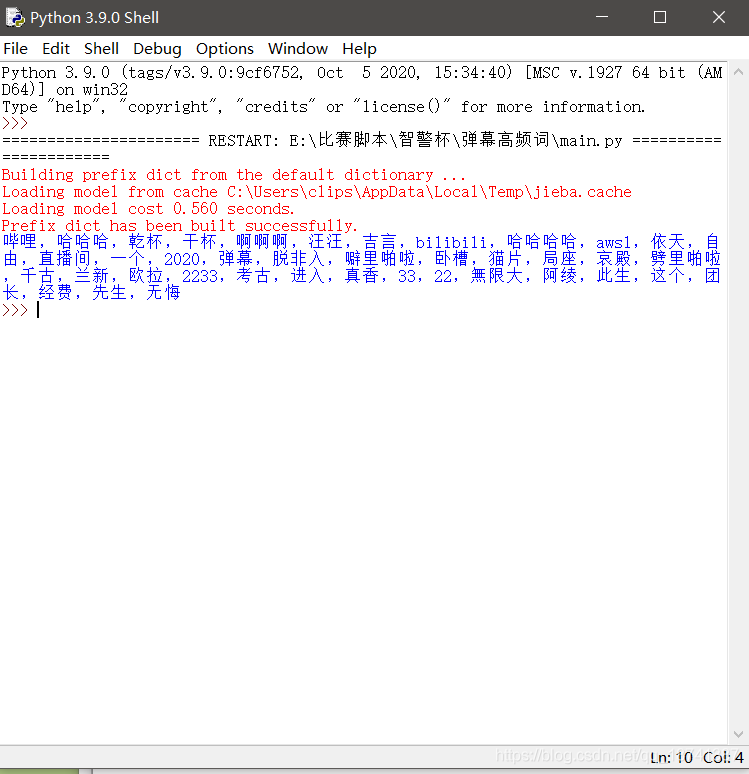
由于是机器识别,难免不准,所以不要在意。
第二个,情感分析。这个是我猜测可能会用的到的东西。
我们这个可以直接用baiduAPI来做,要比我们自己的写的好。这个api会将所有的数据进行情感预测,并且返回积极或者消极的概率。
不过你首先得去申请一个百度api的账号。这个就不说了。
代码也是我copy的。
(原本是要两个脚本,我改进了一下,写成了一个脚本。这个脚本仅仅测试了两个词,如果想对文件进行分析,稍微改动一下就行了。)
import re
import requests
import json
# 将text按照lenth长度分为不同的几段
def cut_text(text, lenth):
textArr=re.findall(".{"+str(lenth)+"}", text)
textArr.append(text[(len(textArr)*lenth):])
return textArr# 返回多段值
def get_emotion(access_token,data):# 情感分析
# 定义百度API情感分析的token值和URL值
token=access_token
url="https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?charset=UTF-8&access_token={}".format(token)
# 百度情感分析API的上限是2048字节,因此判断文章字节数小于2048,则直接调用
if (len(data.encode()) <2048):
new_each={
"text": data# 将文本数据保存在变量new_each中,data的数据类型为string
}
new_each=json.dumps(new_each)
res=requests.post(url, data=new_each)# 利用URL请求百度情感分析API
# print("content: ", res.content)
res_text=res.text# 保存分析得到的结果,以string格式保存
result=res_text.find("items")# 查找得到的结果中是否有items这一项
positive=1
if (result !=-1):# 如果结果不等于-1,则说明存在items这一项
json_data=json.loads(res.text)
negative=(json_data["items"][0]["negative_prob"])# 得到消极指数值
positive=(json_data["items"][0]["positive_prob"])# 得到积极指数值
print("positive:",positive)
print("negative:",negative)
# print(positive)
if (positive > negative):# 如果积极大于消极,则返回2
return 2
elif (positive==negative):# 如果消极等于积极,则返回1
return 1
else :
return 0# 否则,返回0
else :
return 1
else :
data=cut_text(data,1500)# 如果文章字节长度大于1500,则切分
# print(data)
sum_positive=0.0# 定义积极指数值总合
sum_negative=0.0# 定义消极指数值总和
for each in data:# 遍历每一段文字
# print(each)
new_each={
"text": each# 将文本数据保存在变量new_each中
}
new_each=json.dumps(new_each)
res=requests.post(url, data=new_each)# 利用URL请求百度情感分析API
# print("content: ", res.content)
res_text=res.text# 保存分析得到的结果,以string格式保存
result=res_text.find("items")# 查找得到的结果中是否有items这一项
if (result !=-1):
json_data=json.loads(res.text)# 如果结果不等于-1,则说明存在items这一项
positive=(json_data["items"][0]["positive_prob"])# 得到积极指数值
negative=(json_data["items"][0]["negative_prob"])# 得到消极指数值
sum_positive=sum_positive+positive# 积极指数值加和
sum_negative=sum_negative+negative# 消极指数值加和
# print(positive)
print(sum_positive)
print(sum_negative)
if (sum_positive > sum_negative):# 如果积极大于消极,则返回2
return 2
elif (sum_positive==sum_negative):# 如果消极等于于积极,则返回1
return 1
else :
return 0# 否则,返回0
defmain():
# client_id 为官网获取的API Key, client_secret 为官网获取的Secret Key
#这两个我都空出来了,你用你的填上就行了。
client_id=""
client_secret=""
host="https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id="+client_id+"&client_secret="+client_secret
response=requests.get(host)
list_new=eval(response.text)
access_token=list_new["access_token"]
txt1="你好优秀"
txt2="难过!"
print("txt1测试结果:",get_emotion(access_token,txt1))
print("txt2测试结果:",get_emotion(access_token,txt2))
if__name__=="__main__":
main()
效果如图:

剩下的内容比如折线图等就不详细说明了。
到此这篇关于详解python爬取弹幕与数据分析的文章就介绍到这了。
End.
作者:薯片薯条
本文为转载分享,如果涉及作品、版权和其他问题,请联系我们第一时间删除(微信号:lovedata0520)
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论