
我们曾经在golang关于goroutine的文章当中简单介绍过协程的概念,我们再来简单review一下。协程又称为是微线程,英文名是Coroutine。它和线程一样可以调度,但是不同的是线程的启动和调度需要通过操作系统来处理。并且线程的启动和销毁需要涉及一些操作系统的变量申请和销毁处理,需要的时间比较长。而协程呢,它的调度和销毁都是程序自己来控制的,因此它更加轻量级也更加灵活。
协程有这么多优点,自然也会有一些缺点,其中最大的缺点就是需要编程语言自己支持,否则的话需要开发者自己通过一些方法来实现协程。对于大部分语言来说,都不支持这一机制。go语言由于天然支持协程,并且支持得非常好,使得它广受好评,短短几年时间就迅速流行起来。
对于Python来说,本身就有着一个GIL这个巨大的先天问题。GIL是Python的全局锁,在它的限制下一个Python进程同一时间只能同时执行一个线程,即使是在多核心的机器当中。这就大大影响了Python的性能,尤其是在CPU密集型的工作上。所以为了提升Python的性能,很多开发者想出了使用多进程+协程的方式。一开始是开发者自行实现的,后来在Python3.4的版本当中,官方也收入了这个功能,因此目前可以光明正大地说,Python是支持协程的语言了。
一、生成器(generator)
生成器我们也在之前的文章当中介绍过,为什么我们介绍协程需要用到生成器呢,是因为Python的协程底层就是通过生成器来实现的。
通过生成器来实现协程的原因也很简单,我们都知道协程需要切换挂起,而生成器当中有一个yield关键字,刚好可以实现这个功能。所以当初那些自己在Python当中开发协程功能的程序员都是通过生成器来实现的,我们想要理解Python当中协程的运用,就必须从最原始的生成器开始。
生成器我们很熟悉了,本质上就是带有yield这个关键词的函数。
def test(): n = 0 while n < 10: val = yield n print("val = {}".format(val)) n += 1
这个函数当中如果没有yield这个语句,那么它就是一个普通的Python函数。加上了val = yield n这个语句之后,它有什么变化呢?
我们尝试着运行一下:
# 调用test函数获得一个生成器g = test()print(next(g))print(next(g))print(next(g))
得到这么一个结果:
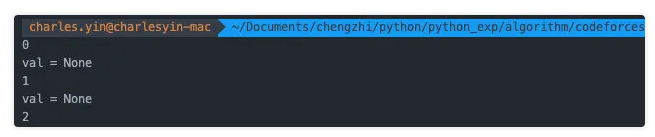
输出的0,1,2很好理解,就是通过next(g)返回的,这个也是生成器的标准用法。奇怪的是为什么val=None呢?val不应该等于n么?
这里想不明白是正常的,因为这里涉及到了一个新的用法就是生成器的send方法。当我们在yield语句之前加上变量名的时候,它的含义其实是返回yield之后的内容,再从外界接收一个变量。也就是说当我们执行next(g)的时候,会从获取yield之后的数,当我们执行g.send()时,传入的值会被赋值给yield之前的数。比如我们把执行的代码改成这样:
g = test()print(next(g))g.send("abc")print(next(g))print(next(g))
我们再来看执行的结果,会发现是这样的:
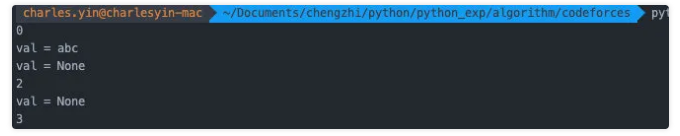
第一行val不再是None,而是我们刚刚传入的abc了。
二、队列调度
生成器每次在执行到yield语句之后都会自然挂起,我们可以利用这一点来当做协程来调度。我们可以自己实现一个简易的队列来模拟这个过程。
首先我们声明一个双端队列,每次从队列左边头部获取任务,调度执行到挂起之后,放入到队列末尾。相当于我们用循环的方式轮询执行了所有任务,并且这整个全程不涉及任何线程创建和销毁的过程。
class Scheduler: def __init__(self): self._queue = deque() def new_task(self, task): self._queue.append(task) def run(self): while self._queue: # 每次从队列左侧获取task task = self._queue.popleft() try: # 通过next执行之后放入队列右侧 next(task) self._queue.append(task) except StopIteration: passsch = Scheduler()sch.new_task(test(5))sch.new_task(test(10))sch.new_task(test(8))sch.run()
这个只是一个很简易的调度方法,事实上结合上yield from以及send功能,我们还可以实现出更加复杂的协程调度方式。但是我们也没有必要一一穷尽,只需要理解最基础的方法就可以了,毕竟现在我们使用协程一般也不会自己实现了,都会通过官方原生的工具库来实现。
三、@asyncio.coroutine
在Python3.4之后的版本当中,我们可以通过@asyncio.coroutine这个注解来将一个函数封装成协程执行的生成器。
在吸收了协程这个概念之后,Python对生成器以及协程做了区分。加上了@asyncio.coroutine注解的函数称为协程函数,我们可以用iscoroutinefunction()方法来判断一个函数是不是协程函数,通过这个协程函数返回的生成器对象称为协程对象,我们可以通过iscoroutine方法来判断一个对象是不是协程对象。
比如我把刚刚写的函数上加上注解之后再来执行这两个函数都会得到True:
import asyncio@asyncio.coroutinedef test(k): n = 0 while n < k: yield print("n = {}".format(n)) n += 1 print(asyncio.iscoroutinefunction(test))print(asyncio.iscoroutine(test(10)))
那我们通过注解将方法转变成了协程之后,又该怎么使用呢?一个比较好的方式是通过asynio库当中提供的loop工具,比如我们来看这么一个例子:
loop = asyncio.get_event_loop()loop.run_until_complete(test(10))loop.close()
我们通过asyncio.get_event_loop函数创建了一个调度器,通过调度器的run相关的方法来执行一个协程对象。我们可以run_until_complete也可以run_forever,具体怎么执行要看我们实际的使用场景。
四、async,await和future
从Python3.5版本开始,引入了async,await和future。我们来简单说说它们各自的用途,其中async其实就是@asyncio.coroutine,用途是完全一样的。同样await代替的是yield from,意为等待另外一个协程结束。
我们用这两个一改,上面的代码就成了:
async def test(k): n = 0 while n < k: await asyncio.sleep(0.5) print("n = {}".format(n)) n += 1
由于我们加上了await,所以每次在打印之前都会等待0.5秒。我们把await换成yield from也是一样的,只不过用await更加直观也更加贴合协程的含义。
Future其实可以看成是一个信号量,我们创建一个全局的future,当一个协程执行完成之后,将结果存入这个future当中。其他的协程可以await future来实现阻塞。我们来看一个例子就明白了:
future = asyncio.Future()async def test(k): n = 0 while n < k: await asyncio.sleep(0.5) print("n = {}".format(n)) n += 1 future.set_result("success")async def log(): result = await future print(result)loop = asyncio.get_event_loop()loop.run_until_complete(asyncio.wait([ log(), test(5)]))loop.close()
在这个例子当中我们创建了两个协程,第一个协程是每隔0.5秒print一个数字,在print完成之后把success写入到future当中。第二个协程就是等待future当中的数据,之后print出来。
在loop当中我们要调度执行的不在是一个协程对象了而是两个,所以我们用asyncio当中的wait将这两个对象包起来。只有当wait当中的两个对象执行结束,wait才会结束。loop等待的是wait的结束,而wait等待的是传入其中的协程的结束,这就形成了一个依赖循环,等价于这两个协程对象结束,loop才会结束。
五、总结
async并不止是可以用在函数上,事实上还有很多其他的用法,比如用在with语句上,用在for循环上等等。这些用法比较小众,细节也很多,就不一一展开了,大家感兴趣的可以自行去了解一下。
不知道大家在读这篇文章的过程当中有没有觉得有些费劲,如果有的话,其实是很正常的。原因也很简单,因为Python原生是不支持协程这个概念的,所以在一开始设计的时候也没有做这方面的准备,是后来觉得有必要才加入的。那么作为后面加入的内容,必然会对原先的很多内容产生影响,尤其是协程借助了之前生成器的概念来实现的,那么必然会有很多耦合不清楚的情况。这也是这一块的语法很乱,对初学者不友好的原因。
我建议大家可以先了解一下go语言当中的协程的概念和用法再来学习Python当中的async的用法,很多不明白的地方会清晰很多。
End.
爱数据网专栏作者:承志
作者介绍:前阿里人,推荐算法专家,一年更新400篇博文的勤奋作者
个人微信公众号:TechFlow(ID:techflow2019)
本文为挖数网专栏作者原创文章,未经允许禁止转载,需要转载请微信联系授权(微信号:lovedata0520)
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论