
一.RFM基本原理
RFM是三个单词的缩写:
最近一次消费时间 (Recency),取数的时候一般取最近一次消费记录到当前时间的间隔,比如7天、30天、90天未到店消费。
直观上,一个用户太久不到店消费,肯定是有问题,得做点什么事情。很多公司的用户唤醒机制都是基于这个制定的。
一定时间内消费频率 (Frequency),取数时,一般是取一个时间段内用户消费频率。比如一年内有多少个月消费,一个月内有多少天到店等等。
直观上,用户消费频率越高越忠诚。很多公司的用户激励机制都是基于这个制定的,买了一次还想让人家买第二次。
一定时间内累计消费金额(Monetary) ,取数时,一般是取一个时间段内用户消费金额。比如一年内有多少消费金额。
直观上,用户买的越多价值就越大。很多公司的VIP机制是基于这个指定的,满10000银卡,满20000金卡一类。

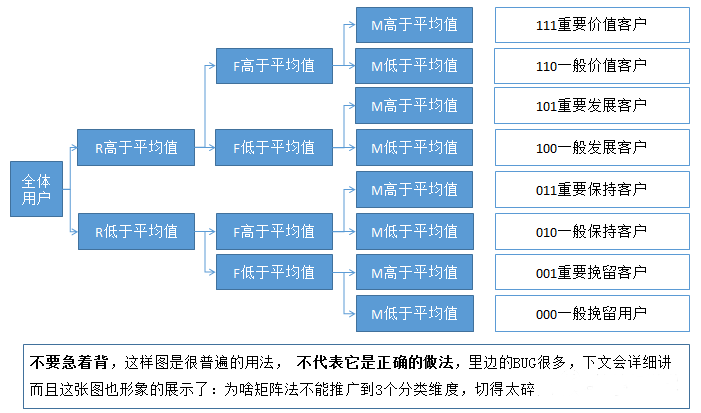
所以,即使单独看这三个维度,都是很有意义的。当然,也有把三个维度交叉起来看的(如下图)。
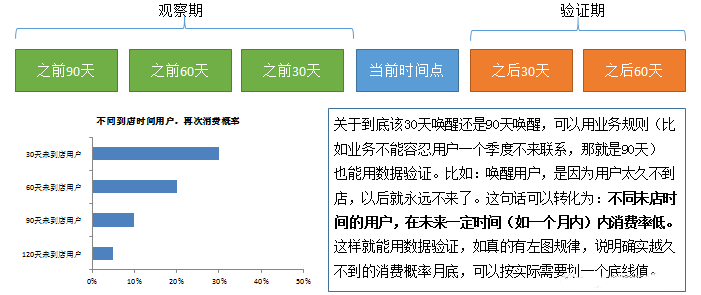
因为RFM与时间有关,因此很多同学在取数的时候会纠结时间怎么分。严格来说,越柴米油盐,消费频次本身越高的业务,取的时间应该越短。
最典型的就是生鲜,人天天都要吃饭,7天不来可能就有问题。普通的快消品零售可能取30天,类似服装百货零售可能取90天。当然,更多的做法是按月取。
比如:R按月取,F、M算最近一年内的数值。这样做单纯是因为比较方便理解而已。
RFM本质上是一种用三个分类维度,找判断标准方法。通过三个维度的组合计算,能判定出用户的好坏,然后采取对应措施。
RFM的真正意义,在于:这是一种从交易数据反推用户价值的方法,因此可行性非常高!要知道:做数据分析的最大瓶颈是数据采集,而只要是个正常企业,交易数据是肯定有的。
因此只要企业建立了用户ID统一认证机制,就能将用户ID与交易数据关联起来,就能用RFM来分析用户了。即使没有埋点、没有网站、没有基础信息也能做,简直是方便好用的神器。
当然,所有方便好用的工具,都自带一些不足,RFM模型也是如此。
二.RFM的最大短板
RFM最大的短板,在于用户ID统一认证。不要小看这几个字,在相当多的企业里非常难实现。
比如:你去超市、连锁店、门店买东西,往往收银小妹会机械的问一句:有会员卡吗?如果回答没有,她也放你过去了。
导致的结果,是线下门店的订单,一般有70%-90%无法关联到用户ID,进而导致整个用户数据是严重缺失的,直接套RFM很容易误判用户行为。
至于用户一人多张会员卡轮流薅羊毛,多个用户共同一张VIP卡拿最大折扣,店员自己用亲戚的卡把无ID订单的羊毛给薅了之类的事,更是层出不穷,而且在实体企业、互联网企业都普遍存在。
所以做RFM模型的时候,如果你真看到111类用户,别高兴太早,十有八九是有问题的。现在的企业往往在天猫、京东、自有微商城、有赞等几个平台同时运作,更加大了统一认证的难度。如果没有规划好,很容易陷入无穷无尽的补贴大坑。
三.RFM的深层问题
即使做好了用户ID统一认证,RFM还有一个更深层的问题。
让我们回顾一下,RFM模型的三个基本假设:
- R:用户离得越久就越有流失风险
- F:用户频次越高越忠诚
- M:用户买的越多越有价值
反问一句:这三个假设成立吗?如果不结合具体行业、具体产品、具体活动来看,似乎是成立的。但是一旦具体讨论就会发现:很多场景不满足这三个假设。因此:单纯讲RFM,不结合产品、活动,是很容易出BUG的。
1.R:用户离得越久就越有流失风险
- 如果是服装这种季节性消费,用户间隔2-3个月是很正常
- 如果是手机、平板这种新品驱动产品,间隔时间基本跟着产品更新周期走
- 如果是家居、住房、汽车这种大件耐用品,R就没啥意义,用户一辈子就买2次
- 如果是预付费,后刷卡的模式,R就不存在了,需要用核销数据代替
所以R不见得就代表着用户有流失风险,特别是现在有了埋点数据以后,用户互动行为更能说明问题。
2.F:用户频次越高越忠诚
- 如果用户消费是事件驱动的,比如赛事、节假日、生日、周末……
- 如果用户消费是活动驱动的,比如啥时候有优惠啥时候买……
- 如果用户消费是固定模式的,比如买药的用量就是30天……
以上情况都会导致F的数值不固定,可能是随机产生的,也可能是人为操纵的。很多企业僵硬地执行RFM模型,往往会定一个固定的F值,比如促使用户买4次,因为数据上看买了4次以上的用户就很忠诚。结果就是引发用户人为拆单,最后F值做上去了,利润掉下来了。
3.M: 用户买的越多越有价值
- 如果用户是图便宜,趁有折扣的时候囤货呢?
- 如果用户买了一堆,已经吃腻了、用够了呢?
- 如果用户买的是耐用品,买完这一单就等十几二十年呢?
- 如果用户消费本身有生命周期,比如母婴,游戏,已经到了生命周期末尾呢?
很多情况下,用户过去买的多,不代表未来买的多。这两者不划等号。因此真看到011、001、101的客人,别急着派券,整明白到底出了啥问题才是关键。
除了单独维度的问题外,三个维度连起来看,也容易出问题。因为很多公司的用户结构不是金字塔形,而是埃菲尔铁塔型:底部聚集了太多的不活跃用户,且不活跃用户大多只有1单,或者只有几次登录便流失,因此RFM真按八分类化出来,可能000的用户比例特别多。
这意味着现有存活的用户,可能是幸存者偏差的结果,现有的111不是000的未来。要更深层次地分析为啥会沉淀大量不活跃用户,甚至从根上改变流程,才能解决问题。真按照RFM生搬硬套。可能就把业务带到死胡同里了。
四.RFM的典型乱用
RFM本身并没有错,在数据匮乏(特别是缺少埋点数据)的情况下,用RFM比不用RFM好太多了。RFM的三个维度,每一个都很好用。RFM的整体架构,也适合用于评估用户经营的整体质量。
错的,是生搬硬套RFM,不做深入分析。错的是看到买了大单的就叫爸爸,看到用户不买就急着发券的无脑做法。一味派券不但严重透支营销成本,更会培养出更多薅羊毛用户,破坏了正常经营,只为了RFM的数值好看。
特别是网上文章、网课最喜欢教的:按RFM,每个拆分成5段,分成5*5*5=125类,然后再用K均值聚类聚成5-8类的做法,更是大错特错。
- 一来,经过K均值聚类以后,连RFM原有的含义清晰的优点都没有了,到底这8类咋解读,非常混乱。
- 二来,这样做没有考虑数据滚动更新,过了一周或者一个月,RFM指标都变了呀!难道你还天天把全量用户拿出来聚类吗。
- 三来,k均值聚类不是一个稳定的分类方法,无监督的分类更适合做探索性分析。隔了一周,一个用户被分成完全不同的两类,这会让市场营销、运营策划执行政策的时候非常抓狂:一天一个样,到底要推什么!
本质上看,因为网课、网文给的都是一张清洗得完美的静态数据表,一不需要跟别的部门合作,二不需要考虑连续场景,所以才选了一个模型+算法的做法。嗯,能不能用不重要,显得自己牛逼最关键!
五.如何让RFM更有用
综合RFM失效的场景,可以看出:季节性、商品特征、促销活动、节假日事件、用户生命周期,这五大要素,都会影响到用户的行为。因此不局限于RFM,深入研究用户场景非常关键。
这五大要素研究起来,并没有想象中的难。
比如很多商品有内在的关联性,只要熟悉业务就能整明白;比如季节性、节假日事件,本质上都和时间有关。
因此,对用户登录、消费的时间打上标签,就能进行分析(如下图)。促销活动也是同理,促销活动可以直接从订单识别出来,因此也很容易给用户贴上:促销敏感型的标签。

用户生命周期,需要数据采集,而且是采集一个最关键的数据即可。最典型的用户生命周期是母婴行业做法,企业一定会采集一个最关键的数据:怀孕多少周了。这个数据爸爸们不见得清楚,妈妈们一定很清楚。知道了起点,后续就可以推算了。类似的还有药店连锁做慢病管理,K12教育等等。
六.小结
任何模型都有其产生的历史背景、数据基础、使用范围,也不是所有模型的目的都是精准。简单、好用、省事,是更多时候的考虑。
因此再次强烈建议同学们,不要沉迷于当知识收集者,企图找到《宇宙唯一真理模型》然后死记硬背,顶礼膜拜。多研究自己工作的行业特点,改造方法为我所用,才是让数据发挥更大作用的方法。
END.
作者:接地气的陈老师
来源:接地气学堂
本文已和作者授权,如需转载请与作者联系
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论