
一.初识与安装
1.安装
$ pip install openpyxl
2.一个简单创建例子
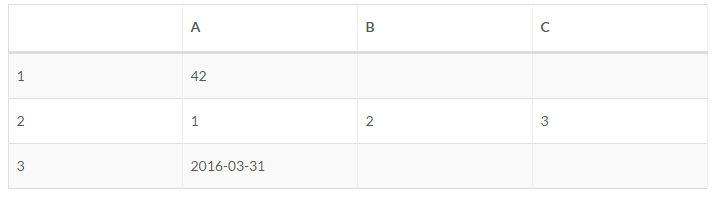
from openpyxl import Workbookwb = Workbook()# 激活 worksheetws = wb.active# 数据可以直接分配到单元格中ws[ "A1" ] = 42# 可以附加行,从第一列开始附加ws.append([ 1 , 2 , 3 ])# Python 类型会被自动转换import datetimews[ "A3" ] = datetime.datetime.now().strftime( "%Y-%m-%d" )# 保存文件wb.save( "sample.xlsx" )
打开查看Excel如下:
3.workbook
使用openpyxl无需在文件系统上创建文件,只需导入 Workbook 类并开始使用。
from openpyxl import Workbookwb = Workbook()
4.worksheet
一个workbook至少创建一个worksheet。
通过openpyxl.workbook.Workbook.active()得到worksheet.
ws = wb.active
注意:该方法使用_active_sheet_index属性, 默认会设置0,也就是第一个worksheet。除非手动修改,否则使用active方法得到都是第一个worksheet。
你也可以创建worksheets,通过 openpyxl.workbook.Workbook.create_sheet() 方法:
>>> ws1 = wb.create_sheet( "Mysheet" ) #插入到最后(default)#或者>>> ws2 = wb.create_sheet( "Mysheet" , 0) #插入到最开始的位置
创建的sheet的名称会自动创建,按照sheet,sheet1,sheet2自动增长,通过title属性可以修改其名称。
ws.title = "New Title"
默认的sheet的tab是白色的,可以通过 RRGGBB颜色来修改sheet_properties.tabColor属性从而修改sheet tab按钮的颜色:
ws.sheet_properties.tabColor = "1072BA"
当你设置了sheet的名称,可以将其看成workbook中的一个key。也可以使用openpyxl.workbook.Workbook.get_sheet_by_name() 方法
>>> ws3 = wb[ "New Title" ]>>> ws4 = wb.get_sheet_by_name( "New Title" )>>> ws is ws3 is ws4True
查看workbook中的所有worksheets名称:openpyxl.workbook.Workbook.get_sheet_names()
>>> print(wb.sheetnames)[ "Sheet2" , "New Title" , "Sheet1" ]
遍历worksheets:
>>> for sheet in wb:... print(sheet.title)
二.操作数据
1.访问单元格
单元格可以看作是worksheet的key,通过key去访问单元格中的数据
>>> c = ws[ "A4" ]
直接返回A4单元格,如果不存在则会自动创建一个。
2.指定单元格的值
>>> ws[ "A4" ] = 4 #直接赋值
使用openpyxl.worksheet.Worksheet.cell()方法操作某行某列的某个值:
>>> d = ws.cell(row=4, column=2, value=10)
注意:当worksheet在内存中被创建时,是没有包含cells的,cells是在首次访问时创建;可以循环在内存中创建cells,这时不指定他们的值也会创建该cells些:(创建100x100cells)
>>> for i in range(1,101):... for j in range(1,101):... ws.cell(row=i, column=j)
3.访问许多cells
通过切片Ranges指定许多cells
>>> cell_range = ws[ "A1" : "C2" ]
同样也可以Ranges rows 或者columns :
>>> colC = ws[ "C" ]>>> col_range = ws[ "C:D" ]>>> row10 = ws[10]>>> row_range = ws[5:10]
也可以使用 openpyxl.worksheet.Worksheet.iter_rows() 方法:
>>> for row in ws.iter_rows(min_row=1, max_col=3, max_row=2):... for cell in row:... print(cell)<Cell Sheet1.A1><Cell Sheet1.B1><Cell Sheet1.C1><Cell Sheet1.A2><Cell Sheet1.B2><Cell Sheet1.C2>
如果你需要遍历所有文件的行或列,可以使用openpyxl.worksheet.Worksheet.rows() 属性:
>>> ws = wb.active>>> ws[ "C9" ] = "hello world">>> tuple(ws.rows)((<Cell Sheet.A1>, <Cell Sheet.B1>, <Cell Sheet.C1>),(<Cell Sheet.A2>, <Cell Sheet.B2>, <Cell Sheet.C2>),(<Cell Sheet.A3>, <Cell Sheet.B3>, <Cell Sheet.C3>),(<Cell Sheet.A4>, <Cell Sheet.B4>, <Cell Sheet.C4>),(<Cell Sheet.A5>, <Cell Sheet.B5>, <Cell Sheet.C5>),(<Cell Sheet.A6>, <Cell Sheet.B6>, <Cell Sheet.C6>),(<Cell Sheet.A7>, <Cell Sheet.B7>, <Cell Sheet.C7>),(<Cell Sheet.A8>, <Cell Sheet.B8>, <Cell Sheet.C8>),(<Cell Sheet.A9>, <Cell Sheet.B9>, <Cell Sheet.C9>))
或者openpyxl.worksheet.Worksheet.columns() 属性:
>>> tuple(ws.columns)((<Cell Sheet.A1>,<Cell Sheet.A2>,<Cell Sheet.A3>,<Cell Sheet.A4>,<Cell Sheet.A5>,<Cell Sheet.A6>,...<Cell Sheet.B7>,<Cell Sheet.B8>,<Cell Sheet.B9>),(<Cell Sheet.C1>,<Cell Sheet.C2>,<Cell Sheet.C3>,<Cell Sheet.C4>,<Cell Sheet.C5>,<Cell Sheet.C6>,<Cell Sheet.C7>,<Cell Sheet.C8>,<Cell Sheet.C9>))
4.保存文件
最简单最安全的方法保存workbook是使用openpyxl.workbook.Workbook对象的 openpyxl.workbook.Workbook.save()方法:
>>> wb = Workbook()>>> wb.save( "balances.xlsx" )
保存的默认位置在python的根目录下。
注意:会自动覆盖已经存在文件名的文件。
5.从文件中导入
像写一样我们可以导入openpyxl.load_workbook()已经存在的workbook:
>>> from openpyxl import load_workbook>>> wb2 = load_workbook( "test.xlsx" )>>> print wb2.get_sheet_names()[ "Sheet2" , "New Title" , "Sheet1" ]
三.常用实例
详情参考官方使用文档:
http://openpyxl.readthedocs.io/en/default/usage.html
1.写入例子一
#!/usr/bin/env python # -*- coding: utf-8 -*-from openpyxl import Workbookwb = Workbook()# 激活 worksheetws = wb.active# 数据可以直接分配到单元格中ws[ "A1" ] = 42# 可以附加行,从第一列开始附加ws.append([ 1 , 2 , 3 ])# Python 类型会被自动转换import datetimews[ "A3" ] = datetime.datetime.now().strftime( "%Y-%m-%d" )# 保存文件wb.save( "sample.xlsx" )
2.写入例子二
#!/usr/bin/env python # -*- coding: utf-8 -*-"""http://openpyxl.readthedocs.io/en/default/usage.html"""# workbook相关from openpyxl import Workbookfrom openpyxl.compat import rangefrom openpyxl.utils import get_column_letterwb = Workbook()dest_filename = "empty_book.xlsx"ws1 = wb.activews1.title = "range names"for row in range ( 1 , 40 ): ws1.append( range ( 600 ))ws2 = wb.create_sheet(title = "Pi" )ws2[ "F5" ] = 3.14ws3 = wb.create_sheet(title = "Data" )for row in range ( 10 , 20 ): for col in range ( 27 , 54 ): _ = ws3.cell(column = col, row = row, value = "{0}" . format (get_column_letter(col)))print (ws3[ "AA10" ].value)wb.save(filename = dest_filename)
3.读取例子一

#!/usr/bin/env python # -*- coding: utf-8 -*-from openpyxl.reader.excel import load_workbookimport json# 读取excel2007文件wb = load_workbook(filename=r"test_book.xlsx")# 显示有多少张表print "Worksheet range(s):", wb.get_named_ranges()print "Worksheet name(s):", wb.get_sheet_names()# 取第一张表sheetnames = wb.get_sheet_names()ws = wb.get_sheet_by_name(sheetnames[0])# 显示表名,表行数,表列数print "Work Sheet Titile:", ws.titleprint "Work Sheet Rows:", ws.max_rowprint "Work Sheet Cols:", ws.max_column# 建立存储数据的字典data_dic = {}# 把数据存到字典中for rx in range(1, ws.max_row + 1): temp_list = [] pid = rx w1 = ws.cell(row=rx, column=1).value w2 = ws.cell(row=rx, column=2).value w3 = ws.cell(row=rx, column=3).value w4 = ws.cell(row=rx, column=4).value temp_list = [w1, w2, w3, w4] data_dic[pid] = temp_list# 打印字典数据个数print "Total:%d" % len(data_dic)print json.dumps(data_dic, encoding="UTF-8", ensure_ascii=False)
读取结果:
Worksheet range(s): []Worksheet name(s): [u "u6d3bu52a8u8868" , u "u7528u6237u4fe1u606f" , u "Sheet3" ]Work Sheet Titile: 活动表Work Sheet Rows: 3Work Sheet Cols: 5Total:3{ "1" : [ "张三" , 18, "男" , "广州" ], "2" : [ "李四" , 20, "女" , "湖北" ], "3" : [ "王五" , 25, "女" , "北京" ]}
4.使用公式
>>> from openpyxl import Workbook>>> wb = Workbook()>>> ws = wb.active>>> # add a simple formula>>> ws[ "A1" ] = "=SUM(1, 1)">>> wb.save( "formula.xlsx" )
END.
作者:FanLei_Data
来源:CSDN
本文为转载分享,若侵权请联系后台删除
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论