
场景描述
- 统计前 N 天的销售额的平均值。
- 统计 TOP N 商品
- 随机分组
统计前 N 天的销售额的平均值
基础知识
我们本次使用到的 sql 都是在 presto 上跑的,如果想在 hive 或者 其他平台上跑的话,请自行将 sql 转成对应的 sql 。
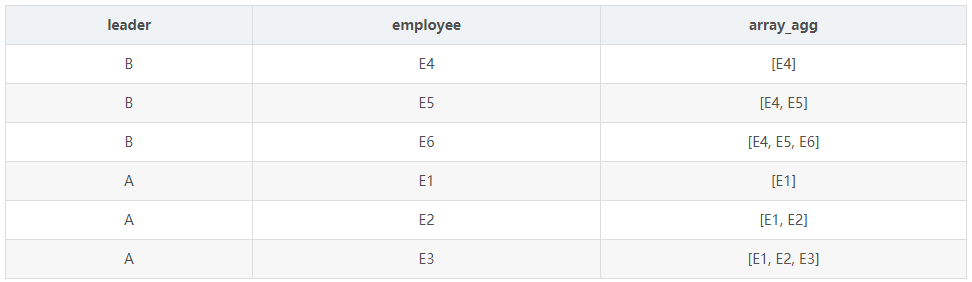
首先看一下,array_agg() over() 函数。
select leader , employee , array_agg(employee) over(partition by leader order by employee) from ( select "A" as leader , "E1" as employeeunion all select "A" as leader , "E2" as employeeunion all select "A" as leader , "E3" as employeeunion all select "B" as leader , "E4" as employeeunion all select "B" as leader , "E5" as employeeunion all select "B" as leader , "E6" as employee ) as a
计算结果如下所示:
接下来是几个简单的函数:
- reverse,按照字典顺序或者数字的顺序对数字排序
- slice:取出数组的子集,例如, slice(array,start_index, end_index)
为了更加形象的说明问题,我们使用的下面的例子进行说明。
select sale_date , shop_id , array_agg(ARRAY[sale_date , shop_id , cast(sale_amt as varchar)]) over(partition by shop_id order by sale_date) from ( select "2019-06-06" as sale_date , "shop1" as shop_id , 10 as sale_amt union all select "2019-06-05" as sale_date , "shop1" as shop_id , 14 as sale_amt union all select "2019-06-03" as sale_date , "shop1" as shop_id , 17 as sale_amt union all select "2019-06-02" as sale_date , "shop1" as shop_id , 18 as sale_amt union all select "2019-06-01" as sale_date , "shop1" as shop_id , 13 as sale_amt union all select "2019-06-06" as sale_date , "shop2" as shop_id , 11 as sale_amt union all select "2019-06-05" as sale_date , "shop2" as shop_id , 15 as sale_amt union all select "2019-06-03" as sale_date , "shop2" as shop_id , 18 as sale_amt union all select "2019-06-02" as sale_date , "shop2" as shop_id , 19 as sale_amt union all select "2019-06-01" as sale_date , "shop2" as shop_id , 16 as sale_amt ) as a
上面这段 sql 的结果如下所示:
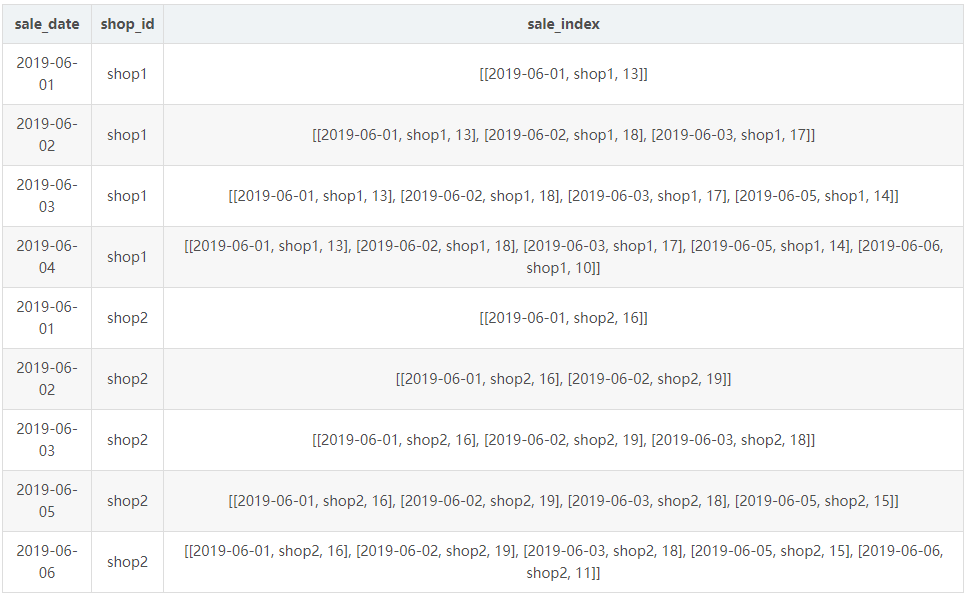
请注意观察数组里面的数字。我们可以观察到已经是排好序了。但是我们需要的是倒序。这是个问题。
另外,我只想取出前 3 天的数据汇总,所以我们需要取 array 的子集。这是个问题。
然后我们还会遇到一个问题,如果日期不连续的话,例如,shop2 在 2019-06-04 没有数据,所以我们需要对数组里面的元素进行过滤。
过滤之后我们需要单独把数组里的销售额拿出来相加。
排序我们可以使用 reverse 函数,slice 函数取数组的子集,filter(array, lamabda) 过滤出我们需要的元素,然后使用 reduce 把销售额加起来。
这里使用到的 reduce 在官网上没有讲到,reduce(array,cast(ROW(0,0.00) as ROW(cnt int,amt doubel)), (x,y) ->cast( as ROW(cnt int , amt double)) , s -> s )
这些都是在数组上的操作详细的可以查看:https://prestodb.github.io/docs/current/functions/array.html
这里先弄清楚 filter 和 reduce 的功能特性。
select cast(reduce(filter(ARRAY[1,2,3,4,5],x -> x >= 4),cast(ROW(0) as ROW(cnt int)), (x,y) ->cast( ROW(y + x.cnt) as ROW(cnt int ) ), x -> x ) as json) as rs
其中, filter(array,filterFunction(x)): 第一个参数的是要操作的数组,第二个是 filter 的条件,这里是一个正则表达式。
reduce(array,initialState , inputFunction(S, T, S), outputFunction(S, R))
最终的结果
在了解完 array 的几个函数以后,我可以得到如下所示的结果
最终的结果为:
select sale_date , shop_id , sale_pre3 , json_array_get(cast(reduce(filter(array_amt,x -> x[1] >= sale_pre3),cast(ROW(0) as ROW(cnt int)), (x,y) ->cast( ROW(cast(y[3] as integer) + x.cnt) as ROW(cnt int ) ), x -> x ) as json),0) as rs from (select sale_date , shop_id , cast(date_add("day",-2,date(sale_date)) as varchar) as sale_pre3 , array_agg(ARRAY[sale_date , shop_id , cast(sale_amt as varchar)]) over(partition by shop_id order by sale_date) as array_amt from ( select "2019-06-06" as sale_date , "shop1" as shop_id , 10 as sale_amt union all select "2019-06-05" as sale_date , "shop1" as shop_id , 14 as sale_amt union all select "2019-06-03" as sale_date , "shop1" as shop_id , 17 as sale_amt union all select "2019-06-02" as sale_date , "shop1" as shop_id , 18 as sale_amt union all select "2019-06-01" as sale_date , "shop1" as shop_id , 13 as sale_amt union all select "2019-06-06" as sale_date , "shop2" as shop_id , 11 as sale_amt union all select "2019-06-05" as sale_date , "shop2" as shop_id , 15 as sale_amt union all select "2019-06-03" as sale_date , "shop2" as shop_id , 18 as sale_amt union all select "2019-06-02" as sale_date , "shop2" as shop_id , 19 as sale_amt union all select "2019-06-01" as sale_date , "shop2" as shop_id , 16 as sale_amt ) as a ) as b
其中,json_array_get(json_str,index) 函数是将 json_str 转成 json_object,然后取出第一个数组。
其实我们也可以使用 lag 或者 leader 函数来实现这个功能。最终的解决结果如下所示:
select sale_date , shop_id , ( sale_amt +if(_last_3_day < last_1_day,last_1_amt,0) +if(_last_3_day < last_2_day,last_1_amt,0) +if(_last_3_day < last_3_day,last_1_amt,0) ) as last_3_amt_sum from ( select sale_date , shop_id , sale_amt , cast(date(date_add("day" , cast(-3 as bigint) , cast (sale_date as timestamp))) as varchar) as _last_3_day , lag(sale_amt,1) over(partition by shop_id order by sale_date) as last_1_amt , lag(sale_date,1) over(partition by shop_id order by sale_date) as last_1_day , lag(sale_amt,2) over(partition by shop_id order by sale_date) as last_2_amt , lag(sale_date,2) over(partition by shop_id order by sale_date) as last_2_day , lag(sale_amt,3) over(partition by shop_id order by sale_date) as last_3_amt , lag(sale_date,3) over(partition by shop_id order by sale_date) as last_3_day from ( select "2019-06-06" as sale_date , "shop1" as shop_id , 10 as sale_amt union all select "2019-06-05" as sale_date , "shop1" as shop_id , 14 as sale_amt union all select "2019-06-03" as sale_date , "shop1" as shop_id , 17 as sale_amt union all select "2019-06-02" as sale_date , "shop1" as shop_id , 18 as sale_amt union all select "2019-06-01" as sale_date , "shop1" as shop_id , 13 as sale_amt union all select "2019-06-06" as sale_date , "shop2" as shop_id , 11 as sale_amt union all select "2019-06-05" as sale_date , "shop2" as shop_id , 15 as sale_amt union all select "2019-06-03" as sale_date , "shop2" as shop_id , 18 as sale_amt union all select "2019-06-02" as sale_date , "shop2" as shop_id , 19 as sale_amt union all select "2019-06-01" as sale_date , "shop2" as shop_id , 16 as sale_amt ) as a) as aa
动态 TOP N
先说动态 TOP N 问题之前我们先了认识一下 TOP N 。
TOP N 是什么呢?让我们先闪回到学生时代,那时在期末考试结束后校长说学生们辛苦了,要有奖励,于是就有了奖励。教务处的老师们经过一番思考之后,制定了一系列的奖励政策,其中之一是每个班级总成绩前 10 名的学生发一本《三体》回去研读。如果你是教务处的老师,应该取出这批学生呢? 其实有点 SQL 基础的人都应该有一些思路了。如下所示:
select stu_name , class , score from ( select stu_name , class , score , row_number() over(partition by class order by score desc) as student_ranking from ( select "a" as stu_name, "C1" as class 213 as score union all select "b" as stu_name, "C1" as class 223 as score union all select "c" as stu_name, "C1" as class 223 as score union all select "d" as stu_name, "C1" as class 223 as score union all select "e" as stu_name, "C1" as class 223 as score union all select "g" as stu_name, "C2" as class 213 as score union all select "h" as stu_name, "C2" as class 223 as score union all select "m" as stu_name, "C2" as class 223 as score union all select "n" as stu_name, "C2" as class 223 as score union all select "i" as stu_name, "C2" as class 223 as score ) as school_report_card) as school_report_card1where student_ranking <= 10
但是呢,有的班主任提出了不同的观点,有的我们人多,只奖励 10 个人太少了,要按照每个班级人数的 10% 奖励。好像还挺有道理的。
那么这有改怎么写呢?
借用周星驰的经典台词"你让我打狗,总得给我一个棒子啊",我们首先要知道每个班的总人数。
select "C1" as class , 40 as populationunion all select "C2" as class , 50 as population
那么我们的 SQL 重新写成:
select stu_name , class , score , student_ranking from ( select stu_name , class , score , row_number() over(partition by class order by score desc) as student_ranking from ( select "a" as stu_name, "C1" as class ,213 as score union all select "b" as stu_name, "C1" as class ,223 as score union all select "c" as stu_name, "C1" as class ,223 as score union all select "d" as stu_name, "C1" as class ,223 as score union all select "e" as stu_name, "C1" as class ,223 as score union all select "g" as stu_name, "C2" as class ,213 as score union all select "h" as stu_name, "C2" as class ,223 as score union all select "m" as stu_name, "C2" as class ,223 as score union all select "n" as stu_name, "C2" as class ,223 as score union all select "i" as stu_name, "C2" as class ,223 as score ) as school_report_card ) as school_report_card1left join ( select "C1" as class , 40 as populationunion all select "C2" as class , 50 as population) as class_populationon school_report_card1.class = class_population.classwhere student_ranking <= population*0.1
上面使用到的数组,那么我们能不能也使用数组呢?答案是肯定的.
不知道你使用过没有 clickhouse ,下面来结束一下如何使用 clickhouse 做动态 TOP N 。
clickhouse 没有像 presto 那样开窗函数,所以只能使用数组进行处理了。
首先,来看看关于数组的几个基本的函数
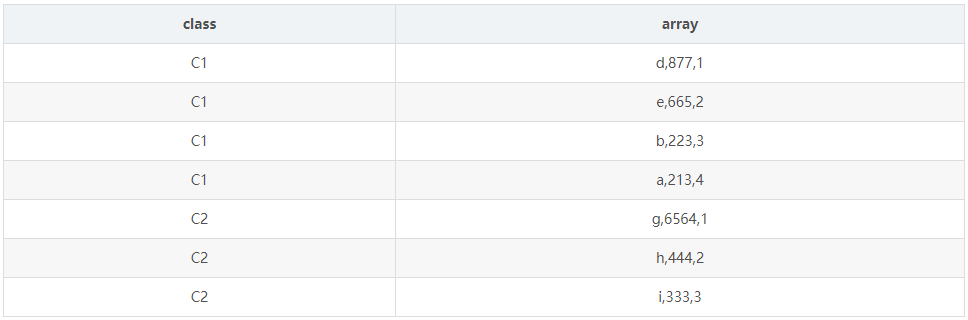
select class , groupArray(4)([stu_name , cast(score as String)]) from ( select "a" as stu_name, "C1" as class ,213 as scoreunion all select "b" as stu_name, "C1" as class ,223 as scoreunion all select "c" as stu_name, "C1" as class ,212 as scoreunion all select "d" as stu_name, "C1" as class ,877 as scoreunion all select "e" as stu_name, "C1" as class ,665 as scoreunion all select "g" as stu_name, "C2" as class ,6564 as scoreunion all select "h" as stu_name, "C2" as class ,444 as scoreunion all select "m" as stu_name, "C2" as class ,111 as scoreunion all select "n" as stu_name, "C2" as class ,222 as scoreunion all select "i" as stu_name, "C2" as class ,333 as score )group by class
结果如下所示:

由上面的结果可以看到 groupArray(record element) 的功能是和 presto 的 array_agg() 的
功能差不多。就是把分组内的每个元素汇总放到一个数组里面。
接下来看一下,看下一个重要的函数:arrayResize 。
select class , arrayResize(a.array_group , b.population) as resized_array_group from ( select class , groupArray(4)([stu_name , cast(score as String)]) as array_group from ( select "a" as stu_name, "C1" as class ,213 as score union all select "b" as stu_name, "C1" as class ,223 as score union all select "c" as stu_name, "C1" as class ,212 as score union all select "d" as stu_name, "C1" as class ,877 as score union all select "e" as stu_name, "C1" as class ,665 as score union all select "g" as stu_name, "C2" as class ,6564 as score union all select "h" as stu_name, "C2" as class ,444 as score union all select "m" as stu_name, "C2" as class ,111 as score union all select "n" as stu_name, "C2" as class ,222 as score union all select "i" as stu_name, "C2" as class ,333 as score ) group by class ) as a allleft join ( select "C1" as class , 4 as populationunion all select "C2" as class , 3 as population) as b on a.class = b.class
结果为:

由例子我们知道 resize(array,new_size) 的功能就是重新设置数组的大小,如果 new_size > old_size 那么可以 ‘’ 或者 0 填充数组。
如果 new_size < old_size 则会将尾部的几个元素删除掉。
然后是 arrayJoin 此函数和 arrayConcat 看起来一样,但是其实差别特别的大。
arrayJoin 是将数组中的元素 split 放到列上,功能有点类似 hive 的 LATERAL VIEW 函数。
还有一个函数 indexOf(element,array),这个函数是将 element 在 array 中的位置返回,这样我们就可以得到成绩的排名。
select aa.class ,arrayConcat(joined_array ,[toString(element_index)] ) from ( select class , arrayJoin(arrayResize(a.array_group , b.population)) as joined_array , indexOf(arrayResize(a.array_group , b.population) ,arrayJoin(arrayResize(a.array_group , b.population))) as element_index from ( select class , groupArray(4)([stu_name , cast(score as String)]) as array_group from ( select * from ( select "a" as stu_name, "C1" as class ,213 as score union all select "b" as stu_name, "C1" as class ,223 as score union all select "c" as stu_name, "C1" as class ,212 as score union all select "d" as stu_name, "C1" as class ,877 as score union all select "e" as stu_name, "C1" as class ,665 as score union all select "g" as stu_name, "C2" as class ,6564 as score union all select "h" as stu_name, "C2" as class ,444 as score union all select "m" as stu_name, "C2" as class ,111 as score union all select "n" as stu_name, "C2" as class ,222 as score union all select "i" as stu_name, "C2" as class ,333 as score ) as aa order by class , score desc ) group by class ) as a all left join ( select "C1" as class , 4 as population union all select "C2" as class , 3 as population ) as b on a.class = b.class) as aa
后面就好说吧,使用 arrayJoin 展开使用数组的下标展示出不同的字段就可以了。
所以最后的结果是:
select class ,arry[1] as stu_name ,arry[2] as score ,arry[3] as student_ranking from ( select aa.class ,arrayConcat(joined_array ,[toString(element_index)] ) as arry from ( select class , arrayJoin(arrayResize(a.array_group , b.population)) as joined_array , indexOf(arrayResize(a.array_group , b.population) ,arrayJoin(arrayResize(a.array_group , b.population))) as element_index from ( select class , groupArray(4)([stu_name , cast(score as String)]) as array_group from ( select * from ( select "a" as stu_name, "C1" as class ,213 as score union all select "b" as stu_name, "C1" as class ,223 as score union all select "c" as stu_name, "C1" as class ,212 as score union all select "d" as stu_name, "C1" as class ,877 as score union all select "e" as stu_name, "C1" as class ,665 as score union all select "g" as stu_name, "C2" as class ,6564 as score union all select "h" as stu_name, "C2" as class ,444 as score union all select "m" as stu_name, "C2" as class ,111 as score union all select "n" as stu_name, "C2" as class ,222 as score union all select "i" as stu_name, "C2" as class ,333 as score ) as aa order by class , score desc ) group by class ) as a all left join ( select "C1" as class , 4 as population union all select "C2" as class , 3 as population ) as b on a.class = b.class ) as aa ) as aaa


随机分组
随机分组的问题是这样的,如果我们 100 名学生成绩都差不多,那么我们可以随机的分到两个班级里面去。
select stu_name ,case when group_index = 1 then "C1" when group_index = 2 then "C2" else "none" end as class from ( select stu_name ,(index + max_index/2 -1)/(max_index/2) as group_index from (select stu_name ,index ,(max(index) over()) as max_index from ( select * from ( select stu_name ,row_number() over() as index from ( select "a" as stu_name union all select "b" as stu_name union all select "c" as stu_name union all select "d" as stu_name union all select "e" as stu_name union all select "f" as stu_name ) ) as a ) as aa ) as aaa ) as aaaa
需要注意的是我们这个例子对于总人数是偶数的时候是有效的,但是奇数的时候就会有问题,那些人特殊处理一下就可以了
例如,
a、b、c、d、e做取商操作的时候,得到 (1 + 2 -1)/2 = 1 、 (2 + 2 -1)/2 = 1、 (2 + 3 -1)/2 = 2、 (2 + 4 -1)/2 = 2、 (2 + 5 -1)/2 = 3我们发现,5 会分到 3 里面,所以如果总人数是奇数的时候,需要对余出来的几行记录做一下特殊处理。
还可以使用取模的办法来分组。请看下面的公式。
group=index%goup_size
% 是取于操作,举个例子:
1,2,3,4,5,6,7,8,9,102 取模后:1,0,1,0,1,0,1,0,1,03 取模后:1,2,0,1,2,0,1,2,0,1
所以 sql 可以改造成:
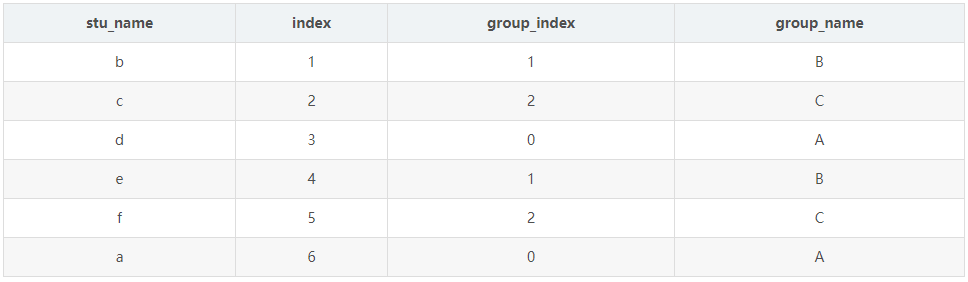
select stu_name ,index ,index%3 ,substring("ABC",1+index%3,1) as group_index from( select stu_name ,row_number() over() as index from ( select "a" as stu_name union all select "b" as stu_name union all select "c" as stu_name union all select "d" as stu_name union all select "e" as stu_name union all select "f" as stu_name ) ) order by index
结果:
如何形成周期性的序列
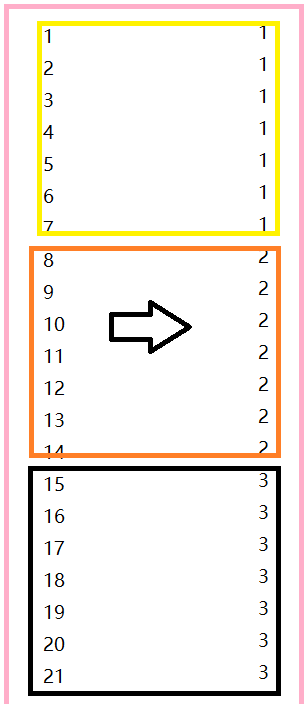
其中,interval = 7 ,每隔 7 个数字的分成了一个组。
select (index + interval -1 )/interval , index from ( select dim_date_id ,max(index) over() as max_index ,index from ( select dim_date_id ,row_number() over() as index from dim.dim_date where dim_date_id between "20190701" and "20190721" ))
End.爱数据网专栏作者:wang-possible作者介绍:6年零售大数据工作经验,技能持续精进CSDN个人主页:bluedraam_pp
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论