

一、创建数据集
from pyspark.sql import SprkSessionimport pandas as pdspark = SparkSession.builder.appName("Windowfunction").enableHiveSupport().getOrCreate()import pyspark.sql.functions # 原始数据 test = spark.createDataFrame([("001","1",100,87,67,83,98), ("002","2",87,81,90,83,83), ("003","3",86,91,83,89,63), ("004","2",65,87,94,73,88), ("005","1",76,62,89,81,98), ("006","3",84,82,85,73,99), ("007","3",56,76,63,72,87), ("008","1",55,62,46,78,71), ("009","2",63,72,87,98,64)], ["number","class","language","math","english","physic","chemical"])#查看原始数据test.show()#将原始数据存入中间表test.createOrReplaceTempView("test_temp_table")number|class|language|math|english|physic|chemical|+------+-----+--------+----+-------+------+--------+| 001| 1| 100| 87| 67| 83| 98|| 002| 2| 87| 81| 90| 83| 83|| 003| 3| 86| 91| 83| 89| 63|| 004| 2| 65| 87| 94| 73| 88|| 005| 1| 76| 62| 89| 81| 98|| 006| 3| 84| 82| 85| 73| 99|| 007| 3| 56| 76| 63| 72| 87|| 008| 1| 55| 62| 46| 78| 71|| 009| 2| 63| 72| 87| 98| 64|+------+-----+--------+----+-------+------+--------+#将数据转换为长数据# 逆透视Unpivottest_long =test.selectExpr("`number`","`class`", "stack(5, "language", `language`,"math", `math`, "english", `english`, "physic", `physic`,"chemical", `chemical`) as (`subject`,`grade`)").orderBy(["`class`", "`number`"]) test_long.show()test_long.createOrReplaceTempView("test_long_temp_table")+------+-----+--------+-----+|number|class| subject|grade|+------+-----+--------+-----+| 001| 1| english| 67|| 001| 1|language| 100|| 001| 1| physic| 83|| 001| 1| math| 87|| 001| 1|chemical| 98|| 005| 1|chemical| 98|| 005| 1| english| 89|| 005| 1| physic| 81|| 005| 1| math| 62|| 005| 1|language| 76|| 008| 1| physic| 78|| 008| 1| math| 62|| 008| 1|chemical| 71|| 008| 1|language| 55|| 008| 1| english| 46|| 002| 2|language| 87|| 002| 2| math| 81|| 002| 2| physic| 83|| 002| 2|chemical| 83|| 002| 2| english| 90|+------+-----+--------+-----+only showing top 20 rows二、聚合函数
聚合函数也可用于窗口函数当中,用法和专用窗口函数相同。
聚合函数sum、avg、count、max、min都是针对自身记录以及自身记录以上的所有数据进行计算的。
聚合函数作为窗口函数,可以在每一行的数据里直观看到截止到本行数据,统计数据是多少,比如:按照时间的顺序,计算各时期的销售总额就需要用到这种累计的统计方法。同时也可以看出每一行数据对整体数据的影响。聚合函数的开窗和专用的窗口函数是一致的,其形式为:
‹窗口函数› over (partition by ‹用于分组的列名› order by ‹用于排序的列名›)
聚合函数的窗口函数中,加不加order by,order by的列名是否是用于分组的列名,这些情况都会影响到最终的结果,下面我们分别来讨论各种不同的情况。
2.1 窗口函数有无order by的区别
2.1.1 有order by且order by的字段不是用于分组的字段
这种情况下得到的结果是每个partition的累加的结果
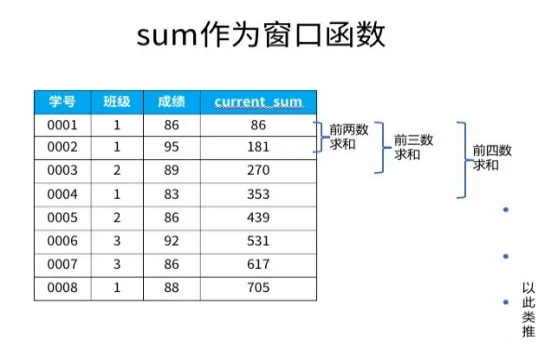
test_sum=spark.sql("""select *,sum(grade)over(partition by class,subject order by number) total_grade,avg(grade)over(partition by subject,class order by number) avg_grade,count(grade)over(partition by subject,class order by number) total_classmate,max(grade)over(partition by subject,class order by number) max_grade,min(grade)over(partition by subject,class order by number) min_gradefrom test_long_temp_table""")test_sum.show()number|class| subject|grade|total_grade| avg_grade|total_classmate|max_grade|min_grade|+------+-----+--------+-----+-----------+-----------------+---------------+---------+---------+| 001| 1| english| 67| 67| 67.0| 1| 67| 67|| 005| 1| english| 89| 156| 78.0| 2| 89| 67|| 008| 1| english| 46| 202|67.33333333333333| 3| 89| 46|| 002| 2| english| 90| 90| 90.0| 1| 90| 90|| 004| 2| english| 94| 184| 92.0| 2| 94| 90|| 009| 2| english| 87| 271|90.33333333333333| 3| 94| 87|| 003| 3|chemical| 63| 63| 63.0| 1| 63| 63|| 006| 3|chemical| 99| 162| 81.0| 2| 99| 63|| 007| 3|chemical| 87| 249| 83.0| 3| 99| 63|| 003| 3| math| 91| 91| 91.0| 1| 91| 91|| 006| 3| math| 82| 173| 86.5| 2| 91| 82|| 007| 3| math| 76| 249| 83.0| 3| 91| 76|| 001| 1| math| 87| 87| 87.0| 1| 87| 87|| 005| 1| math| 62| 149| 74.5| 2| 87| 62|| 008| 1| math| 62| 211|70.33333333333333| 3| 87| 62|| 002| 2| math| 81| 81| 81.0| 1| 81| 81|| 004| 2| math| 87| 168| 84.0| 2| 87| 81|| 009| 2| math| 72| 240| 80.0| 3| 87| 72|| 003| 3| physic| 89| 89| 89.0| 1| 89| 89|| 006| 3| physic| 73| 162| 81.0| 2| 89| 73|+------+-----+--------+-----+-----------+-----------------+---------------+---------+---------+only showing top 20 rows2.1.2 有order by且order by的字段是用于分组的字段
该情况下得到的数据是每个partition的总和而不是累加
test_sum_1=spark.sql("""select *,sum(grade)over(partition by subject,class order by class) total_grade,avg(grade)over(partition by subject,class order by class) avg_grade,count(grade)over(partition by subject,class order by class) total_classmate,max(grade)over(partition by subject,class order by class) max_grade,min(grade)over(partition by subject,class order by class) min_gradefrom test_long_temp_table""")test_sum_1.show()number|class| subject|grade|total_grade| avg_grade|total_classmate|max_grade|min_grade|+------+-----+--------+-----+-----------+-----------------+---------------+---------+---------+| 003| 3| physic| 89| 234| 78.0| 3| 89| 72|| 006| 3| physic| 73| 234| 78.0| 3| 89| 72|| 007| 3| physic| 72| 234| 78.0| 3| 89| 72|| 002| 2| physic| 83| 254|84.66666666666667| 3| 98| 73|| 004| 2| physic| 73| 254|84.66666666666667| 3| 98| 73|| 009| 2| physic| 98| 254|84.66666666666667| 3| 98| 73|| 003| 3|chemical| 63| 249| 83.0| 3| 99| 63|| 006| 3|chemical| 99| 249| 83.0| 3| 99| 63|| 007| 3|chemical| 87| 249| 83.0| 3| 99| 63|| 003| 3| math| 91| 249| 83.0| 3| 91| 76|| 006| 3| math| 82| 249| 83.0| 3| 91| 76|| 007| 3| math| 76| 249| 83.0| 3| 91| 76|| 001| 1| english| 67| 202|67.33333333333333| 3| 89| 46|| 005| 1| english| 89| 202|67.33333333333333| 3| 89| 46|| 008| 1| english| 46| 202|67.33333333333333| 3| 89| 46|| 002| 2| math| 81| 240| 80.0| 3| 87| 72|| 004| 2| math| 87| 240| 80.0| 3| 87| 72|| 009| 2| math| 72| 240| 80.0| 3| 87| 72|| 002| 2|language| 87| 215|71.66666666666667| 3| 87| 63|| 004| 2|language| 65| 215|71.66666666666667| 3| 87| 63|+------+-----+--------+-----+-----------+-----------------+---------------+---------+---------+only showing top 20 rows2.1.3 有partition by无order by
该情况下,sum()over()得到的数据是每个partition的总和而不是累加,和第二种情况是一致的。
test_sum_2=spark.sql("""select *,sum(grade)over(partition by subject,class) total_grade,avg(grade)over(partition by subject,class) avg_grade,count(grade)over(partition by subject,class) total_classmate,max(grade)over(partition by subject,class ) max_grade,min(grade)over(partition by subject,class) min_gradefrom test_long_temp_table""")test_sum_2.show()number|class| subject|grade|total_grade| avg_grade|total_classmate|max_grade|min_grade|+------+-----+--------+-----+-----------+-----------------+---------------+---------+---------+| 003| 3| physic| 89| 234| 78.0| 3| 89| 72|| 006| 3| physic| 73| 234| 78.0| 3| 89| 72|| 007| 3| physic| 72| 234| 78.0| 3| 89| 72|| 002| 2| physic| 83| 254|84.66666666666667| 3| 98| 73|| 004| 2| physic| 73| 254|84.66666666666667| 3| 98| 73|| 009| 2| physic| 98| 254|84.66666666666667| 3| 98| 73|| 003| 3|chemical| 63| 249| 83.0| 3| 99| 63|| 006| 3|chemical| 99| 249| 83.0| 3| 99| 63|| 007| 3|chemical| 87| 249| 83.0| 3| 99| 63|| 003| 3| math| 91| 249| 83.0| 3| 91| 76|| 006| 3| math| 82| 249| 83.0| 3| 91| 76|| 007| 3| math| 76| 249| 83.0| 3| 91| 76|| 001| 1| english| 67| 202|67.33333333333333| 3| 89| 46|| 005| 1| english| 89| 202|67.33333333333333| 3| 89| 46|| 008| 1| english| 46| 202|67.33333333333333| 3| 89| 46|| 002| 2| math| 81| 240| 80.0| 3| 87| 72|| 004| 2| math| 87| 240| 80.0| 3| 87| 72|| 009| 2| math| 72| 240| 80.0| 3| 87| 72|| 002| 2|language| 87| 215|71.66666666666667| 3| 87| 63|| 004| 2|language| 65| 215|71.66666666666667| 3| 87| 63|+------+-----+--------+-----+-----------+-----------------+---------------+---------+---------+only showing top 20 rows2.2 窗口函数的平均移动
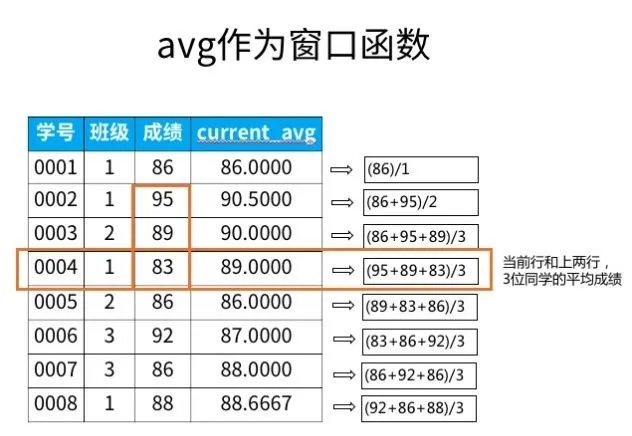
select *, avg(成绩) over (order by 学号 rows 2 preceding) as current_avg from 班级表;
rows和preceding这两个关键字,是"之前~行"的意思,上面的句子中,是之前2行。也就是得到的结果是自身记录及前2行的平均(相对应的preceding是following)
test_preceding=spark.sql("""select *,sum(grade)over(partition by subject order by number rows 2 preceding) total_preceding_gradefrom test_long_temp_table""")test_preceding.show()number|class| subject|grade|total_preceding_grade|+------+-----+--------+-----+---------------------+| 001| 1| physic| 83| 83|| 002| 2| physic| 83| 166|| 003| 3| physic| 89| 255|| 004| 2| physic| 73| 245|| 005| 1| physic| 81| 243|| 006| 3| physic| 73| 227|| 007| 3| physic| 72| 226|| 008| 1| physic| 78| 223|| 009| 2| physic| 98| 248|| 001| 1|chemical| 98| 98|| 002| 2|chemical| 83| 181|| 003| 3|chemical| 63| 244|| 004| 2|chemical| 88| 234|| 005| 1|chemical| 98| 249|| 006| 3|chemical| 99| 285|| 007| 3|chemical| 87| 284|| 008| 1|chemical| 71| 257|| 009| 2|chemical| 64| 222|| 001| 1|language| 100| 100|| 002| 2|language| 87| 187|+------+-----+--------+-----+---------------------+only showing top 20 rows
三、专用窗口函数
专用窗口函数包括rank() over,dense_rank() over,row_number() over()
1.rank() over
查出指定条件后的进行排名。特点是,加入是对学生排名,使用这个函数,成绩相同的两名是并列,下一位同学空出所占的名次。
test_rank=spark.sql("""select *,rank()over(partition by subject order by grade desc) rankfrom test_long_temp_table""")test_rank.show()number|class| subject|grade|rank|+------+-----+--------+-----+----+| 009| 2| physic| 98| 1|| 003| 3| physic| 89| 2|| 001| 1| physic| 83| 3|| 002| 2| physic| 83| 3|| 005| 1| physic| 81| 5|| 008| 1| physic| 78| 6|| 004| 2| physic| 73| 7|| 006| 3| physic| 73| 7|| 007| 3| physic| 72| 9|| 006| 3|chemical| 99| 1|| 001| 1|chemical| 98| 2|| 005| 1|chemical| 98| 2|| 004| 2|chemical| 88| 4|| 007| 3|chemical| 87| 5|| 002| 2|chemical| 83| 6|| 008| 1|chemical| 71| 7|| 009| 2|chemical| 64| 8|| 003| 3|chemical| 63| 9|| 001| 1|language| 100| 1|| 002| 2|language| 87| 2|+------+-----+--------+-----+----+only showing top 20 rows2.dense_rank() over
与rank() over的区别是,两名学生的成绩并列以后,下一位同学并不空出所占的名次。
test_dense_rank=spark.sql("""select *,dense_rank()over(partition by subject order by grade desc) rankfrom test_long_temp_table""")test_dense_rank.show()number|class| subject|grade|rank|+------+-----+--------+-----+----+| 009| 2| physic| 98| 1|| 003| 3| physic| 89| 2|| 001| 1| physic| 83| 3|| 002| 2| physic| 83| 3|| 005| 1| physic| 81| 4|| 008| 1| physic| 78| 5|| 004| 2| physic| 73| 6|| 006| 3| physic| 73| 6|| 007| 3| physic| 72| 7|| 006| 3|chemical| 99| 1|| 001| 1|chemical| 98| 2|| 005| 1|chemical| 98| 2|| 004| 2|chemical| 88| 3|| 007| 3|chemical| 87| 4|| 002| 2|chemical| 83| 5|| 008| 1|chemical| 71| 6|| 009| 2|chemical| 64| 7|| 003| 3|chemical| 63| 8|| 001| 1|language| 100| 1|| 002| 2|language| 87| 2|+------+-----+--------+-----+----+only showing top 20 rows3.row_number() over
这个函数不需要考虑是否并列,哪怕根据条件查询出来的数值相同也会进行连续排名!
test_row_number=spark.sql("""select *,row_number()over(partition by subject order by grade desc) rankfrom test_long_temp_table""")test_row_number.show()number|class| subject|grade|rank|+------+-----+--------+-----+----+| 009| 2| physic| 98| 1|| 003| 3| physic| 89| 2|| 001| 1| physic| 83| 3|| 002| 2| physic| 83| 4|| 005| 1| physic| 81| 5|| 008| 1| physic| 78| 6|| 006| 3| physic| 73| 7|| 004| 2| physic| 73| 8|| 007| 3| physic| 72| 9|| 006| 3|chemical| 99| 1|| 005| 1|chemical| 98| 2|| 001| 1|chemical| 98| 3|| 004| 2|chemical| 88| 4|| 007| 3|chemical| 87| 5|| 002| 2|chemical| 83| 6|| 008| 1|chemical| 71| 7|| 009| 2|chemical| 64| 8|| 003| 3|chemical| 63| 9|| 001| 1|language| 100| 1|| 002| 2|language| 87| 2|+------+-----+--------+-----+----+only showing top 20 rows
四、Lead和 Lag函数
lag和lead函数可以在同一次查询中取出同一字段的前N行数据(lag)和后N行数据(lead)。
lead和lag函数应用场景较为广泛,在计算前一天、前一个月以及后一天、后一个月等时间差时,我们通常会使用自连接来求差值,但是自连接有时候会出现重
复需要额外处理,而通过lag和lead函数正好能够实现这一功能。
4.1 Lead-后一行
语法:LEAD ( scalar_expression [ ,offset ] , [ default ] ) OVER ( [ partition_by_clause ] order_by_clause )
scalar_expression,要返回的值基于指定的偏移量。这是一个返回单个(标量)值的任何类型的表达式。scalar_expression 不能为分析函数。简单地
来说就是,要取的列。
offset默认值为1, offset 可以是列、子查询或其他求值为正整数的表达式,或者可隐式转换为bigint。offset 不能是负数值或分析函数。简单地来说就
是,取偏移后的第几行数据
default默认值为NULL, offset 可以是列、子查询或其他求值为正整数的表达式,或者可隐式转换为bigint。offset不能是负数值或分析函数。简单地来
说就是,没有符合条件的默认值
4.2 Lag-前一行
语法:Lag ( scalar_expression [ ,offset ] , [ default ] ) OVER ( [ partition_by_clause ] order_by_clause )
test_lead_lag=spark.sql("""select *,lead(grade)over(partition by number order by grade desc) lead_grade,lag(grade)over(partition by number order by grade desc) lag_gradefrom test_long_temp_table""")test_lead_lag.show()number|class| subject|grade|lead_grade|lag_grade|+------+-----+--------+-----+----------+---------+| 009| 2| physic| 98| 87| null|| 009| 2| english| 87| 72| 98|| 009| 2| math| 72| 64| 87|| 009| 2|chemical| 64| 63| 72|| 009| 2|language| 63| null| 64|| 006| 3|chemical| 99| 85| null|| 006| 3| english| 85| 84| 99|| 006| 3|language| 84| 82| 85|| 006| 3| math| 82| 73| 84|| 006| 3| physic| 73| null| 82|| 003| 3| math| 91| 89| null|| 003| 3| physic| 89| 86| 91|| 003| 3|language| 86| 83| 89|| 003| 3| english| 83| 63| 86|| 003| 3|chemical| 63| null| 83|| 005| 1|chemical| 98| 89| null|| 005| 1| english| 89| 81| 98|| 005| 1| physic| 81| 76| 89|| 005| 1|language| 76| 62| 81|| 005| 1| math| 62| null| 76|+------+-----+--------+-----+----------+---------+only showing top 20 rows
五、分页思想
SQL查询语句中的limit 与 offset 的区别:
limit y 分句表示: 读取 y 条数据
limit x, y 分句表示: 跳过 x 条数据,读取 y 条数据
limit y offset x 分句表示: 跳过 x 条数据,读取 y 条数据
看下面例子:
selete * from testtable limit 0, 20; selete * from testtable limit 20 offset 0; 第2页: 从第20个开始,获取20条数据
selete * from testtable limit 20, 20; selete * from testtable limit 20 offset 20; 第3页: 从第40个开始,获取20条数据
selete * from testtable limit 40, 20; selete * from testtable limit 20 offset 40;
下面在看几个leetcode上的题目:
--求第二高的薪水
首先先将数据去重:
SELECT DISTINCT Salary FROM Employee
再将是数据按薪水降序排除:
SELECT DISTINCT Salary FROM Employee ORDER BY Salary DESC
分页的思想是一页一条数据,第二高的薪水则在第二页:
SELECT DISTINCT Salary FROM Employee ORDER BY Salary DESC LIMIT 1, 1
考虑到极端情况:没有第二薪水则为空,使用ifnull判断:
SELECT IFNULL( (SELECT DISTINCT Salary FROM Employee ORDER BY Salary DESC
End.
作者:数据万花筒
本文为转载分享,如果涉及作品、版权和其他问题,请联系我们第一时间删除(微信号:lovedata0520)
更多文章前往首页浏览http://www.itongji.cn/
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论