
由于笔者所在的新浪微舆情是一家社会化大数据领域的语义分析公司,近期从数据分析岗转到数据产品岗后,不可避免的涉及到许多大数据语义分析的实际应用场景。由此,笔者将工作中的若干心得,以实际案例的形式进行呈现,涉及从数据采集、数据清洗、数据分析再到数据可视化的一整套流程分析,力求条理清晰的展现外部数据分析的强大威力。以下是本文的写作框架:
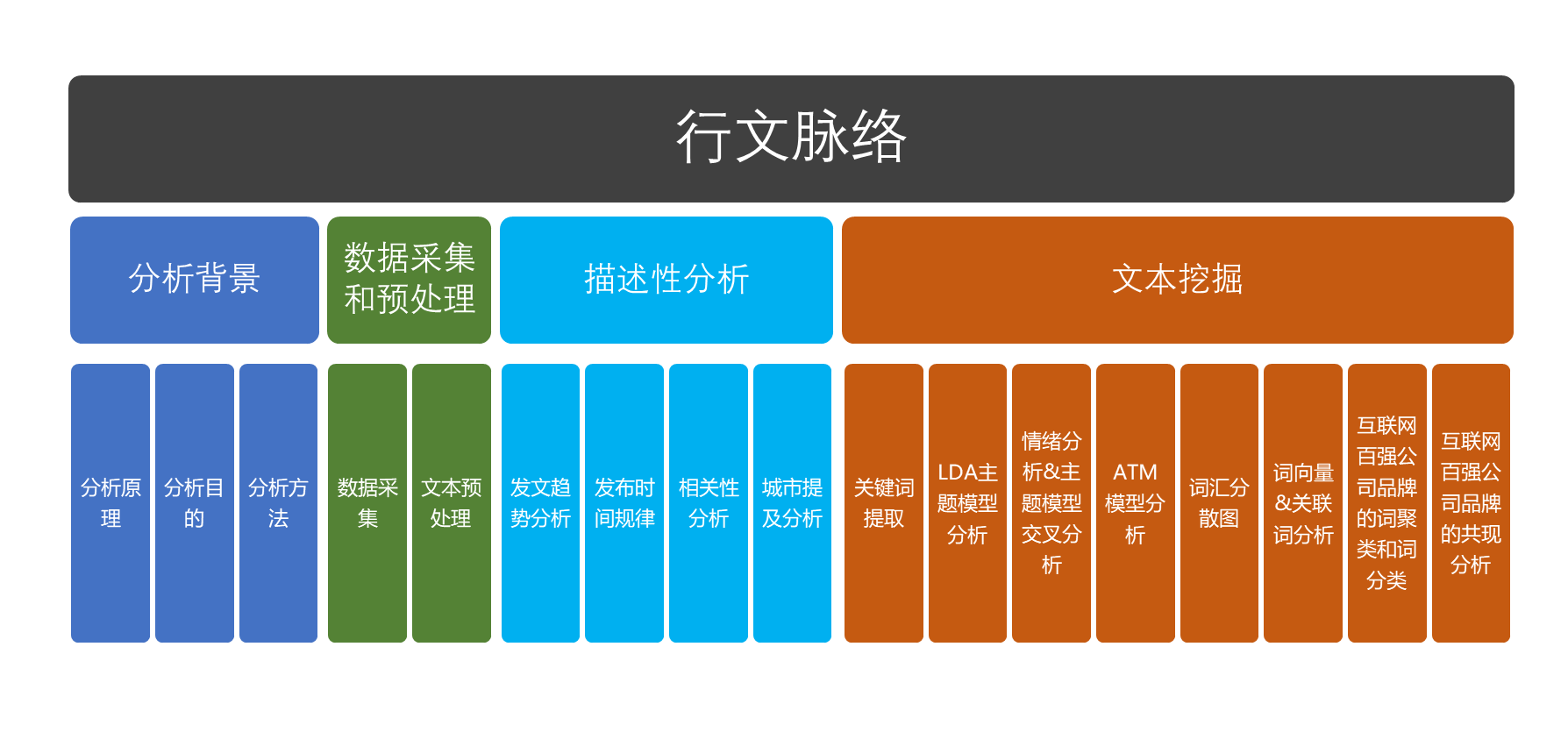
一、分析背景
1.1 分析原理:为什么选择分析虎嗅网
在现今数据爆炸、信息质量良莠不齐的互联网时代,我们无时无刻不身处在互联网社会化媒体的"信息洪流"之中,因而无可避免的被它上面泛滥的信息所"裹挟",也就是说,社会化媒体上的信息对现实世界中的每个人都有重大影响,社会化媒体是我们间接了解现实客观世界和主观世界的一面窗户,我们每时每刻都在受到它的影响。关于"社会化媒体"方面的内容,请参看《干货|如何利用Social Listening从社会化媒体中"提炼"有价值的信息?》,以下内容也摘自该文:
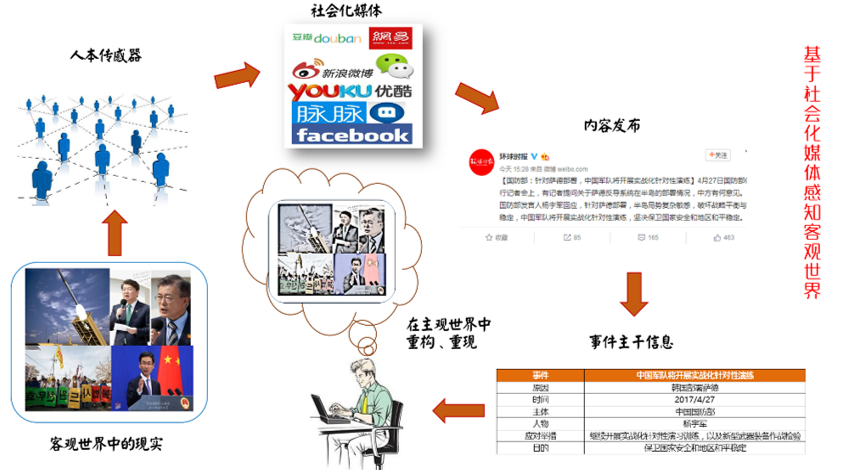
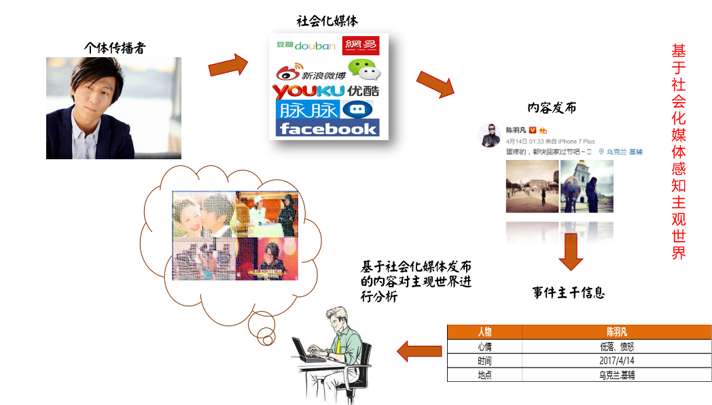
综合上述两类情形,可以得出这样的结论,透过社会化媒体,我们可以观察现实世界:

由此,社会化媒体是现实主客观世界的一面镜子,而它也会进一步影响人们的行为,如果我们对该领域中的优质媒体所发布的信息进行分析,除了可以了解该领域的发展进程和现状,还可以对该领域的人群行为进行一定程度的预判。
鉴于此种情况,作为互联网从业者的笔者想分析一下互联网行业的一些现状,第一步是找到在互联网界有着重要影响力媒体。
虎嗅网创办于2012年5月,是一个聚合优质创新信息与人群的新媒体平台。该平台专注于贡献原创、深度、犀利优质的商业资讯,围绕创新创业的观点进行剖析与交流。虎嗅网的核心,是关注互联网及传统产业的融合、一系列明星公司(包括公众公司与创业型企业)的起落轨迹、产业潮汐的动力与趋势。
因此,对该平台上的发布内容进行分析,对于研究互联网的发展进程和现状有一定的实际价值。
1.2 本文的分析目的
笔者在本项目中的分析目的主要有4个:
(1)对虎嗅网内容运营方面的若干分析,主要是对发文量、收藏量、评论量等方面的描述性分析;
(2)通过文本分析,对互联网行业的一些人、企业和细分领域进行趣味性的分析;
(3)展现文本挖掘在数据分析领域的实用价值;
(4)将杂芜无序的结构化数据和非结构化数据进行可视化,展现数据之美。
1.3 分析方法:分析工具和分析类型
本文中,笔者使用的数据分析工具如下:
- Python3.5.2(编程语言)
- Gensim(词向量、主题模型)
- Scikit-Learn(聚类和分类)
- Keras(深度学习框架)
- Tensorflow(深度学习框架)
- Jieba(分词和关键词提取)
- Excel(可视化)
- Seaborn(可视化)
- 新浪微舆情(情绪语义分析)
- Bokeh(可视化)
- Gephi(网络可视化)
- Plotly(可视化)
使用上述数据分析工具,笔者将进行2类数据分析:第一类是较为传统的、针对数值型数据的描述下统计分析,如阅读量、收藏量等在时间维度上的分布;另一类是本文的重头戏—深层次的文本挖掘,包括关键词提取、文章内容LDA主题模型分析、词向量/关联词分析、ATM模型、词汇分散图和词聚类分析。
二、 数据采集和文本预处理
2.1 数据采集
笔者使用爬虫采集了来自虎嗅网主页的文章(并不是全部的文章,但展示在主页的信息是主编精挑细选的,很具代表性),数据采集的时间区间为2012.05~2017.11,共计41,121篇。采集的字段为文章标题、发布时间、收藏量、评论量、正文内容、作者名称、作者自我简介、作者发文量,然后笔者人工提取4个特征,主要是时间特征(时点和周几)和内容长度特征(标题字数和文章字数),最终得到的数据如下图所示:

2.2 数据预处理
数据分析/挖掘领域有一条金科玉律:"Garbage in, Garbage out",做好数据预处理,对于取得理想的分析结果来说是至关重要的。本文的数据规整主要是对文本数据进行清洗,处理的条目如下:
(1)文本分词
要进行文本挖掘,分词是最为关键的一步,它直接影响后续的分析结果。笔者使用jieba来对文本进行分词处理,它有3类分词模式,即全模式、精确模式、搜索引擎模式:
- 精确模式:试图将句子最精确地切开,适合文本分析;
- 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
现以"新浪微舆情专注于社会化大数据的场景化应用"为例,3种分词模式的结果如下:
- 【全模式】: 新浪/ 微舆情/ 新浪微舆情/ 专注/于/ 社会化/ 大数据/ 社会化大数据/ 的/ 场景化/ 应用
- 【精确模式】: 新浪微舆情/ 专注/于/ 社会化大数据/ 的/ 场景化/ 应用
- 【搜索引擎模式】:新浪,微舆情,新浪微舆情,专注,于,社会化,大数据,社会化大数据,的,场景化,应用
为了避免歧义和切出符合预期效果的词汇,笔者采取的是精确(分词)模式。
(2) 去停用词
这里的去停用词包括以下三类:
- 标点符号:, 。! /、*+-
- 特殊符号:❤❥웃유♋☮✌☏☢☠✔☑♚▲♪等
- 无意义的虚词:"the"、"a"、"an"、"that"、"你"、"我"、"他们"、"想要"、"打开"、"可以"等
(3) 去掉高频词、稀有词和计算Bigrams
去掉高频词、稀有词是针对后续的主题模型(LDA、ATM)时使用的,主要是为了排除对区隔主题意义不大的词汇,最终得到类似于停用词的效果。
Bigrams是为了自动探测出文本中的新词,基于词汇之间的共现关系—如果两个词经常一起毗邻出现,那么这两个词可以结合成一个新词,比如"数据"、"产品经理"经常一起出现在不同的段落里,那么,"数据_产品经理"则是二者合成出来的新词,只不过二者之间包含着下划线。
三、描述性分析
该部分中,笔者主要对数值型数据进行描述性的统计分析,它属于较为常规的数据分析,能揭示出一些问题,做到知其然,关于数据分析的4种类型,详情请参看《干货|作为一个合格的"增长黑客",你还得重视外部数据的分析!》的第一部分。
3.1 发文数量、评论量和收藏量的变化走势
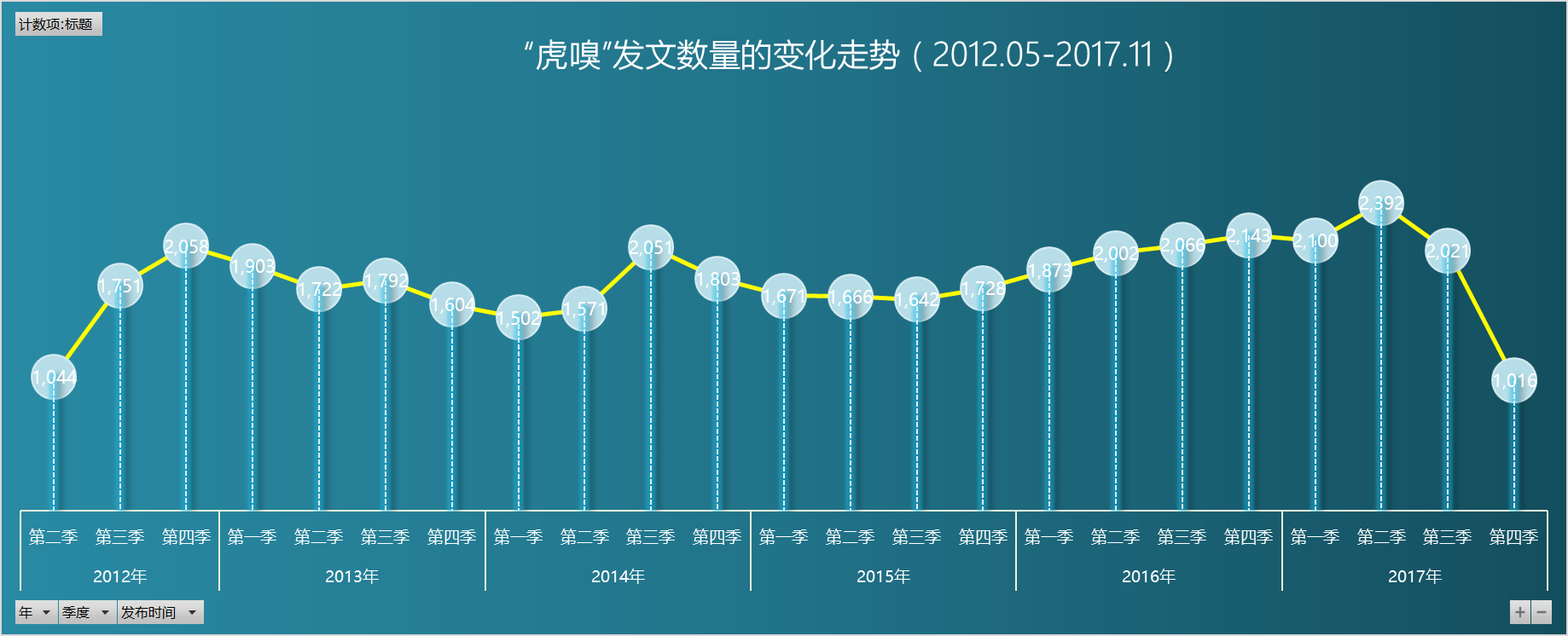
从下图可以看出,在2012.05~2017.11期间,以季度为单位,主页的发文数量起伏波动不大,在均值1800上下波动,进入2016年后,发文数量有明显提升。
此外,一头(2012年第二季)一尾(2017年第四季)因为没有统计完全,所以发文数量较小。
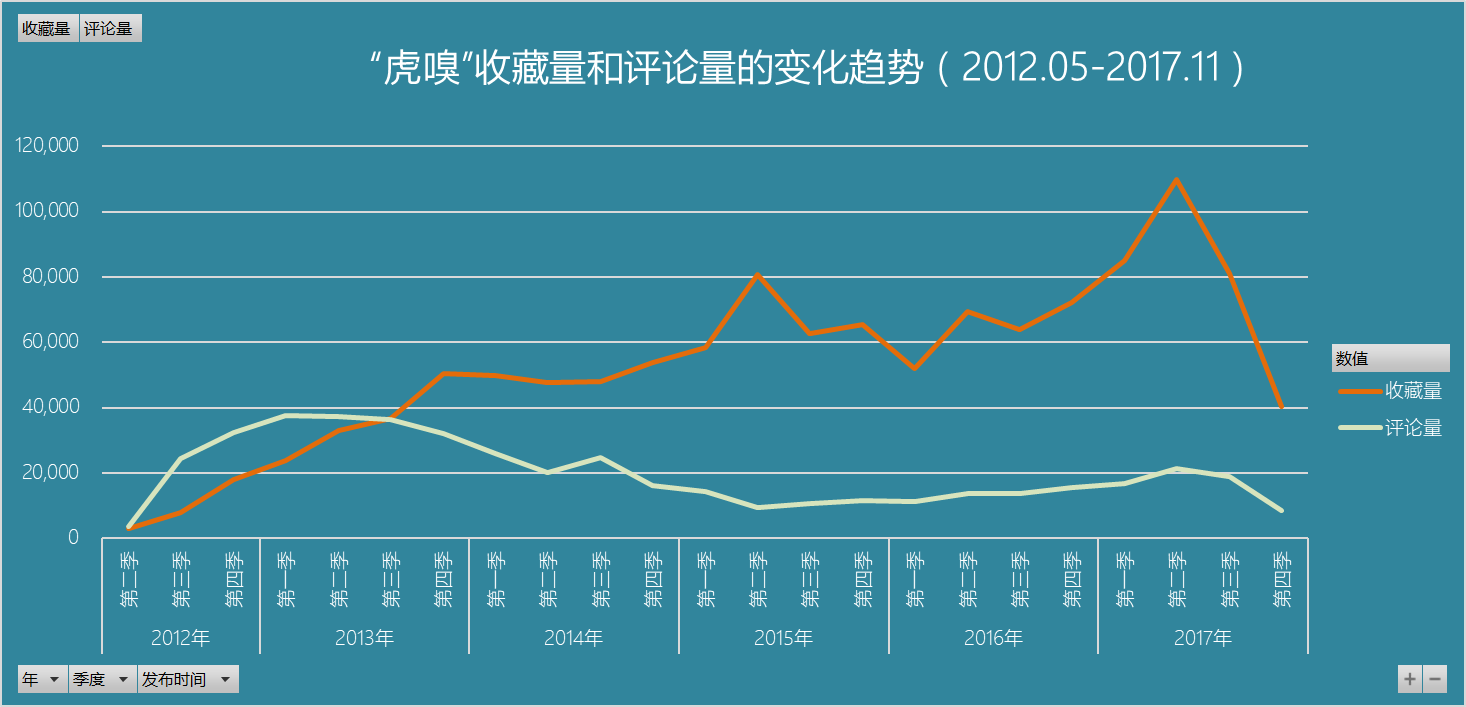
下图则是该时间段内收藏量和评论量的变化情况,评论量的变化不愠不火,起伏不大,但收藏量一直在攀升中,尤其是在2017年的第二季达到峰值。收藏量在一定程度上反映了文章的干货程度和价值性,读者认为有价值的文章才会去保留和收藏,反复阅读,含英咀华,这说明虎嗅的文章质量在不断提高,或读者的数量在增长。
3.2 发文时间规律分析
笔者从时间维度里提取出"周"和"时段"的信息,也就是开题提到的"人工特征"的提取,现在做文章分布数量的在"周"和"时"上的交叉分析,得到下图:
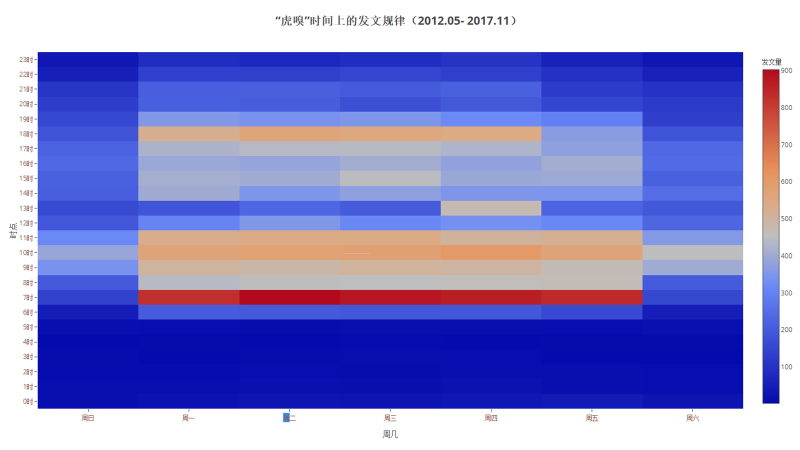
上图是一个热力图,色块颜色上的由暖到冷表征数值的由大变小。很明显的可以看到,中间有一个颜色很明显的区域,即由"6时~19时"和"周一~周五"围成的矩形,也就是说,发文时间主要集中在工作日的白天。另外,周一到周五期间,6时~7时这个时间段是发文的高峰,说明虎嗅的内容运营人员倾向于在工作日的清晨发布文章,这也符合它的人群定位—TMT领域从业、创业者、投资人,他们中的许多人有晨读的习惯,喜欢在赶地铁、坐公交的过程中阅读虎嗅讯息。发文高峰还有9时-11时这个高峰,是为了提前应对读者午休时间的阅读,还有17时~18时,提前应对读者下班时间的阅读。
3.3 相关性分析
笔者一直很好奇,文章的评论量、收藏量和标题字数、文章字数是否存在统计学意义上的相关性关系。基于此,笔者绘制出能反映上述变量关系的两张图。
首先,笔者做出了标题字数、文章字数和评论量之间的气泡图(圆形的气泡被六角星替代,但本质上还是气泡图)。
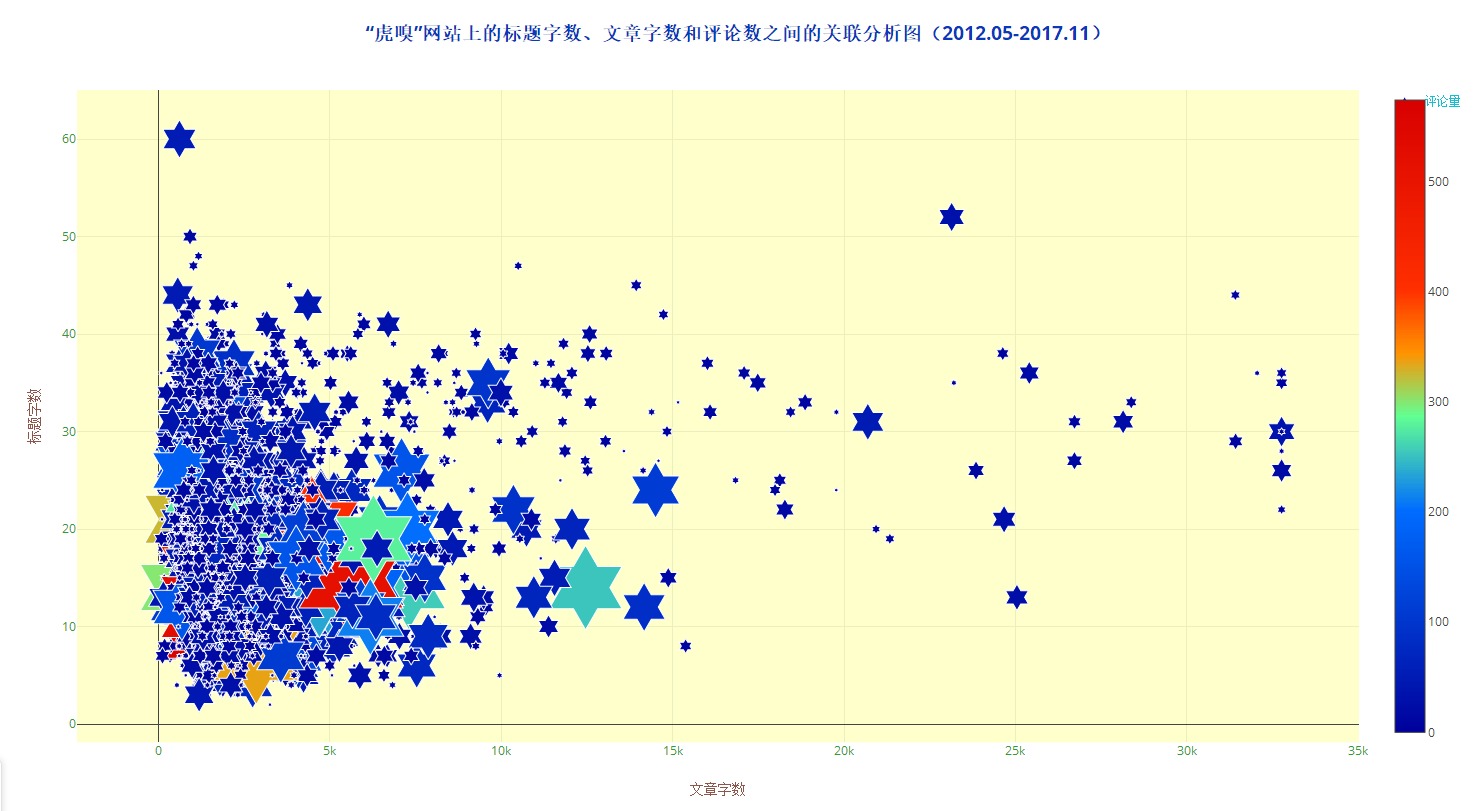
上图中,横轴是文章字数,纵轴是标题字数,评论数大小由六角星的大小和颜色所反映,颜色越暖,数值越大,五角星越大,数值越大。从这张图可以看出,文章评论量较大的文章,绝大部分分布于由文章字数6000字、标题字数20字所构成的区域内。虎嗅网上的商业资讯文章大都具有原创、深度的特点,文章篇幅中长,意味着能把事情背后的来龙去脉论述清楚,而且标题要能够吸引人,引发读者的大量阅读,合适长度标题和正文篇幅才能做到这一点。
接下来,笔者将收藏量、评论量和标题字数、文章字数绘制成一张3D立体图,X轴和Y轴分别为标题字数和正文字数,Z轴为收藏量和评论量所构成的平面,通过旋转这个3维的Surface图,我们可以发现收藏量、评论量和标题字数、文章字数之间的相关关系。
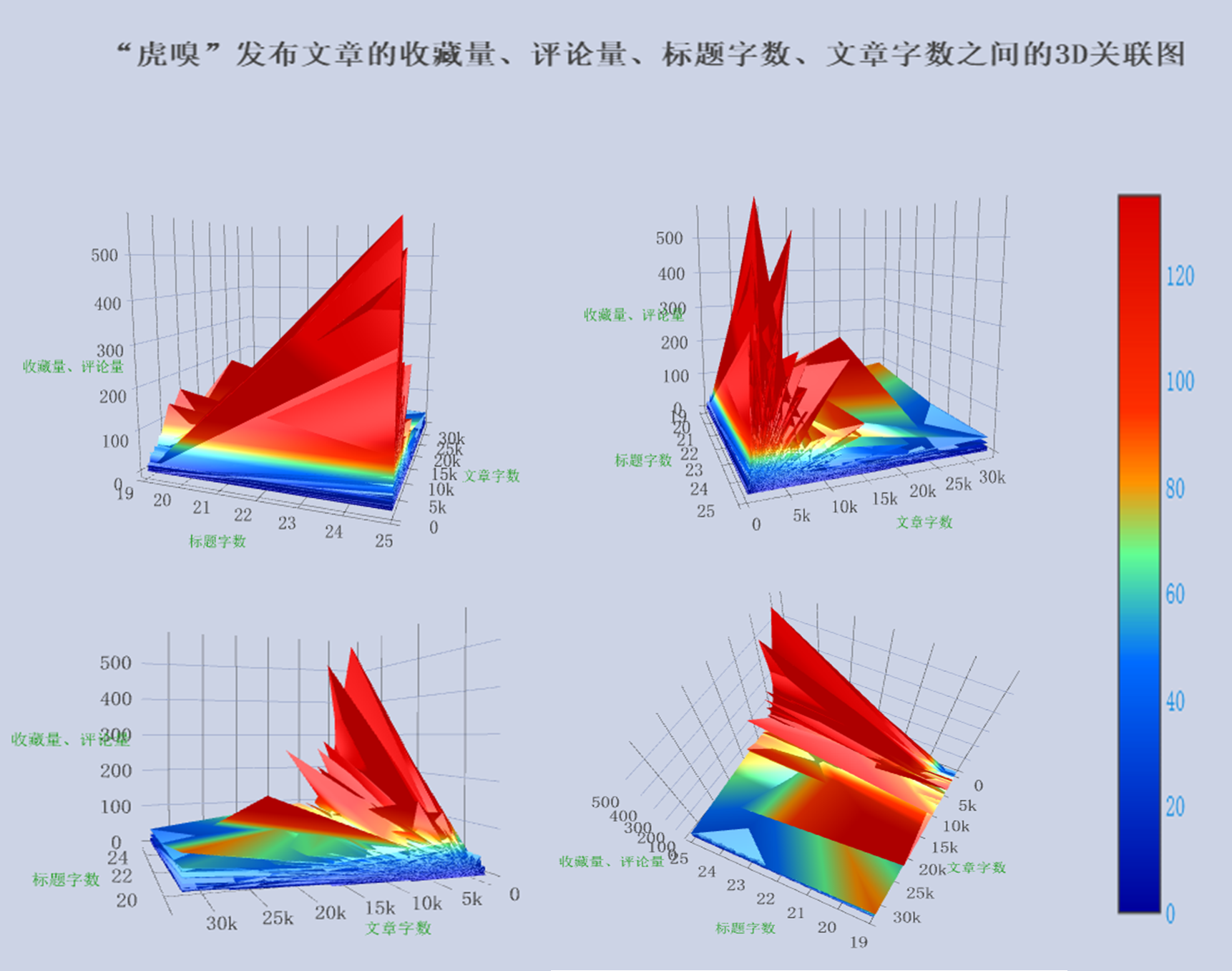
注意,上图的数值表示和前面几张图一样,颜色上的由暖到冷表示数值的由大到小,通过旋转各维度的截面,可以看到在正文字数5000字以内、标题字数15字左右的收藏量和评论量形成的截面出现"华山式"陡峰,因而这里的收藏量和评论量最大。
3.4 城市提及分析
在这里,笔者通过构建一个包含全国1~5线城市的词表,提取出经过预处理后的文本中的城市名称,根据提及频次的大小,绘制出一张反映城市提及频次的地理分布地图,进而间接地了解各个城市互联网的发展状况(一般城市的提及跟互联网产业、产品和职位信息挂钩,能在一定程度上反映该城市互联网行业的发展态势)。
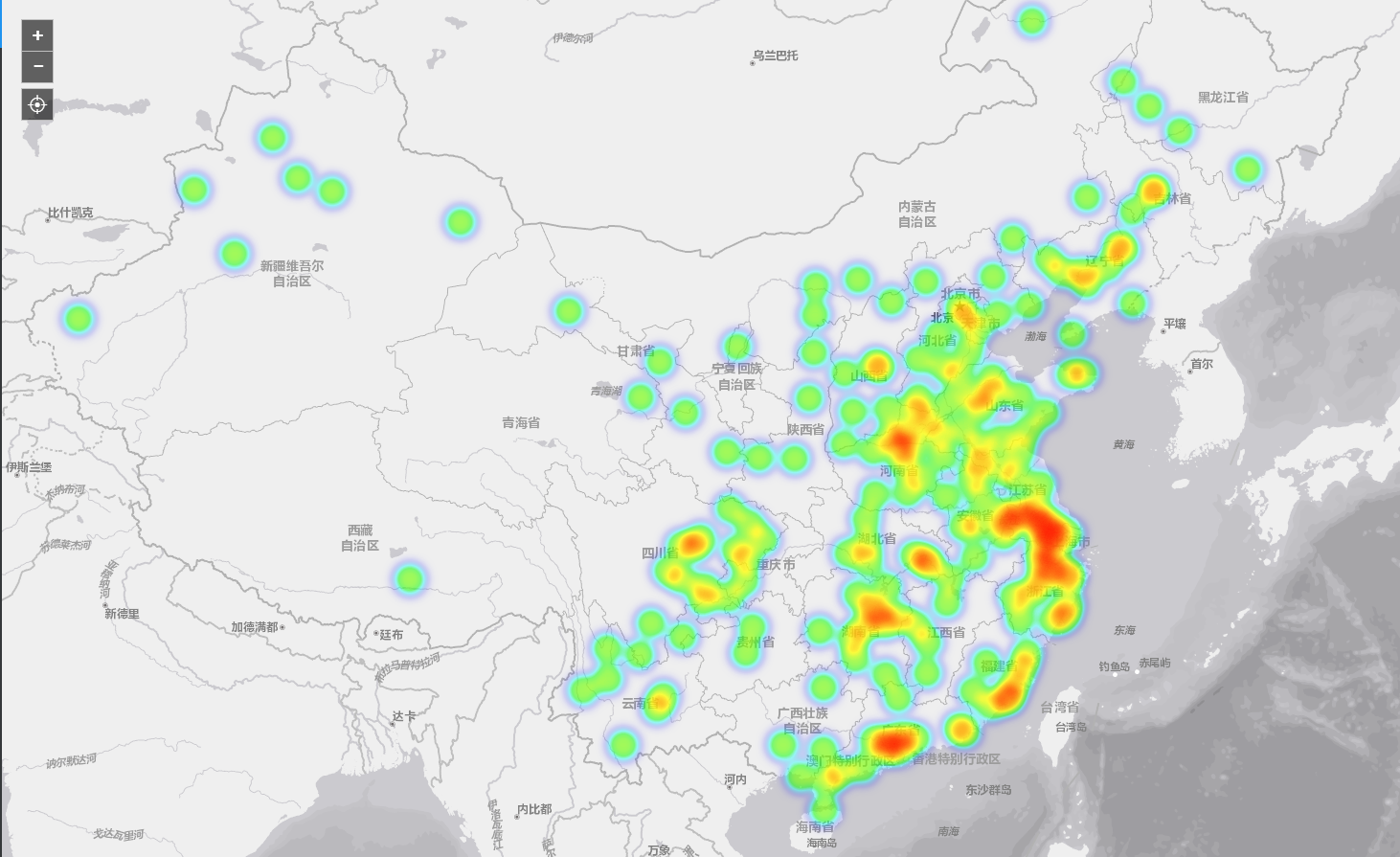
上图反映的结果比较符合常识,北上深广杭这些一线城市的提及次数最多,它们是互联网行业发展的重镇。值得注意的是,长三角地区的大块区域(长江三角洲城市群,它包含上海,江苏省的南京、无锡、常州、苏州、南通、盐城、扬州、镇江、泰州,浙江省的杭州、宁波、嘉兴、湖州、绍兴、金华、舟山、台州,安徽省的合肥、芜湖、马鞍山、铜陵、安庆、滁州、池州、宣城)呈现出较高的热度值,直接说明这些城市在虎嗅网各类资讯文章中的提及次数较多,结合国家政策和地区因素,可以这样理解地图中反映的这个事实:
长三角城市群是"一带一路"与长江经济带的重要交汇地带,在中国国家现代化建设大局和全方位开放格局中具有举足轻重的战略地位。中国参与国际竞争的重要平台、经济社会发展的重要引擎,是长江经济带的引领发展区,是中国城镇化基础最好的地区之一。
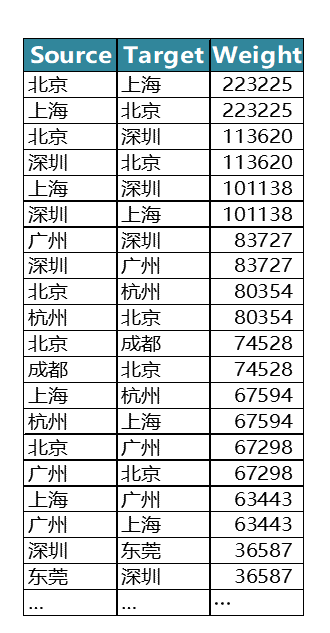
接下来,笔者将抽取文本中城市之间的共现关系,也就是城市之间两两同时出现的频率,在一定程度上反映出城市间经济、文化、政策等方面的相关关系,共现频次越高,说明二者之间的联系紧密程度越高,抽取出的结果如下表所示:
将上述结果绘制成如下动态的流向图:
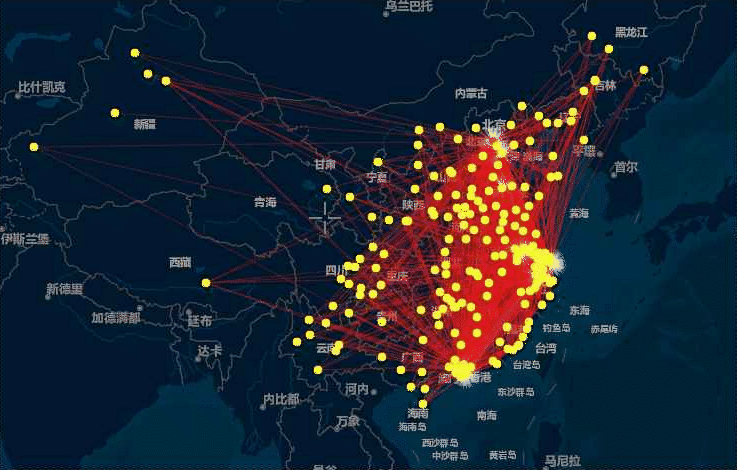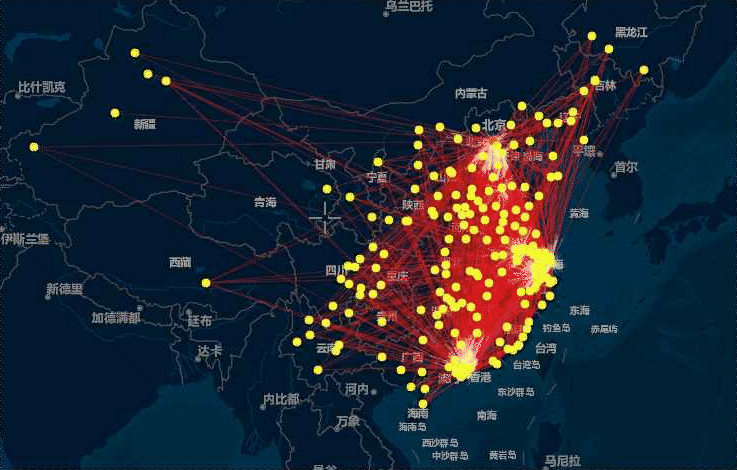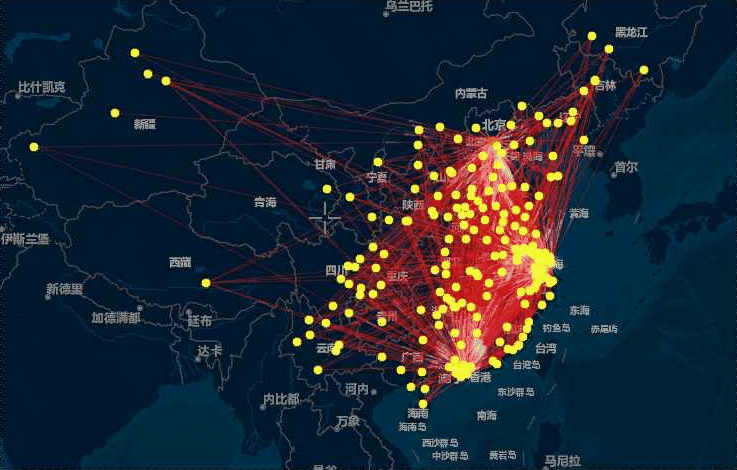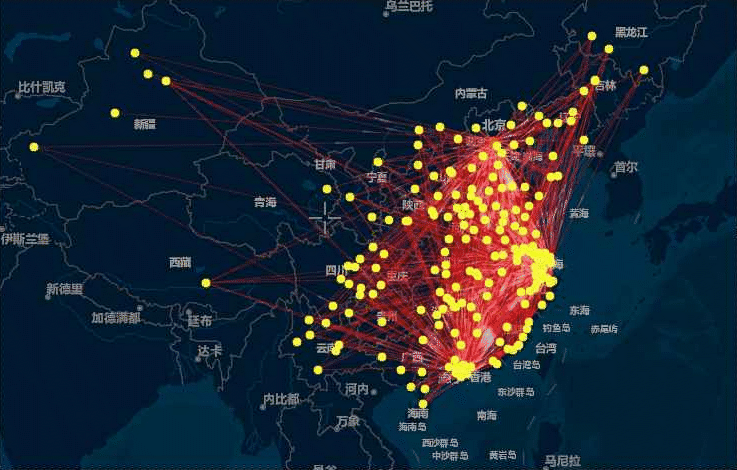
由于虎嗅网上的文章大多涉及创业、政策、商业方面的内容,因而这种城市之间的共现关系反映出城际间在资源、人员或者行业方面的关联关系,本动态图中,主要反映的是北上广深杭(网络中的枢纽节点)之间的相互流动关系和这几个一线城市向中西部城市的单向流动情形。流动量大、交错密集的区域无疑是中国最发达的3个城市群和其他几个新兴的城市群:
- 京津冀城市群
- 长江三角洲城市群
- 珠江三角洲城市群
- 中原城市群
- 成渝城市群
- 长江中游城市群
上面的数据分析是基于数值型数据的描述性分析,接下来,笔者将进行更为深入的文本挖掘。
End.
作者:海阁
本文为转载分享,如果涉及作品、版权和其他问题,请联系我们第一时间删除(微信号:lovedata0520)
更多文章前往首页浏览http://www.itongji.cn/
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论