
一、
你好,我是林骥。
水平方向的条形图非常适合阅读,因为文字的方向通常也是水平的,这符合我们的阅读习惯,有利于提高信息传递的效率,特别是当类别名称很长的时候。
比如说,对某产品的不同功能进行用户满意度调查,经过统计汇总,得到的满意度数据如下:
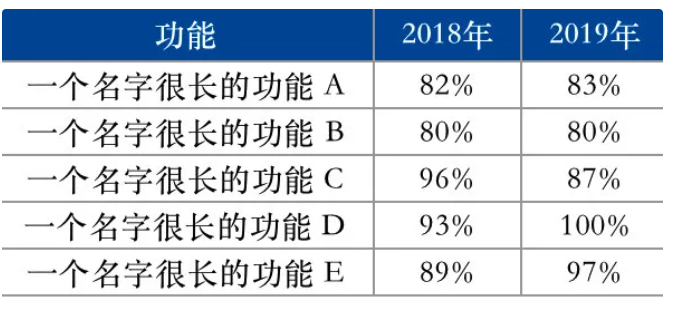
对于这组数据,我们可以用条形图来进行对比分析,效果图如下:
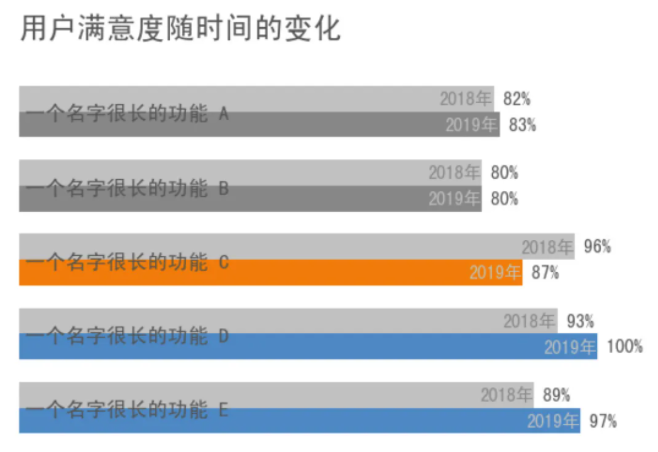
在这张图中,2018 年的数据统一用浅灰色表示,对于 2019 年的数据,用橙色代表用户满意度明显下降,用蓝色代表用户满意度明显提升,用灰色代表用户满意度变化不大,以便观众快速抓住重点信息。
二、
下面是用 matplotlib 画图的方法。
首先,导入所需的库,并设置中文字体和定义颜色等。
# 导入所需的库import numpy as npimport pandas as pdimport matplotlib as mplimport matplotlib.pyplot as pltimport matplotlib.image as image# 正常显示中文标签mpl.rcParams["font.sans-serif"] = ["SimHei"]# 自动适应布局mpl.rcParams.update({"figure.autolayout": True})# 正常显示负号mpl.rcParams["axes.unicode_minus"] = False# 定义颜色,主色:蓝色,辅助色:灰色,互补色:橙色c = {"蓝色":"#00589F", "深蓝色":"#003867", "浅蓝色":"#5D9BCF","灰色":"#999999", "深灰色":"#666666", "浅灰色":"#CCCCCC","橙色":"#F68F00", "深橙色":"#A05D00", "浅橙色":"#FBC171"}
其次,从 Excel 文件中读取随机模拟的数据,并定义画图用的数据。
# 数据源路径filepath="./data/问卷调查结果2.xlsx"# 读取 Excel文件df = pd.read_excel(filepath, index_col="功能")# 定义画图用的数据category_names = df.indexlabels = df.columnsdata = df.values
接下来,开始用「面向对象」的方法进行画图。
# 使用「面向对象」的方法画图,定义图片的大小fig, ax=plt.subplots(figsize=(8, 6))# 设置背景颜色fig.set_facecolor("w")ax.set_facecolor("w")# 设置标题ax.text(0, -1, " 用户满意度随时间的变化", fontsize=26, ha="left", color=c["深灰色"])# 设置 X 轴的取值范围ax.set_xlim(0, 1)# 倒转 Y 轴,让第一个功能排在最上面ax.invert_yaxis()# 定义颜色category_colors = [c["灰色"], c["灰色"], c["橙色"], c["浅蓝色"], c["浅蓝色"]]# 定义条形图所处的位置和高度x = np.arange(len(category_names))height = 0.35# 画条形图bar1 = ax.barh(x-height/2, data[:, 0], height, label=labels[0], color=c["浅灰色"])bar2 = ax.barh(x+height/2, data[:, 1], height, label=labels[1], color=category_colors)# 设置 Y 轴标签字体大小和颜色plt.yticks(range(len(category_names)), " " + category_names, ha="left", color=c["深灰色"], size=18)# ax.set_yticks(range(len(category_names)))# ax.set_yticklabels(category_names + " ")# ax.tick_params(labelsize=18, colors=c["深灰色"])# 设置标签的字体大小fontsize = 16# 设置第一个条形图的数据标签for (i, rect) in zip(range(len(bar1)), bar1):w = rect.get_width()ax.text(w, rect.get_y()+rect.get_height()/2, labels[0], ha="right", va="center", color=c["灰色"], fontsize=fontsize)ax.text(w, rect.get_y()+rect.get_height()/2, " %.0f%%" % (w*100), ha="left", va="center", color=c["深灰色"], fontsize=fontsize)# 设置第二个条形图的数据标签for rect in bar2:w = rect.get_width()ax.text(w, rect.get_y()+rect.get_height()/2, labels[1], ha="right", va="center", color=c["浅灰色"], fontsize=fontsize)ax.text(w, rect.get_y()+rect.get_height()/2, " %.0f%%" % (w*100), ha="left", va="center", color=c["深灰色"], fontsize=fontsize)# 隐藏 X 轴ax.xaxis.set_visible(False)# 隐藏边框ax.spines["top"].set_visible(False)ax.spines["right"].set_visible(False)ax.spines["left"].set_visible(False)ax.spines["bottom"].set_visible(False)# 隐藏 Y 轴的刻度线ax.tick_params(axis="y", which="major", length=0)plt.show()
你可以前往 https://github.com/linjiwx/mp 下载画图用的数据和完整代码。
三、
当你通过数据可视化来表达观点,首先自己要有一个清晰的结论,然后有针对性地突出自己想要表达的要点,通过视觉化的元素,引导观众正确地理解自己的观点,而不要让观众自行得出结论。
最后,分享一下我在知识星球上面发的关于分析数据的 5 点思考。
1. 分析数据的平均值和中位数
比如说,客户的年龄、购买金额的平均值和中位数分别是多少?中位数往往比平均值更具有分析价值。
2. 分析数据的极值和分布
比如说,在所有的购买者中,年龄最大的是谁?年龄最小的是谁?是否服从正态分布?
3. 分析数据的相关性
比如说,年龄与购买金额是否有相关性?相关系数是多少?
4. 分析数据背后的原因
比如说,客户为什么会购买?销售下降的原因是什么?
5. 提出数据分析的建议
比如说,经过前期的分析,知道销售下降的原因,主要是因为老年客户群体的认知度偏低,故提出建议:针对老年客户群体开展宣传活动。
总之,不要当一个纯粹的「统计者」,要做数据的分析者,最好是问题的解决者。
End.
爱数据网专栏作者:林骥
作者介绍:数据赋能者,专注数据分析 10 多年。
个人公众号:林骥(linjiwx)
本文为挖数网专栏作者原创文章,未经允许禁止转载,需要转载请微信联系授权(微信号:lovedata0520)
更多文章前往爱数据社区网站首页浏览http://www.itongji.cn/
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论