
一、序言
评价一个算法的好坏,我认为关键是看能不能解决问题。如果算法能很好地解决实际的问题,那么我认为就是好算法。 比如预测的算法,关键是看预测的准确率,即预测值与实际值之间的接近程度,而不是看算法本身的评分高低。
在《 如何用人工智能预测双 11 的交易额 》这篇文章中,利用线性回归算法,我预测 2019 年双 11 交易额为 2471 亿元,而阿里官方公布的实际交易额是 2684 亿元,预测值比实际值少 7.9%,对这个结果,我觉得准确率不够高。反思预测的过程,我认为可以从以下几个方面来进行改进。
二、样本
为了简化算法模型,我舍弃掉了前几年相对较小的数据,只保留了最近 5 年的数据。
在数据量本身就比较少的情况下,我仍然遵循简单原则,这无形中就加大了算法不稳定的风险,出现了欠拟合的问题。
尽管算法的评分很高,但是评分高并不代表算法就好。所以,样本的选择非常重要,不能单纯地追求算法的评分高,而忽略样本的质量。
三、算法
如果保留所有样本,那么显然数据呈现的规律并不是线性的,用多项式回归算法应该是个更好的选择。
假如用三次多项式回归算法进行预测,那么算法代码如下:
# 导入所需的库 import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression from sklearn.preprocessing import PolynomialFeatures from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler # 内嵌画图 %matplotlib inline # 设置正常显示中文标签 plt.rcParams["font.sans-serif"] = ["SimHei"] # 读取数据,在林骥的公众号后台回复「1111」 df = pd.read_excel("./data/1111.xlsx") # x 年份 x = np.array(df.iloc[:, 0]).reshape(-1, 1) # y 交易额 y = np.array(df.iloc[:, 1]) # z 预测的年份 z = [[2019]] # 用管道的方式调用多项式回归算法 poly_reg = Pipeline([ ("ploy", PolynomialFeatures(degree=3)), ("std_scaler", StandardScaler()), ("lin_reg", LinearRegression()) ]) poly_reg.fit(x, y) # 用算法进行预测 predict = poly_reg.predict(z) # 输出预测结果 print("预测 2019 年双 11 的交易额是", str(round(predict[0],0)), "亿元。") print("线性回归算法的评分:", poly_reg.score(x, y))
预测 2019 年双 11 的交易额是 2689.0 亿元。
线性回归算法的评分:0.99939752363314
下面是用 matplotlib 画图的代码:
# 将数据可视化,设置图像大小 fig = plt.figure(figsize=(10, 8)) ax = fig.add_subplot(111) # 绘制散点图 ax.scatter(x, y, color="#0085c3", s=100) ax.scatter(z, predict, color="#dc5034", marker="*", s=260) # 设置标签等 plt.xlabel("年份", fontsize=20) plt.ylabel("双 11 交易额", fontsize=20) plt.tick_params(labelsize=20) # 绘制预测的直线 x2 = np.concatenate([x, z]) y2 = poly_reg.predict(x2) plt.plot(x2, y2, "-", c="#7ab800") plt.title("用多项式回归预测双 11 的交易额", fontsize=26) plt.show()
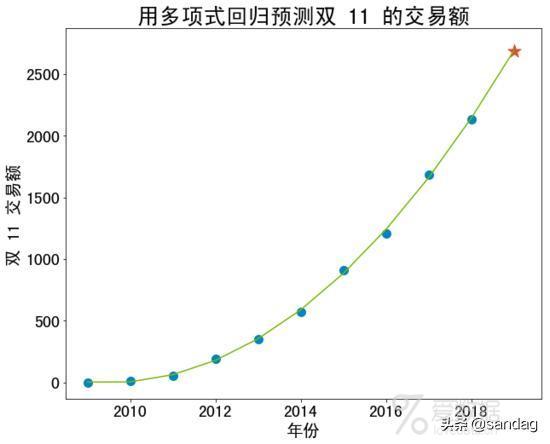
这近乎完美地拟合了 2009 年以来十一年的数据,因此不禁让人怀疑,阿里的数据是不是过于完美?
四、优化
按照一般的机器学习算法流程,应该把数据拆分为两部分,分别称为训练数据集和测试数据集。从 2009 年到 2018 年,双 11 的交易额总共才 10 个数据,我在预测的时候还舍弃了前 5 个数据,最后只剩下 5 个数据,我以为再拆分就没有必要了。 但机器学习算法的表现好坏,有一个关键因素,就是要有足够多的数据量。
另外,应该适当地使用网格搜索法,优化算法的参数,必要时还要与交叉验证法相结合,进行算法评估,从而提高算法的可信度和准确率。 除了算法的准确率,还可以使用其他的方法对模型进行评价,比如:召回率、F1 分数、ROC、AUC、MSE、RMSE、MAE 等等 。
现实世界是错综复杂的,很难用一个算法就解决问题,往往需要经过很多次的尝试,才可能找到基本符合的模型。需要注意的是,多项式回归的指数不宜过高,否则算法太复杂,很可能出现"过拟合"的现象,从而泛化能力比较差,也就是说,对于训练数据集能够很好地拟合,但是对于测试数据集的预测误差比较大。模型复杂度与预测误差的大致关系如下图所示:

End.
来源:今日头条
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论