
一.简介
FM是Steffen Rendle在2010年提出的,FM算法的核心在于特征组合,以此来减少人工参与特征组合工作。对于FM,其优势可分以下三点:
- FM能处理数据高度稀疏场景,SVM则不能;
- FM具有线性的计算复杂度,而SVM依赖于support vector。
- FM能够在任意的实数特征向量中生效。
二.FM原理
FM的数据结构如下:
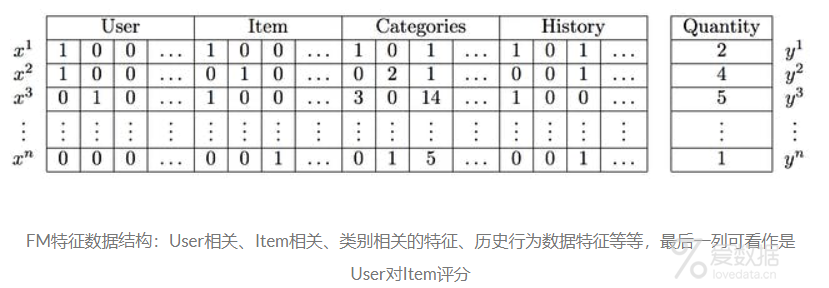
FM通过不同特征的组合,生成新的含义。然而,特征组合也随之带来一些问题:
- 特征之间两两组合容易导致维度灾难;
- 组合后的特征未必有效,可能存在特征冗余现象;
- 组合后特征样本非常稀疏,如果原始样本中不存在对应的组合,则无法学习参数,那么该组合就显得无效。
虽然有这些缺点,但是也并不影响FM在广告推荐领域的地位,每个算法都有风靡一时的过去,抱着敬畏之心的态度去学习是没问题的。下面,来看看FM的算法原理。
1.目标函数
我们知道,线性模型的目标函数为:
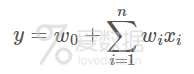






2.SGD训练参数
使用SGD进行训练,可以推导出SGD的参数更新方式:

三.实验
1.Windows下安装pyfm
pyfm install:将pyFM 下载到本地,解压后去掉setup.py文件里面的libraries=["m"]一行,然后采用python setup.py install安装即可.
2.分类模型
FM可以用来进行分类,为了方便,这里使用sklearn里面的iris数据集作为实验数据,将target等于2的作为正样本,其余作为负样本,并采用train_test_split方法划分训练集与测试集,然后通过FM构建分类模型,并通过测试集验证FM的效果。完整Demo代码如下(Github地址:pyfm_demo.py):
- # -*- coding: utf-8 -*-
- """
- Created on Sun Jan 27 23:49:24 2019
- @author: liudiwei
- """
- from sklearn.datasets import load_iris
- from sklearn.model_selection import train_test_split
- from pyfm import pylibfm
- from sklearn.feature_extraction import DictVectorizer
- def load_data():
- """
- 调用sklearn的iris数据集,筛选正负样本并构造切分训练测试数据集
- """
- iris_data = load_iris()
- X = iris_data["data"]
- y = iris_data["target"] == 2
- data = [ {v: k for k, v in dict(zip(i, range(len(i)))).items()} for i in X]
- X_train,X_test,y_train, y_test = train_test_split(data,y, test_size=0.3, random_state=0)
- return X_train,X_test,y_train, y_test
- X_train,X_test,y_train, y_test = load_data()
- v = DictVectorizer()
- X_train = v.fit_transform(X_train)
- X_test = v.transform(X_test)
- fm = pylibfm.FM(num_factors=2,
- num_iter=200,
- verbose=True,
- task="classification",
- initial_learning_rate=0.001,
- learning_rate_schedule="optimal")
- fm.fit(X_train, y_train)
- y_preds = fm.predict(X_test)
- y_preds_label = y_preds > 0.5
- from sklearn.metrics import log_loss,accuracy_score
- print ("Validation log loss: %.4f" % log_loss(y_test, y_preds))
- print ("accuracy: %.4f" % accuracy_score(y_test, y_preds_label))

3.实验结果
通过上面代码,跑出的结果如下(注:每次实验结果不一定相同):
- Training log loss: 0.12161
- Validation log loss: 0.1868
- accuracy: 0.9778
四.结束语
OK,关于FM的介绍暂且结束,FM的计算是比较耗内存的,特征维度超过100,两两组合之后,特征维度就达到1w+,维度增加带来的就是计算量的剧增,跑实验的话,还是需要硬件支撑的。所以也因此衍生出FFM算法(Field-aware FM),主要是对特征进行分组然后进行组合。关于FFM的细节,后续在补充吧!
五.References
- https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
- https://github.com/csuldw/MachineLearning/blob/master/Recommendation%20System/pyfm_demo.py
- http://www.libfm.org/libfm-1.42.manual.pdf
- http://d0evi1.com/libfm/
- http://ibayer.github.io/fastFM/guide.html
- http://www.tk4479.net/jiangda_0_0/article/details/77510029
End.
作者:拾毅者
来源:『刘帝伟』维护的个人技术博客
本文均已和作者授权,如转载请与作者联系。
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论