
统计学分为描述性统计学和推断性统计学
一、描述统计学
1.描述统计学简介
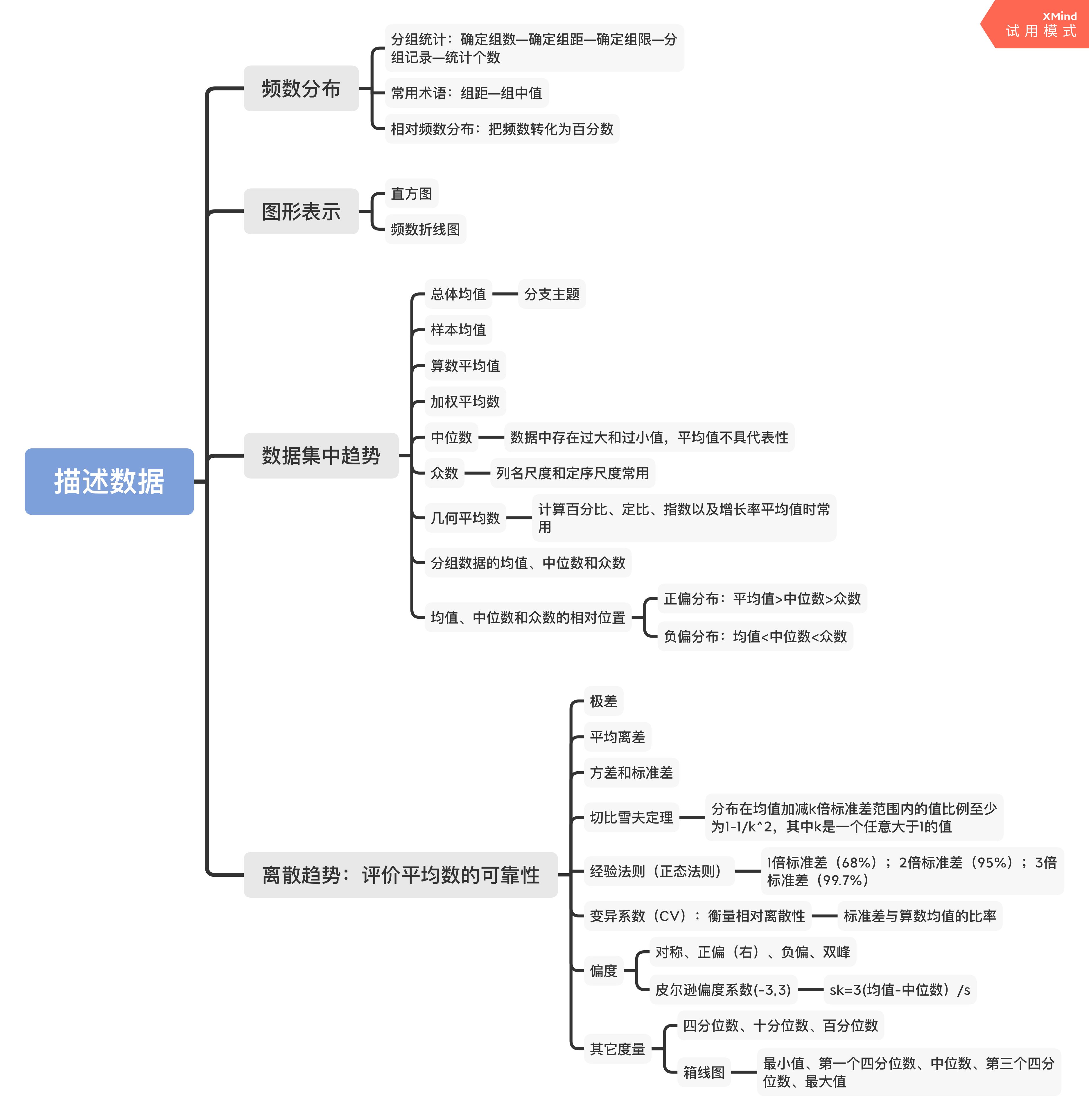
何为描述,"一双丹凤三角眼、两弯柳叶吊梢眉,身量苗条,体格风骚,粉面含春威不露,丹唇未启笑先闻。"这是曹先生对王熙凤的描述。和我们怎么评价一个人长什么模样一样,描述统计学是用来描述一组数据长什么样:最大值最小值是多少?平均数是多少?哪个数字出现最多?数据是集中的还是离散的?等等。我们在做数据分析的时候,需要在数据中发现规律,但这一个前提就是我们要知道这组数据长什么样。就像男生想要追求一个女孩子时,需要充分了解这个女孩子,才能对症下药、投其所好一样。常见的描述数据的方法如下:
2.抽样方法与中心极限定理
在我们检测一批药品合不合格的时候,我们不可能把所有的药盒都打开全都检查一遍确定是否合格,只能抽取部分检测,依据这部分药品的检测结果来推断全部药品的质量,这就是所谓的抽样方法。抽样就是为了检测整体而从整体中抽一个样本出来检测,以样本检测的结果来推断整体质量的一种方法。
我们在实际生活中需要利用抽样完成不同的目的,对于样本的要求也不一样,此时就需要不同的抽样方法。常见抽样方法如下:

3.抽取样本服从什么分布?
根据中心极限定理:若给定样本量的所有样本来自任意整体,则样本均值的抽样分布近似服从正态分布,且样本量越大,近似性越强。
当样本量大于30的时候符合中心极限定理,样本服从正态分布;当样本量小于30的时候,总体近似正态分布时,此时样本服从t分布。样本的分布形态决定了我们在假设检验中采用什么方法去检验它。
二、推断统计
1.基本步骤
推断统计顾名思义就是从样本特征推断总体的特征。而这个推断的过程即所谓的假设检验。这个过程首先需要明确问题是什么?然后确定证据是什么?判断标准是什么?最后做出结论。即对应假设检验的几个步骤:
1)提出原假设(H0)和备选假设(H1)
2)确定显著性水平(原假设为正确时,人们把它拒绝了的概率)
3)选择检验统计量
4)建立决策准则
5)下结论
知识点:P值的获取公式
样本标准差s:估计总体标准差


根据t值,查找t表格,得到P值
2.假设检验的三种类型
单样本检验:检验单个样本的平均值是否等于目标值
相关配对检验:检验相关或配对观测之差的平均值是否等于目标值
独立双样本检验:检验两个独立样本的平均值之差是否等于目标值
3.不同的统计检验方法
Z检验:Z检验是一般用于大样本(即样本容量大于30)平均值差异性检验的方法。它是用标准正态分布的理论来推断差异发生的概率,从而比较两个平均数>平均数的差异是否显著。
T检验:用于样本含量较小(例如n<30),总体标准差σ未知的正态分布样本。
F检验:F检验又叫方差齐性检验。在两样本t检验中要用到F检验。检验两个样本的方差是否有显著性差异 这是选择何种T检验(等方差双样本检验,异方差双样本检验)的前提条件。
(T检验用来检测数据的准确度,检测系统误差 ;F检验用来检测数据的精密度,检测偶然误差)
卡方检验:主要用于检验两个或两个以上样本率或构成比之间差别的显著性,也可检验两类事物之间是否存在一定的关系。
4.双尾检测和单尾检测
是双尾检测还是单尾检测与我们提出的原假设有关。比如说我们检测中国和日本人民的学历是否有差异,如果原假设是中国人学历=日本人学历,原假设成立需要拒绝两个可能,一是中国人学历大于日本人学历,二是日本人学历大于中国人学历,此时我们就需要进行双尾检验。而原假设如果是中国人学历大于日本人学历,原假设成立只需要拒绝一个可能,即中国人学历小于日本人学历,此时就需要进行单尾检验。
5.置信区间与置信水平
所谓的统计学,就是依据一个样本来推断总体。在推断过程中,我们或多或少会遇到一些干扰因素,最终推断的结果并不是一个确切的数字,取值会在一个范围里面,这个范围就是所谓的置信区间。
如果要保证总体的取值一定在一个置信区间里,那置信区间的存在也就没什么意义了,因为万事皆有可能,总体的数据可能是任何数,只是概率大不大的问题了,此时置信区间将是一个无尽的区间。所以需要加上置信水平的限制,置信水平给出了一个概率,即不要求百分之百的准确度,只要达到置信水平的标准就行了,我们常用的就是95%的置信水平。比如说95%的置信水平下的置信区间是[2,3],意思是有百分之95%的可能总体的值出现在[2,3]的区间内。
置信区间[a,b]的计算方法为:(z分数:由置信水平决定,查表得)
a = 样本均值 - z*标准误差
b = 样本均值 + z*标准误差
6.第一类错误和第二类错误
第一类错误是拒绝了实际正确的假设,第二类错误是接受了实际上不成立的假设。犯两类错误的主要影响因素是置信水平,当置信水平越高,即总体值均值落在置信区间的可能性越大,此时越不容易拒绝实际正确的假设,犯第一类的错误可能性就会变小,而犯第二类错误的可能性就会变大;而置信水平越低,越容易犯第一类错误,而不容易犯第二类错误。在实际中我们更怕犯第一类错误,所以会尽量设定高的置信水平。
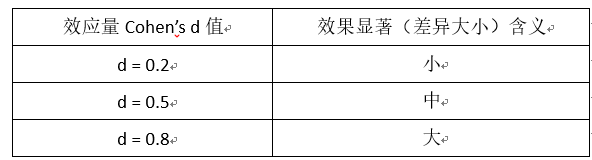
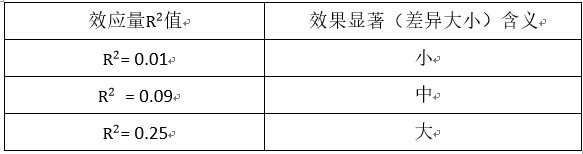
7.效应量
当我们通过假设检验得出结论,只能知道样本是否有差异,如果有差异的话,差异又有多大呢?效应量指标就是用来衡量效果显著性的指标,主要有两大类别。
差异指标:衡量两组数据的平均值差异

相关度指标:衡量某一指标与另一指标的关系

8.数据统计分析汇报格式
1)描述统计分析
描述两组数据的基本情况
2)推论统计分析
假设检验
假设检验APA格式:
t (df) = ×.xx, p = .xx (α=.xx),检验方向
置信区间
效应量
End.
作者:旧梦
本文为转载分享,如果涉及作品、版权和其他问题,请联系我们第一时间删除(微信号:lovedata0520)
更多文章前往首页浏览http://www.itongji.cn/
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论