
类别型字符串数据,建议优先定义为数字类型+名义测度,并添加相应的标签值。
先不着急解释这里面的概念,我们先来看一组大名鼎鼎数据。由统计学家Fisher收集整理的鸢尾花卉数据集,包含150个记录,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。如下:
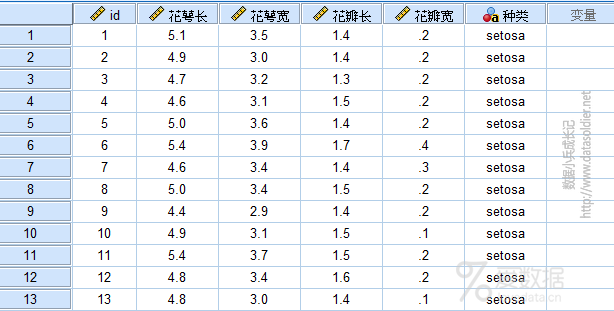
花萼长度,花萼宽度,花瓣长度,花瓣宽度4个变量呢,是具体的数字,可比较大小,可加减乘除,这类数据我们通常喜欢称之为连续型数值变量。定义为数字类型,标度测量方式,比较好理解。
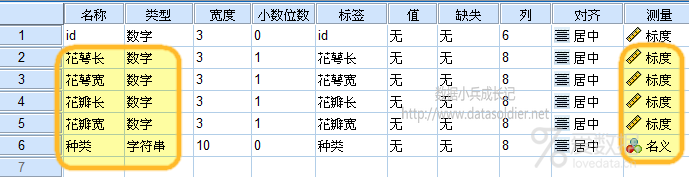
重点是【种类】变量,它首先是类别型的,有3个分类水平,分别是Setosa,Versicolour,Virginica,比如Setosa这属于字符串类型的数据,我把这类数据称作是类别型字符串数据。 比如我们我们有一个变量是省份,那全国有31个省份,它的具体取值是具体的省份名称,比如陕西省,河南省,我把这类数据称作是名义型的字符串数据。 现在的问题是,iris数据集中的种类变量,如何定义才合适呢?
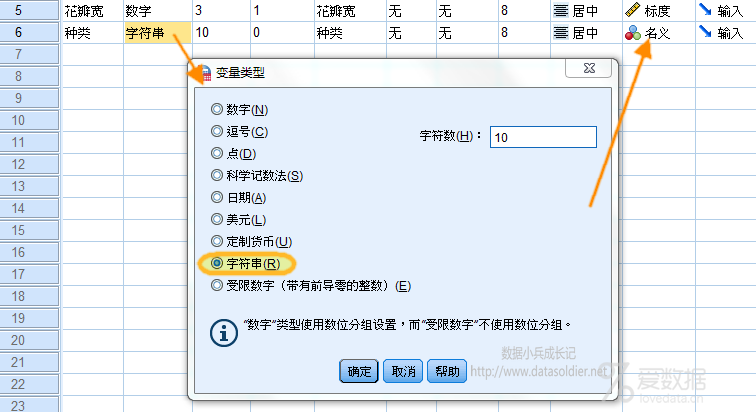
一部分读者会说,看菜下单,它取值有三Setosa,Versicolour,Virginica,均是字符串,那我们就把它定义为【字符串】类型,【名义】测量方式,试一下。 假设我们进行判别分析。看看会发生什么事故。
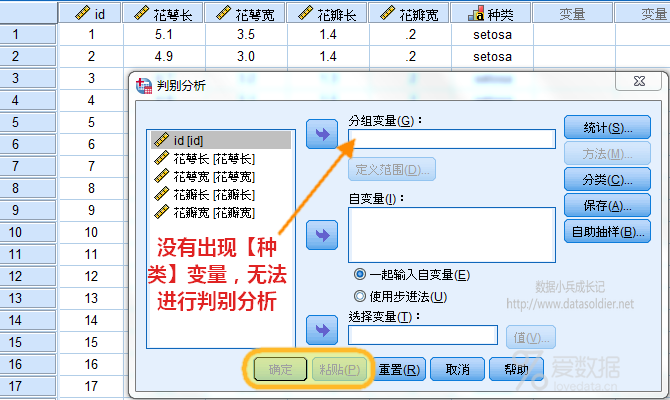
你会发现,被你定义为【字符串】类型的【种类】变量,根本就没有出现在待分析的变量列表中,判别分析需要【种类】这个变量,可是它现在完全找不到了。判别分析失败。 为什么会这样呢?问题就出在字符类型上,它不符合统计方法分析的需要。 那怎么办呢?定义为数字类型+名义测度,同时定义标签值属性,用数字1代表Setosa,用数字2代表Versicolour,用数字3代表Virginica。
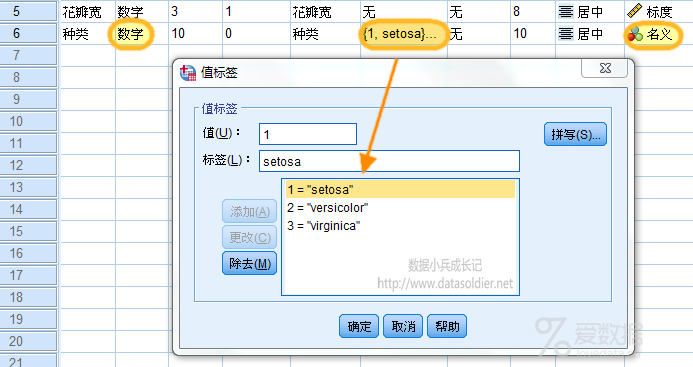
再用判别分析测试一下,ok,完全没毛病。这就是准确定义变量属性的重要性。
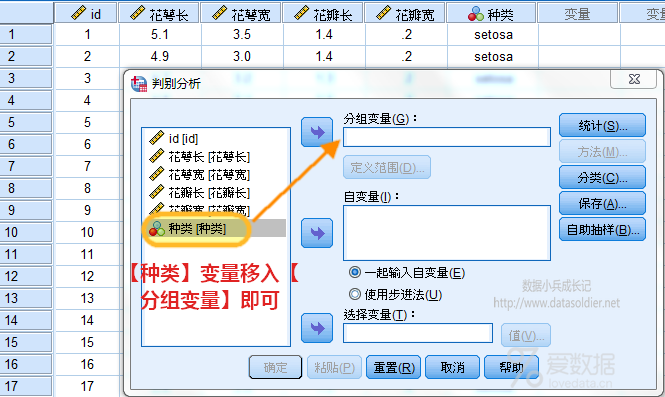
此案例,也可以提示大家,尽可能地定义和使用变量标签值。在SPSS软件中,这一操作十分方便而且好处多多。
End.作者:数据小兵来源:博客本文均已和作者授权,如转载请与作者联系。
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论